Preface
Three years ago, I wrote an article: Easy Understanding of AJAX and Cross-Origin Requests, which mentioned API integration, AJAX, same-origin policy, JSONP, and CORS. At that time, I put everything I wanted to say into it, but looking back now, it seems that many important parts were not mentioned.
Three years later, I am challenging this topic again and trying to express it more completely.
The reason why I want to write this series is that CORS is a frequently asked topic in programming-related discussion forums, and both front-end and back-end developers may ask related questions.
So I thought: “Okay, then I’ll write a series. I want to try to write this topic so that everyone who encounters CORS problems will come to see this series, and after reading it, they will know how to solve the problem.” This is my goal for this article. If the quality of the article cannot achieve this goal, I will continue to improve it.
This series consists of six articles:
- CORS Complete Guide (Part 1): Why CORS Errors Occur?
- CORS Complete Guide (Part 2): How to Solve CORS Problems?
- CORS Complete Guide (Part 3): CORS Detailed Explanation
- CORS Complete Guide (Part 4): Let’s Look at the Specification Together
- CORS Complete Guide (Part 5): Security Issues of Cross-Origin Requests
- CORS Complete Guide (Part 6): Summary, Afterword, and Leftovers
It will start from the same-origin policy, then talk about why there are errors when accessing resources across origins, and then talk about how to solve CORS-related problems correctly and incorrectly. The third article will explain in detail the detailed process of cross-origin requests, such as preflight requests.
The basic part is enough to read the first three articles, and the following will be a bit deeper. The fourth article will take you to look at the spec together, proving that the previous articles were not nonsense, and the fifth article will show you cross-origin-related regulations such as CORB (Cross-Origin Read Blocking), COEP (Cross-Origin Embedder Policy), or COOP (Cross-Origin-Opener-Policy), and related security issues. The last article will be some scattered topics and thoughts.
As the first article in the series, I want to take you to think about why there is a same-origin policy and why errors occur when accessing resources across origins. If you don’t know the answer to this question, then you usually don’t really understand what CORS is regulating, and it is likely that you will use some incorrect methods to solve this problem.
In this article, I assume that you already have some basic concepts of cross-origin requests and CORS. If you have no idea at all, you can refer to this article I wrote before: Easy Understanding of AJAX and Cross-Origin Requests.
Before starting, I want to tell you a little story related to the whole CORS, just treat it as a nonsense story. After understanding the whole cross-origin request-related things, you will know what this story represents.
The protagonist of the story is a small capitalist who is eager to learn and wants to obtain various information. The government wants to monitor these eager learners and try to know what information they have asked for. Therefore, they placed him in a small room, and all communication with the outside world had to go through the guard at the door.
So the small capitalist cannot go out in person, but he can ask the guard anything he wants to know. For each question asked by the small capitalist, the guard will help him ask the person concerned, but he may not tell him the answer. The government has established a procedure, which is “unless the person being asked explicitly agrees, the answer cannot be told to the small capitalist.” Therefore, the guard will first ask the question and get the answer, and then ask: “Do you want to let the small capitalist know about this?” Some people are willing, such as fast food restaurants. Although they don’t know the small capitalist at all, anyone can be told this kind of information. But some people are unwilling because they don’t know who the small capitalist is. There is also a situation where the guard doesn’t even need to ask, which is the small capitalist’s family. Because the small capitalist’s family is related by blood and has the same origin, they can be released without asking.
So, although every question from Xiaozhi was conveyed to the person being asked, they might not receive a reply. One day, Xiaozhi couldn’t stand being imprisoned like this anymore, so he came up with a few methods.
The first method was to knock down the guard and escape. Without the guard, he would be free to ask anyone any questions without any constraints.
The second method was to ask a friend to act as a go-between. Whenever Xiaozhi had a question, he would tell the guard, “Ask my friend how much a Big Mac costs,” and then the friend would go ask the fast food restaurant and tell the guard the result, while also letting the guard know that he was willing to let Xiaozhi know about this. Because all the questions would be relayed through his friend, and his friend would always let the guard know that Xiaozhi could know this information, Xiaozhi would not have the previous limitation.
The third method was to make everyone willing to tell him the information, so he would not be intercepted by the guard and could successfully find out the answers to his questions.
Okay, the story is over. Although I don’t think it’s very relevant, exaggerated stories always attract more attention, so let’s leave it at that and move on to the topic.
