前言
三年前的時候寫了一篇文章:輕鬆理解 AJAX 與跨來源請求,提到了串接 API、AJAX、same-origin policy、JSONP 以及 CORS,當時把自己想講的都放進去了,但現在回頭看,好像有很多滿重要的部分沒有提到。
三年後,再次挑戰這個主題,並且試著表達地更完整。
會想寫這個系列是因為在程式相關的討論區上,CORS 是發問頻率很高的主題,無論是前端或是後端都有可能來問相關的問題。
所以我就想說:「好,那我來寫一個系列好了,我要試著把這個主題寫到每個碰到 CORS 問題的人都會來看這個系列,而且看完以後就知道該怎麼解決問題」,這算是我對這篇文章的目標,如果文章的品質沒辦法達成這個目標,我會持續改進。
這系列一共有六篇文章,分別是:
- CORS 完全手冊(一):為什麼會發生 CORS 錯誤?
- CORS 完全手冊(二):如何解決 CORS 問題?
- CORS 完全手冊(三):CORS 詳解
- CORS 完全手冊(四):一起看規範
- CORS 完全手冊(五):跨來源的安全性問題
- CORS 完全手冊(六):總結、後記與遺珠
會從 same-origin policy 開始講起,接著講到為什麼跨來源存取資源會有錯誤,再來會講如何錯誤地以及正確地解決 CORS 相關的問題,而第三篇會詳細講解跨來源請求的詳細流程,像是 preflight request 之類的東西。
基礎的部分看前三篇就夠了,接下來會比較深一點。第四篇會帶你一起看 spec,證明前面幾篇不是我在虎爛的,而第五篇則是帶大家看看 CORB(Cross-Origin Read Blocking)、COEP(Cross-Origin Embedder Policy)或是 COOP(Cross-Origin-Opener-Policy)之類的跨來源相關規定,以及相關的安全性問題,最後一篇則是一些比較零散的主題以及心得感想。
身為系列文的第一篇,就是要帶大家去思考為什麼要有 same-origin policy 的存在,為什麼跨來源存取資源會錯誤。如果不知道這個問題的答案,那通常都不是真的理解 CORS 到底在規範什麼,也很有可能會用一些錯誤的解法去解這個問題。
在這篇裡面,我預設大家已經對跨來源請求以及 CORS 有一些基本概念了,如果完全沒有概念的話,可以先參考一下我以前寫過的這篇:輕鬆理解 AJAX 與跨來源請求。
在正式開始以前,想先跟大家講一個小故事,跟整個 CORS 有關的一個小故事,反正大家就當一個無厘頭故事看就好,等真正理解完整個跨來源請求相關的東西以後,就知道這故事代表什麼了。
故事的主角是一個求知若渴,希望獲得各種資訊的小資(不是小資女孩向前衝的那個小資),而政府想要監控這些求知若渴的人,試圖知道他們到底都去問了哪些資訊,所以把他安置在一個小房間,跟外界的溝通都要透過門口的警衛。
所以小資沒辦法親自出去,但是有什麼想知道的事情都可以問警衛,警衛都會幫他去問。身為一個求知若渴的人,小資常常問他很多問題,例如說:「速食店的大麥克現在一個多少錢?」、「我的存款剩下多少?」、「我爸媽過得好嗎」等等。
針對小資的每一個提問,警衛都會幫他去問到當事人,但不一定會把答案告訴他。政府規定了一個程序,那就是「除非被問的人明確同意,不然不能把答案告訴小資」,所以警衛會先問完問題拿到答案,再問說:「請問你願意讓小資知道這件事嗎?」,有些人願意,例如說速食店,雖然他根本不認識小資,但畢竟這類資訊告訴誰都可以。但也有些人不願意,因為根本不知道誰是小資。還有一種狀況,警衛連問都不用問,那就是小資的家人。因為小資的家人跟小資血脈相承,系出同源,所以不用問就可以放行。
於是呢,儘管小資的每一個問題都有傳達到被問的人那裡,卻不一定能收到回覆。有一天小資終於受不了這種被囚禁的生活,於是想了幾個方法。
第一個方法是把警衛打倒逃出去,沒有警衛了他就自由了,想問誰問題就問誰,不用再透過警衛,完全沒有任何拘束。
第二個方法是拜託朋友幫忙當暗樁。每當小資有問題時,都跟警衛說:「你去問我朋友,大麥克多少錢」,接著朋友再去問速食店,再把結果跟警衛講,順便交代警衛他願意讓小資知道這件事。因為問題都會透過他朋友轉傳,而朋友每次都會交代警衛這個資訊可以讓小資知道,所以小資就不會有之前提到的那個限制了。
第三個方法是讓大家都願意把資訊告訴他,這樣就不會被警衛攔截,就能順利知道問題的答案。
好,故事結束了,雖然我覺得沒有到很貼切就是了,不過浮誇的故事總是比較吸引人注意,就先這樣吧,接著讓我們來進入主題。
從熟悉的錯誤訊息開始
我相信大家一定都對這個錯誤訊息不陌生:
request has been blocked by CORS policy: No ‘Access-Control-Allow-Origin’ header is present on the requested resource.