Starting from familiar error messages
I believe everyone is familiar with this error message:
request has been blocked by CORS policy: No ‘Access-Control-Allow-Origin’ header is present on the requested resource.
When using XMLHttpRequest or fetch in the frontend, you should have encountered this error. When connecting to the backend or an API on the internet, you can’t connect, and you don’t know where the problem is, and you may not even know if it’s a frontend or backend issue.
Therefore, I will tell you the answer directly here:
In most cases, CORS is not a frontend problem and cannot be solved purely by the frontend.
In other words, when encountering this error, it is usually not your responsibility to solve the problem, but the backend’s. You can keep this sentence in mind, and you should agree with it after reading the article.
Since the CORS error is caused by “cross-origin API calls,” two things must be clarified:
- What is cross-origin?
- Why can’t you make cross-origin API calls?
What is cross-origin?
The English term for cross-origin is “cross-origin,” which means that when you want to get something from source B from source A, it is cross-origin.
And this source actually represents the “source of the request,” for example, if you send a request from https://huli.tw, then the origin of this request is https://huli.tw.
And same origin means that the source is the same. If the origins of two URLs A and B are the same, we say that A and B are the same origin, also known as “the same source.”
So https://huli.tw and https://google.com are not the same origin because their origins are different.
To be more precise, you can treat the origin as a combination of scheme + host + port. The scheme is the https or http at the beginning, the host is huli.tw, and if the port is not specified, the default port for http is 80, and for https it is 443.
So,
https://huli.twandhttps://huli.tw/apiare the same origin because the scheme + host + port are the same (/apiis the path, not the host).https://huli.twandhttp://huli.tware not the same origin because the scheme is different.http://huli.twandhttp://huli.tw:3000are not the same origin because the port is different.https://api.huli.twandhttps://data.huli.tware not the same origin because the host is different.https://huli.twandhttps://api.huli.tware not the same origin because the host is different.
The fifth point is something you need to pay special attention to. Domains and subdomains are also not the same origin, so api.huli.tw and huli.tw are not the same origin. Many people often confuse this with cookies because api.huli.tw and huli.tw can share cookies.
Here, I want to emphasize that the cookie matching rule is called Domain Matching, which looks at the domain, not the origin we defined here. Don’t get confused.
From the above examples, it can be seen that achieving the same origin is quite difficult. If you only look at the URL, it basically has to look exactly the same, and only the path and the following parts can be different. For example, https://huli.tw/a/b/c/index.html?a=1 and https://huli.tw/show/cool/b.html are both under the same scheme + host + port, and their origin will be https://huli.tw, so these two URLs are the same origin.
In practice, it is quite common to represent the front-end website and API with different domains. For example, huli.tw is the front-end website, and api.huli.tw is the back-end API. Therefore, it is also common to encounter cross-origin request scenarios in practice.
(By the way, if you want to avoid cross-origin, you will put the front-end and back-end in the same origin. For example, huli.tw/api is the back-end API, and other paths are the front-end website.)
Why can’t APIs be called across domains?
After understanding the definition of the same origin, we can look at another question: “Why can’t APIs be called across domains?”
But in fact, this definition is a bit unclear. More precisely, it is: “Why can’t XMLHttpRequest or fetch (or simply called AJAX) be used to obtain resources across domains?”
I specifically mention this more precise definition because it is very common to obtain “resources across domains”, such as <img src="https://another-domain.com/bg.png" />, which is actually used to obtain resources across domains, but we are only fetching images here.
Or: <script src="https://another-domain.com/script.js" />, this is also a cross-origin request, fetching a JS file and executing it.
But have you encountered any problems with these two situations? Basically, you haven’t, and you are already used to it, without thinking that there may be problems.
So why is it different when it becomes AJAX, when it becomes XMLHttpRequest or fetch? Why are cross-origin requests blocked at this time? (This statement is actually not very accurate and will be explained in detail later)
To understand this issue, you actually need to think the other way around. Because you already know that the “result” will be blocked, since the result is like this, there must be a reason for it, but what is the reason? This is a bit like the method of proof by contradiction. If you want to prove something A, you first assume that A is wrong, and then find a counterexample to find a contradiction, and you can prove that A is correct.
You can adopt a similar strategy when thinking about technical issues like this. You first assume that “blocking cross-origin requests” is wrong and meaningless, and then if you find a contradiction, you will find that it is necessary to block cross-origin requests.
Therefore, you can think about the following question:
What will happen if cross-origin requests are not blocked?
Then I can freely connect to the API without having to google for CORS solutions! It sounds like there is no problem. Why can both img and script tags be used, but AJAX cannot?
If cross-origin AJAX is not blocked, then I can use AJAX to get data from https://google.com on my website (assuming it is https://huli.tw/index.html), right?
It seems that there is no problem, it’s just getting the HTML of Google’s homepage, nothing serious.
But if I happen to know that your company has an “internal” public website, the address is http://internal.good-company.com, which cannot be accessed externally, only the company’s employees’ computers can access it, and then I write a AJAX to get its data on my website, can I get the website content? Can I return it to my server after getting it?
This raises security issues because attackers can obtain some confidential information.
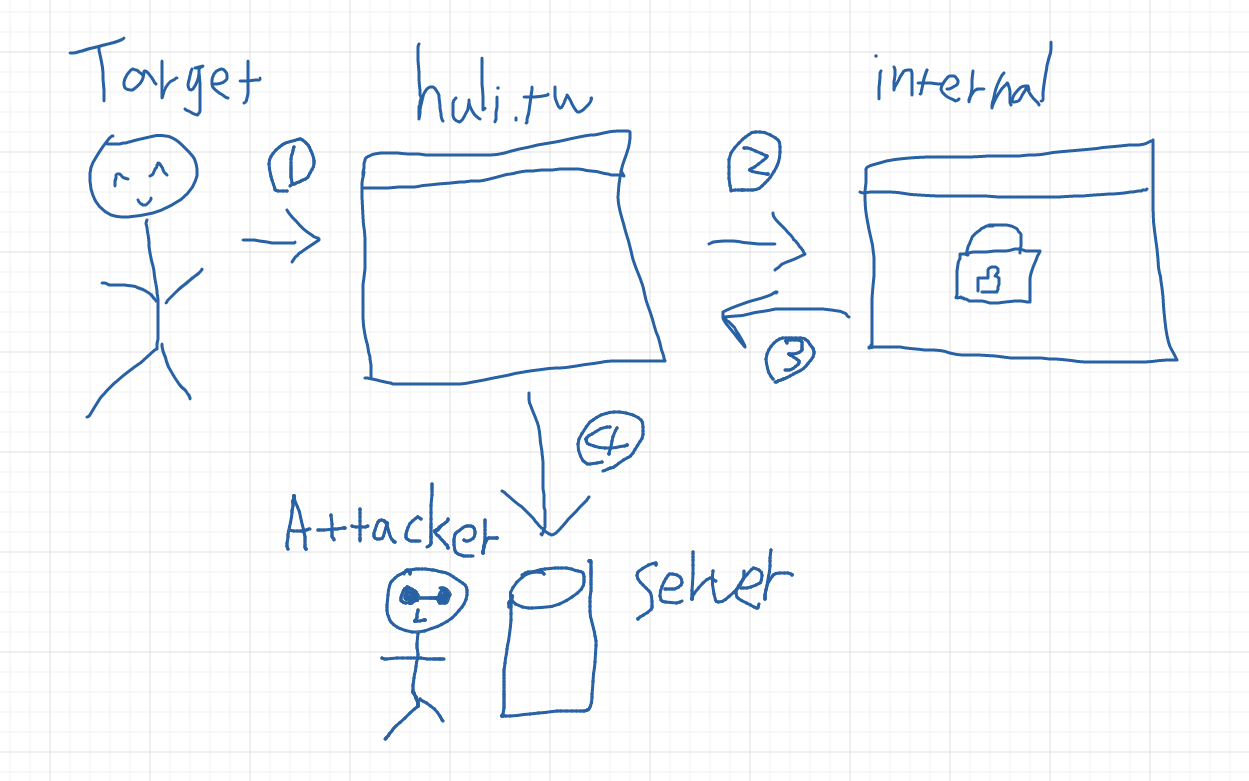
- The target opens a malicious website
- The malicious website uses AJAX to fetch data from the internal confidential website
- Get the data
- Return to the attacker’s server
You may ask: “But to use this trick, the attacker also needs to know what the URL of your internal website is, isn’t it too difficult?”
If you think this is too difficult, then I will give you another example.