在前端用 XMLHttpRequest 或者是用 fetch 的時候,應該都有碰過這個錯誤。在串接後端或是網路上的 API 時,就是串不起來,而你也不知道是哪邊出了錯,甚至連這是前端還是後端要處理的可能都不太知道。
因此,我在這邊直接先跟你講答案:
大部分情形下,CORS 都不是前端的問題,純前端是解決不了的。
換句話說,碰到這個錯誤的時候,通常都不是你應該要解決問題,而是後端。大家可以先把這一句話放在心中,等到看完文章的時候,應該就會認同這句話了。
既然 CORS 的這個錯誤是出在「跨來源呼叫 API」,那勢必就要兩件事情要釐清:
- 什麼是跨來源?
- 為什麼不能跨來源呼叫 API?
什麼是跨來源?
跨來源的英文是 cross origin,顧名思義,當你想要從來源 A 去拿來源 B 的東西,就是跨來源。
而這個來源,其實就是代表著「發送 request 的來源」,例如說你現在在 https://huli.tw 發送一個 request 出去,那這個 request 的 origin 就是 https://huli.tw。
而 same origin 就代表著來源一樣,如果有兩個 URL A 跟 B 的 origin 是一樣的,我們就說 A 跟 B 是 same origin,也叫做「同源(同個來源)」。
所以 https://huli.tw 跟 https://google.com 不同源,因為它們的 origin 不一樣。
更精確一點地說,你可以把 origin 當作是:scheme + host + port 的組合。scheme 就是最前面的那個 https 或是 http 之類的東西,host 就是 huli.tw,而 port 的話如果沒有特別指定,http 預設的 port 就是 80,https 就是 443。
所以呢,
https://huli.tw跟https://huli.tw/api同源,因為 scheme + host + port 都一樣(/api是 path 的部分,不是 host)https://huli.tw跟http://huli.tw不同源,因為 scheme 不一樣http://huli.tw跟http://huli.tw:3000不同源,因為 port 不一樣https://api.huli.tw跟https://data.huli.tw不同源,因為 host 不一樣https://huli.tw跟https://api.huli.tw不同源,因為 host 不一樣
第五點是大家要特別注意的一點,domain 跟 subdomain 之間也是不同源的,所以 api.huli.tw 跟 huli.tw 不同源。有很多人常常會把這個跟 cookie 搞混,因為 api.huli.tw 跟 huli.tw 是可以共用 cookie 的。
在這邊特別強調,cookie 比對的規則叫做:Domain Matching ,它是看 domain 而不是看我們這邊所定義的 origin,千萬不要搞混了。
從以上範例可以得知,其實要達成 same origin 滿困難的,如果只看網址的話,基本上要長得一模一樣,只有 path 跟後面的部分可以不一樣,例如說 https://huli.tw/a/b/c/index.html?a=1 跟 https://huli.tw/show/cool/b.html 他們都是在同一個 scheme + host + post 底下,origin 都會是https://huli.tw,因此這兩個網址是同源的。
在實務上面,其實也滿常會把前端網站本身跟 API 用不同的網域來表示,例如說 huli.tw 就是前端網站,api.huli.tw 就是後端 API,所以實務上也很常碰到跨來源請求的場景。
(順帶一提,想避開跨來源的話會把前後端放在同一個 origin 下,例如說 huli.tw/api 就都是後端 API,其他路徑則是前端網站。)
為什麼不能跨來源呼叫 API?
理解了同源的定義之後,我們可以來看剛剛的另一個問題,就是:「為什麼不能跨來源呼叫 API?」。
但其實這個定義有點不清楚,更精確一點的說法是:「為什麼不能用 XMLHttpRequest 或是 fetch(或也可以簡單稱作 AJAX)獲取跨來源的資源?」
會特別講這個更精確的定義,是因為去拿一個「跨來源的資源」其實很常見,例如說 <img src="https://another-domain.com/bg.png" />,這其實就是跨來源去抓取資源,只是這邊我們抓取的目標是圖片而已。
或者是:<script src="https://another-domain.com/script.js" />,這也是跨來源請求,去抓一個 JS 檔案回來並且執行。
但以上兩種狀況你有碰到過問題嗎?基本上應該都沒有,而且你已經用得很習慣了,完全沒有想到可能會出問題。
那為什麼變成 AJAX,變成用 XMLHttpRequest 或是 fetch 的時候就不同了?為什麼這時候跨來源的請求就會被擋住?(這邊的說法其實不太精確,之後會詳細解釋)
要理解這個問題,其實你要反過來想。因為你已經知道「結果」就是會被擋住,既然結果是這樣,那一定有它的原因,可是原因是什麼呢?這有點像是反證法一樣,你想要證明一個東西 A,你就先假設 A 是錯的,然後找出反例發現矛盾,就能證明 A 是對的。
要思考這種技術相關問題時也可以採取類似的策略,你先假設「擋住跨來源請求」是錯的,是沒有意義的,再來如果你發現矛盾,發現其實是必要的,你就知道為什麼要擋住跨來源請求了。
因此,可以思考底下這個問題:
如果跨來源請求不會被擋住,會發生什麼事?
那我就可以自由自在串 API,不用在那邊 google 找 CORS 的解法了!聽起來好像沒什麼問題,憑什麼 img 跟 script 標籤都可以,但 AJAX 卻不行呢?
如果跨來源的 AJAX 不會被擋的話,那我就可以在我的網域的網頁(假設是 https://huli.tw/index.html),用 AJAX 去拿 https://google.com的資料對吧?
看起來好像沒什麼問題,只是拿 Google 首頁的 HTML 而已,沒什麼大不了。
但如果今天我恰好知道你們公司有一個「內部」的公開網站,網址叫做 http://internal.good-company.com,這是外部連不進去的,只有公司員工的電腦可以連的到,然後我在我的網頁寫一段 AJAX 去拿它的資料,是不是就可以拿得到網站內容?那我拿到以後是不是就可以傳回我的 server?