I ask you a question. When you are developing, do you usually start a server on your computer, and the URL may be http://localhost:3000 or http://localhost:5566? In terms of modern front-end development, this is very common.
If the browser does not block cross-origin APIs, then I can write a piece of code like this:
function sendRequest(url, callback) {
const request = new XMLHttpRequest();
request.open('GET', url, true);
request.onload = function() {
callback(this.response);
}
request.send();
}
for (let port = 80; port < 10000; port++) {
sendRequest('http://localhost:' + port, data => {
})
}In this way, as long as you have a server running on localhost, I can get your content and know what you are developing. In work, this may be company secrets, or attackers can find vulnerabilities by analyzing these websites and then use similar methods to break in.
Furthermore, if you think the above two tricks are not feasible, we have another assumption here. In addition to assuming that cross-origin requests are not blocked, we also assume that “cross-origin requests will automatically attach cookies”.
So if I send a request to https://www.facebook.com/messages/t, I can see your chat messages, and if I send a request to https://mail.google.com/mail/u/0/, I can see your private emails.
By this point, you should understand why cross-origin AJAX needs to be blocked:
Security
In the browser, if you want to get the complete content of a website (which can be fully read), basically you can only use XMLHttpRequest or fetch. If these cross-origin AJAXs are not restricted, you can use the user’s browser to get the content of “any website”, including various websites that may have sensitive information.
Therefore, it is reasonable for browsers to block cross-origin AJAX requests for security reasons.
At this point, some people may have a question: “Why are images, CSS, or scripts not blocked?”
Because these are more like “part of the web resources”. For example, if I want to use someone else’s image, I use <img> to import it, and if I want to use CSS, I use <link href="...">. These tags have restrictions on the resources that can be obtained. Moreover, the resources obtained cannot be read by programs, which is important.
After I load the image, it is just an image. Only the browser knows the content of the image, and I don’t know it. I also cannot read it with a program. Since I cannot read it with a program, I cannot pass the obtained result to other places, so there will be less data leakage problems.
To correctly understand cross-origin requests, the first step is to understand “why browsers block them”, and the second step is to have a correct understanding of “how they are blocked”. Below, I have prepared two small quizzes for everyone to try to answer.
In-class quiz
Question 1
Xiao Ming is responsible for a project, and the URL is: https://best-landing-page.tw. This website will need to use a file from another company website, which contains some user data, and the URL is: https://lidemy.com/users.json. Xiao Ming directly clicked on this URL and found that he could see the contents of the file with the browser, so he said:
Since I can see the content with the browser, it means that the browser can open it, so I can definitely get the data with AJAX! Let’s use AJAX to get the data!
Is Xiao Ming’s statement correct? If it is incorrect, please point out the error.
Question 2
Xiao Ming is working on a project that needs to connect to an API, and there is an API within the company that is used to delete articles. Just pass the article ID over with POST in application/x-www-form-urlencoded content type to delete it.
For example: POST https://lidemy.com/deletePost and bring id=13, then the article with id 13 will be deleted (the backend does not perform any permission checks).
The domain of the company’s front-end and back-end is different, and the back-end has not added the CORS header. Therefore, Xiao Ming believes that the front-end will be restricted by the same-origin policy when using AJAX, and the request cannot be sent out at all.
After calling it, the console does show the error “request has been blocked by CORS policy: No ‘Access-Control-Allow-Origin’ header is present on the requested resource”.
So Xiao Ming believes that the front-end cannot use AJAX to call this API to delete articles, and the articles cannot be deleted.
Is Xiao Ming’s statement correct? If it is incorrect, please point out the error.
How is your cross-origin AJAX blocked?
The above two questions are conceptual questions, and you can easily answer them if you have the correct concepts.
Novices, especially those who have only dealt with JS on browsers, usually have incorrect concepts (which is normal), and the most common misconception is the wrong understanding of the same-origin policy or “cross-origin requests”.
First of all, the first important concept is: “You are writing programs on the browser”.
What does this mean? It means that the many restrictions you encounter when writing JavaScript are imposed by the browser, not by the programming language itself. Those things you can’t do are blocked by the browser.
JavaScript is a programming language, so things like var, if else, for, function, etc. are all part of JavaScript. But JavaScript needs a place to run, and this place is called the runtime environment, and the most commonly used one is: the browser.