這樣就有了安全性的問題,因為攻擊者可以拿到一些機密資料。
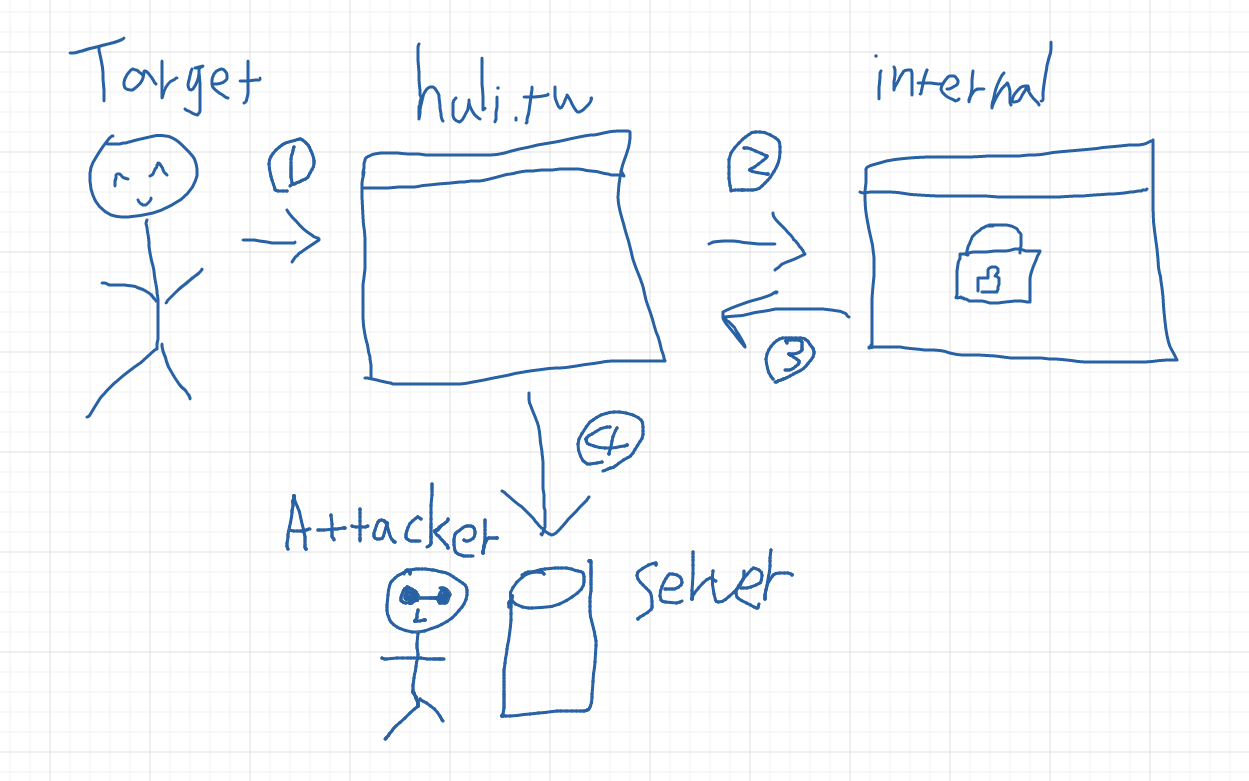
- 目標打開惡意網站
- 惡意網站用 AJAX 抓取內部機密網站的資料
- 拿到資料
- 回傳給攻擊者的 server
你可能會問說:「可是要用這招,攻擊者也要知道你內部網站的網址是什麼,太難了吧!」
如果你覺得這樣太難,那我換個例子。
我請問你一個問題,你平常在開發的時候,是不是都是在自己電腦開一個 server 起來,網址有可能是 http://localhost:3000 或是 http://localhost:5566 之類的?以現代前端開發來說,這再常見不過了。
如果瀏覽器沒有擋跨來源的 API,那我就可以寫一段這樣的程式碼:
// 發出 request 得到資料
function sendRequest(url, callback) {
const request = new XMLHttpRequest();
request.open('GET', url, true);
request.onload = function() {
callback(this.response);
}
request.send();
}
// 嘗試針對每一個 port 拿資料,拿到就送回去我的 server
for (let port = 80; port < 10000; port++) {
sendRequest('http://localhost:' + port, data => {
// 把資料送回我的 server
})
}如此一來,只要你有跑在 localhost 的 server,我就可以拿到你的內容,進而得知你在開發的東西。在工作上,這有可能就是公司機密了,或是攻擊者可以藉由分析這些網站找出漏洞,然後用類似的方法打進來。
再者,如果你覺得以上兩招都不可行,在這邊我們再多一個假設。除了假設跨來源請求不會被擋以外,也假設「跨來源請求會自動附上 cookie」。
所以如果我發一個 request 到 https://www.facebook.com/messages/t,就可以看到你的聊天訊息,發 request 到 https://mail.google.com/mail/u/0/,就可以看到你的私人信件。
講到這邊,你應該可以理解為什麼要擋住跨來源的 AJAX 了,說穿了就是三個字:
安全性
在瀏覽器上,如果你想拿到一個網站的完整內容(可以完整讀取),基本上就只能透過 XMLHttpRequest 或是 fetch。若是這些跨來源的 AJAX 沒有限制的話,你就可以透過使用者的瀏覽器,拿到「任意網站」的內容,包含了各種可能有敏感資訊的網站。
因此瀏覽器會擋跨來源的 AJAX 是十分合理的一件事,就是為了安全性。
這時候有些人可能會有個疑問:「那為什麼圖片、CSS 或是 script 不擋?」
因為這些比較像是「網頁資源的一部分」,例如說我想要用別人的圖片,我就用 <img> 來引入,想要用 CSS 就用 <link href="...">,這些標籤可以拿到的資源是有限制的。再者,這些取得回來的資源,我沒辦法用程式去讀取它,這很重要。
我載入圖片之後它就真的只是張圖片,只有瀏覽器知道圖片的內容,我不會知道,我也沒有辦法用程式去讀取它。既然沒辦法用程式去讀取它,那我也沒辦法把拿到的結果傳到其他地方,就比較不會有資料外洩的問題。
想要正確認識跨來源請求,第一步就是認識「為什麼瀏覽器要把這些擋住」,而第二步,就是對於「怎麼個擋法」有正確的認知。底下我準備了兩題小測驗,大家可以試著回答看看。
隨堂小測驗
第一題
小明正負責寫一個專案,網址是:https://best-landing-page.tw。這網站會需要用到公司其他網站的某個檔案,裡面是一些使用者資料,網址是:https://lidemy.com/users.json。小明直接點開這個網址,發現用瀏覽器可以看到檔案的內容,於是就說:
既然我用瀏覽器可以看得到內容,就表示瀏覽器打得開,那用 AJAX 的時候也一定可以拿得到資料!我們來用 AJAX 拿資料吧!
請問小明的說法是正確的嗎?如果錯誤,請指出錯誤的地方。
第二題
小明正在做的專案需要串接 API,而公司內部有一個 API 是拿來刪除文章的,只要把文章 id 用 POST 以 application/x-www-form-urlencoded 的 content type 帶過去即可刪除。
舉例來說:POST https://lidemy.com/deletePost 並帶上 id=13,就會刪除 id 是 13 的文章(後端沒有做任何權限檢查)。
公司前後端的網域是不同的,而且後端並沒有加上 CORS 的 header,因此小明認為前端用 AJAX 會受到同源政策的限制,request 根本發不出去。
而實際上呼叫以後,果然 console 也出現:「request has been blocked by CORS policy: No ‘Access-Control-Allow-Origin’ header is present on the requested resource」 的錯誤。
所以小明認為前端沒辦法利用 AJAX 呼叫這個 API 刪除文章,文章是刪不掉的。
請問小明的說法是正確的嗎?如果錯誤,請指出錯誤的地方。
你的跨來源 AJAX 是怎麼被擋掉的?