So when you write JavaScript, you are running it on the browser, and this runtime environment provides you with some things to use, such as DOM (document), console.log, setTimeout, XMLHttpRequest, or fetch. These are not part of JavsScript (or more precisely, ECMAScript). These are provided to us by the browser, so we can only use them when running JavaScript on the browser.
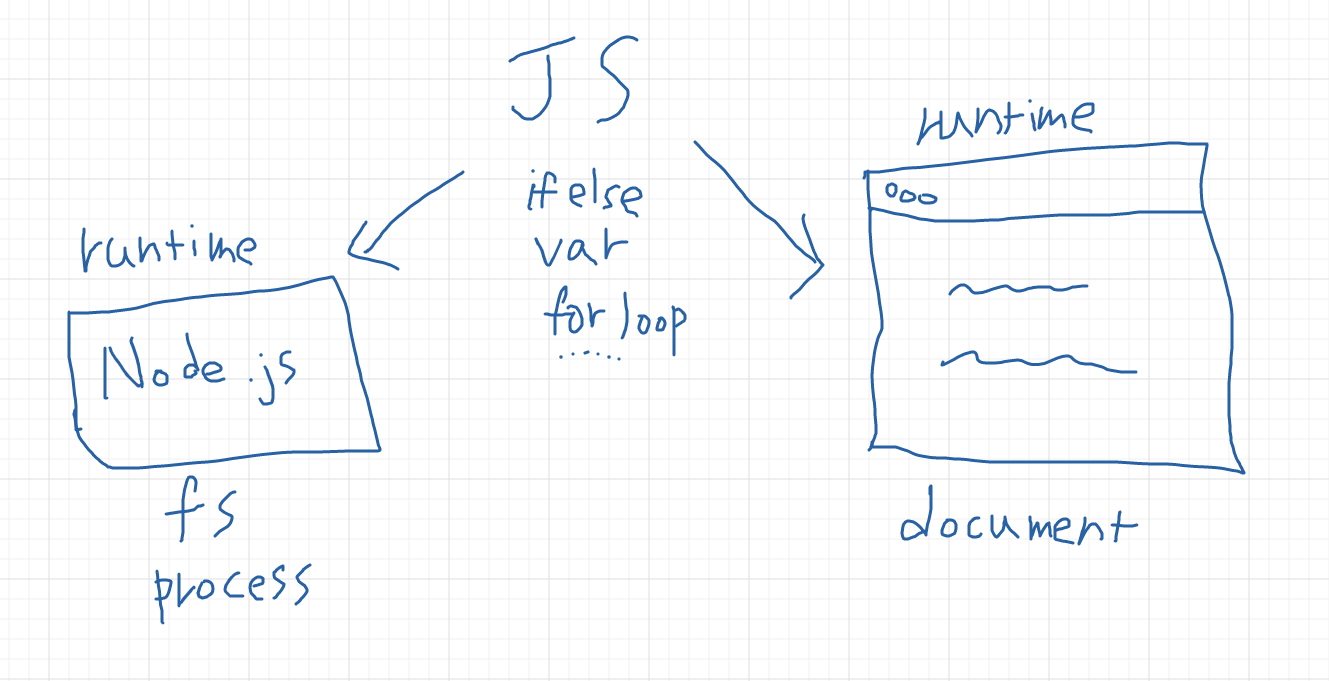
Therefore, you may have had a similar experience, thinking about why the same code cannot be executed in Node.js. Now you know that it is because Node.js does not provide these things, such as fetch, you cannot use it directly in Node.js (if you can, it means you are using other libraries or polyfills).
Conversely, when you execute JavaScript with Node.js, you can use process or fs, but you cannot use them in the browser. Different runtime environments provide different things, and you need to be very clear about where you are now.
Sometimes, different runtime environments will also provide the same things, such as console.log and setTimeout, which are available in both the browser and Node.js. But even though they look the same, the internal implementation is completely different, and the behavior may also be different. For example, the browser’s console.log will output to the console of devtool, while Node.js will output to your terminal. The implementation of setTimeout in both is also different, so there may be differences in details.
Returning to the topic, when we want to use AJAX to access a cross-origin resource on the browser, we are blocked. Who is blocking us? The browser.
In other words, if we are not using a browser, if we are not running the program on a browser, then there is no same-origin policy, and we don’t have to worry about CORS.