上面這兩題都是觀念題,只要觀念正確就可以輕鬆回答。
而新手,尤其是只碰過瀏覽器上面的 JS 的新手通常觀念都不太正確(這很正常),而最容易有的錯誤觀念,就是對於 same-origin policy 或者是「跨來源請求」的錯誤認知。
首先,第一個重要觀念是:「你是在瀏覽器上面寫程式」。
這是什麼意思?意思就是你在寫 JavaScript 時的諸多限制,都是瀏覽器限制你,而不是程式語言本身限制你。那些你沒辦法做到的事,都是被瀏覽器擋住了。
JavaScript 是一個程式語言,所以像 var、if else、for、function 等等,這些都是 JavaScript 的一部分。但 JavaScript 需要有地方執行,而這個地方就叫做執行環境(runtime),大家最常用的就是:瀏覽器。
所以你的 JavaScript 是在瀏覽器上執行的,而這個執行環境會提供給你一些東西使用,例如說 DOM(document)、console.log、setTimeout、XMLHttpRequest 或是 fetch,這些其實都不是 JavsScript(或是更精確地說,ECMAScript)的一部分。這些是瀏覽器給我們使用的,所以我們只有在瀏覽器上面執行 JavaScript 時才用得到。
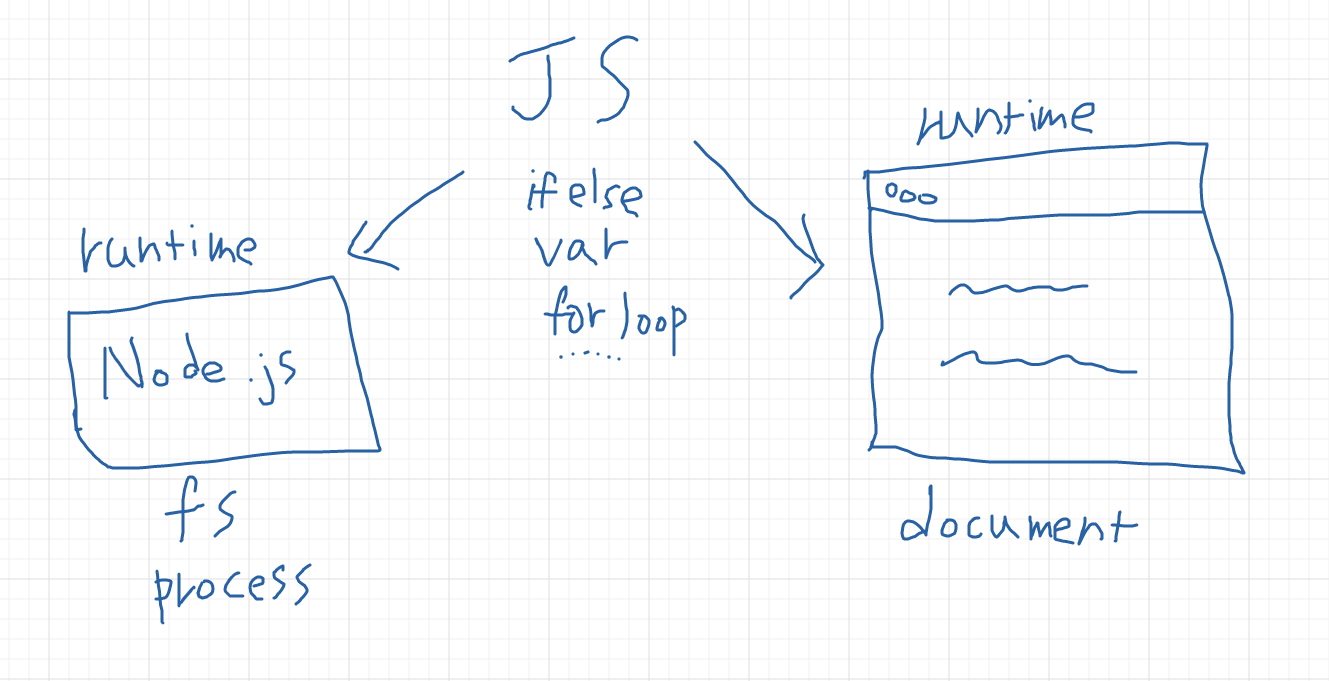
因此你可能有過類似的經驗,想說為什麼一樣的 code 搬到 Node.js 去就沒辦法執行。現在你知道了,那是因為 Node.js 並沒有提供這些東西,例如說 fetch,你沒辦法直接在 Node.js 裡面使用它(如果可以,那就代表你有用其它 library 或是 polyfill)。
相反過來也是,你把 JavaScript 用 Node.js 執行時,你可以用 process 或是 fs,但你在瀏覽器上面就沒辦法。不同的執行環境會提供不同的東西,你要很清楚現在是在哪個執行環境。
而有時候,不同的執行環境也會提供相同的東西,例如說 console.log 跟 setTimeout,在瀏覽器以及 Node.js 都有。但儘管他們看起來一樣,內部實作卻是完全不同,表現方法也可能不同。舉例來說,瀏覽器的 console.log 會輸出在 devtool 的 console,而 Node.js 則是會輸出在你的 terminal 上面。而兩者的 setTimeout 實作也不一樣,所以細節可能會有差別。
回到主題,我們在瀏覽器上想要對一個跨來源的資源做 AJAX,然後被擋住了。被誰擋住?瀏覽器。
換句話說,如果沒有瀏覽器,如果我今天不是在瀏覽器上面執行程式,那就根本沒有什麼 same-origin policy,也不用管什麼 CORS。
舉例來說,你今天去當兵,早上起床要折豆腐被,中午吃飯進餐廳要喊親愛精誠,看到長官要問好,講話開頭要加報告兩個字。為什麼?因為軍中是那樣規定的。
可是如果你今天退伍了,不在軍營裡面,也不是阿兵哥了,你就自由了,就再也不用做上面那些事了。瀏覽器在這邊就像是軍營,它是一個限制器,有著諸多的規則,一旦脫離它,就什麼規則都沒有了。
如果你有聽懂我在講什麼,大概就知道為什麼 proxy 一定可以解決 CORS 的問題,因為它是透過後端自己去拿資料,而不是透過瀏覽器(這之後會再詳細講)。
而瀏覽器本身在開網頁的時候,也是根本沒有什麼 same-origin policy 的規則,你想開什麼網頁就開什麼,不會阻止你。
所以隨堂測驗的第一題,用瀏覽器打得開那個 JSON 檔案,這根本不算什麼,因為一定打得開,這跟 CORS 一點關係都沒有。用瀏覽器瀏覽網站,跟用 AJAX 拿資料是完全不同的兩件事。
所以第一題的解答是:「小明的說法錯誤,用瀏覽器能打開檔案不代表什麼,跟 CORS 無關。是不是能夠跨來源使用 AJAX,要看 response 的 header」。
解決了第一題之後,來看第二題,大意就是小明發了一個 request 之後收到 CORS 錯誤,於是就說這 request 被擋掉了。
第二題在考的觀念是:
跨來源請求被瀏覽器擋住,實際上到底是什麼意思?是怎麼被擋掉的?
會有這一題,是因為有很多人認為:「跨來源請求擋住的是 request」,因此在小明的例子中,request 被瀏覽器擋住,沒辦法抵達 server 端,所以資料刪不掉。
但這個說法其實想一下就知道有問題,你看錯誤訊息就知道了:
request has been blocked by CORS policy: No ‘Access-Control-Allow-Origin’ header is present on the requested resource
瀏覽器說沒有那個 header 存在,就代表什麼?代表它已經幫你把 request 發出去,而且拿到 response 了,才會知道沒有 Access-Control-Allow-Origin 的 header 存在。
所以瀏覽器擋住的不是 request,而是 response。你的 request 已經抵達 server 端,server 也回傳 response 了,只是瀏覽器不把結果給你而已。
因此第二題的答案是,儘管小明看到這個 CORS 的錯誤,但因為 request 其實已經發到 server 去了,所以文章有被刪掉,只是小明拿不到 response 而已。對,文章被刪掉了,真的。
最後再補充一個觀念,前面有講說擋 CORS 是為了安全性,如果沒有擋的話,那攻擊者可以利用 AJAX 去拿內網的非公開資料,公司機密就外洩了。而這邊我又說「脫離瀏覽器就沒有 CORS 問題」,那不就代表就算有 CORS 擋住,我還是可以自己發 request 去同一個網站拿資料嗎?難道這樣就沒有安全性問題嗎?
舉例來說,我自己用 curl 或是 Postman 或任何工具,應該就能不被 CORS 限制住了不是嗎?