For example, if you join the army today, you have to fold tofu in the morning, shout “Dear Loyalty” when you enter the restaurant for lunch, greet your superiors, and start your speech with the word “Report”. Why? Because that’s how it’s regulated in the military.
But if you retire from the army today, you are free, and you don’t have to do those things anymore. The browser is like a military camp, it is a limiter with many rules, and once you leave it, there are no rules.
If you understand what I’m talking about, you probably know why a proxy can solve the CORS problem. It is because it retrieves data through the backend, not through the browser (which will be explained in detail later).
When the browser opens a webpage, there are no same-origin policy rules. You can open any webpage you want, and the browser won’t stop you.
So the answer to the first question of the quiz is: “Xiao Ming’s statement is incorrect. The fact that you can open a file with a browser doesn’t mean anything, and it has nothing to do with CORS. Browsing a website with a browser and using AJAX to retrieve data are two completely different things.”
After solving the first question, let’s look at the second question. The gist of it is that Xiao Ming received a CORS error after sending a request, so he said that the request was blocked.
The concept being tested in the second question is:
What does it mean when a cross-origin request is blocked by the browser? How is it blocked?
This question is included because many people believe that “the blocked cross-origin request is the request,” so in Xiao Ming’s example, the request was blocked by the browser, and it couldn’t reach the server, so the data couldn’t be deleted.
However, this statement is problematic if you think about it. You can tell from the error message:
request has been blocked by CORS policy: No ‘Access-Control-Allow-Origin’ header is present on the requested resource
The browser says that the header doesn’t exist, what does that mean? It means that it has sent out the request, and it knows that the Access-Control-Allow-Origin header doesn’t exist only after receiving the response.
So the browser is not blocking the request, but the response. Your request has already reached the server, and the server has returned a response, but the browser just doesn’t give you the result.
Therefore, the answer to the second question is that although Xiao Ming saw this CORS error, the article was actually deleted because the request had been sent to the server, but Xiao Ming couldn’t get the response. Yes, the article was deleted, really.
Finally, let me add one more concept. Earlier, I mentioned that CORS is blocked for security reasons. If it is not blocked, attackers can use AJAX to retrieve non-public data from the intranet, and company secrets will be leaked. And here I say “there is no CORS problem once you leave the browser,” which means that even if CORS is blocked, can’t I send a request to the same website myself? Does that mean there is no security issue?
For example, if I use curl or Postman or any tool, I should be able to bypass CORS, right?
People who think this way overlook a fundamental difference between the two.
Suppose our target is a company’s intranet, and the URL is: http://internal.good-company.com
If I send a request directly from my computer using curl, I will only get an error because I don’t have permission since I am not in the company’s intranet. I may not even be able to connect to this domain because only the intranet can resolve it.
CORS is: “I created a website for intranet users to access and send requests to retrieve data.” The biggest difference between these two is “who is visiting the website from whose computer.” The former is me, and the latter is someone else (and someone who can connect to the intranet).
As shown in the figure, the upper part is when the attacker tries to connect to that URL by himself, he cannot connect because the target is in the intranet. So even if there is no same-origin policy, the attacker still cannot get what he wants.
The lower part is when the attacker creates a malicious website and tries to get users to visit it, such as at point 1. After the user visits the website, it follows the process at point 2, sends a request to the target (internal server) using AJAX at point 3, retrieves the data, and returns it to the attacker at point 4.
With the protection of same-origin policy, step 4 will not be executed because JS cannot get the result of the fetch, so it won’t know what the response is.
Summary
This article mainly discusses why browsers block certain requests and how they do it. It also highlights several common misconceptions that beginners often have. Here are the key points:
- Browsers block cross-origin requests for security reasons. With AJAX, you can directly access the entire response, so not blocking it would be problematic. However, with elements like the
imgtag, you cannot access the response, so it is less of an issue. - Same-origin policy and CORS exist because we are “writing JS in the browser,” so we are subject to the limitations of the execution environment. If we were writing in Node.js, we would not have these issues and could access whatever we want without being blocked.
- In the browser, CORS restrictions actually apply to “not being able to access the response,” not “not being able to send the request.” The request has already been sent and the browser has received the response, but it does not give it to you for security reasons. (This statement is not entirely accurate, as there are simple and non-simple requests, which will be discussed in the third article.)
After clarifying these important concepts, we can move on to our next article: CORS Complete Guide (Part 2): How to Solve CORS Issues?.
Comments