會這樣想的人忽略了一個特點,這兩種有一個根本性的差異。
假設今天我們的目標是某個公司的內網,網址是:http://internal.good-company.com
如果我直接從我電腦上透過 curl 發 request,我只會得到一個錯誤,因為一來我不是在那間公司的內網所以沒有權限,二來我甚至連這個 domain 都有可能連不到,因為只有內網可以解析。
而 CORS 是:「我寫了一個網站,讓內網使用者去開這個網站,並且發送 request 去拿資料」。這兩者最大的區別是「是從誰的電腦造訪網站」,前者是我自己,後者則是透過其他人(而且是可以連到內網的人)。
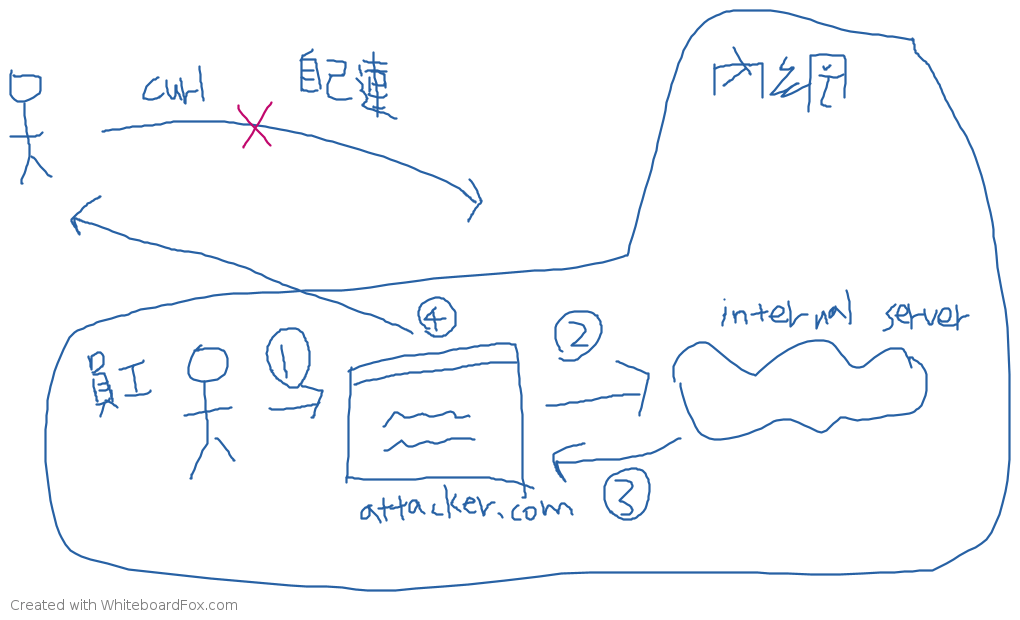
如圖所示,上半部是攻擊者自己去連那個網址,會連不進去,因為攻擊目標在內網裡。所以儘管沒有 same-origin policy,攻擊者依然拿不到想要的東西。
而下半部則是攻擊者寫了一個惡意網站,並且想辦法讓使用者去造訪那個網站,像是標 1 的那邊,當使用者造訪網站之後,就是 2 的流程,會用 AJAX 發 request 到攻擊目標(internal server),3 拿完資料以後,就是步驟 4 回傳到攻擊者這邊。
有了 same-origin policy 的保護,步驟 4 就不會成立,因為 JS 拿不到 fetch 完的結果,所以不會知道 response 是什麼。
總結
這篇主要講的是為什麼瀏覽器要擋你東西,以及到底是怎麼個擋法,也針對幾點我覺得初學者最常出錯的觀念特別講了一下,幫大家條列式整理重點:
- 瀏覽器會擋你的跨來源請求,是因為安全性問題。因為 AJAX 你可以直接拿到整個 response,所以不擋的話會有問題,但像是 img 標籤你其實就拿不到 response,所以比較沒有問題
- 今天會有 same-origin policy 跟 CORS,是因為我們「在瀏覽器上寫 JS」,所以受到執行環境的限制。如果我們今天寫的是 Node.js,就完全沒有這些問題,想拿什麼就拿什麼,不會有人擋我們
- 在瀏覽器上面,CORS 限制的其實是「拿不到 response」,而不是「發不出 request」。所以 request 其實已經發出去了,瀏覽器也拿到 response 了,只是它因為安全性考量不給你(這講法也有一點不太精確,因為有分簡單請求跟非簡單請求,這個在第三篇會提到)。
在釐清這些重要的觀念以後,就可以進入到我們的下一篇:CORS 完全手冊(二):如何解決 CORS 問題?。
評論