前言
在前面幾篇裡面,我們知道 CORS protocol 基本上就是為了安全性所產生的協定,而除了 CORS 以外,其實還有一系列跟跨來源有關的東西,例如說:
- CORB(Cross-Origin Read Blocking)
- CORP(Cross-Origin Resource Policy)
- COEP(Cross-Origin-Embedder-Policy)
- COOP(Cross-Origin-Opener-Policy)
是不是光看到這一系列很類似的名詞就已經頭昏眼花了?對,我也是。在整理這些資料的過程中,發現跨來源相關的安全性問題比我想像中還來得複雜,不過花點時間整理之後發現還是有脈絡可循,因此這篇會以我覺得應該比較好理解的脈絡,去講解為什麼會有這些東西出現。
除了上面這些 COXX 的各種東西,還有其他我想提的跨來源相關安全性問題,也會在這篇一併提到。
在繼續下去之前先提醒一下大家,這篇在講的是「跨來源的安全性問題」,而不單單只是「CORS 的安全性問題」。CORS protocol 所保護的東西跟內容在之前都介紹過了,這篇要談的其實已經有點偏離大標題「CORS」完全手冊,因為這跟 CORS 協定關係不大,而是把層次再往上拉高,談談「跨來源」這件事情。
所以在看底下的東西的時候,不要把它跟 CORS 搞混了。除了待會要講的第一個東西,其他的跟 CORS 關係都不大。
CORS misconfiguration
如果你還記得的話,前面我有提到過如果跨來源請求想要帶上 cookie,那 Access-Control-Allow-Origin 就不能是 *,而是必須指定單一的 origin,否則瀏覽器就不會給過。
但現實的狀況是,我們不可能只有一個 origin。我們可能有許多的 origin,例如說 buy.example.com、social.example.com、note.example.com,都需要去存取 api.example.com,這時候我們就沒辦法寫死 response header 裡的 origin,而是必須動態調整。
先講一種最糟糕的寫法,就是這樣:
app.use((req, res, next) => {
res.headers['Access-Control-Allow-Credentials'] = 'true'
res.headers['Access-Control-Allow-Origin'] = req.headers['Origin']
})為了方便起見,所以直接映射 request header 裡面的 origin。這樣做的話,其實就代表任何一個 origin 都能夠通過 CORS 檢查。
這樣做會有什麼問題呢?
問題可大了。
假設我今天做一個釣魚網站,網址是 http://fake-example.com,並且試圖讓使用者去點擊這個網站,而釣魚網站裡面寫了一段 script:
// 用 api 去拿使用者資料,並且帶上 cookie
fetch('http://api.example.com/me', {
credentials: 'include'
})
.then(res => res.text())
.then(res => {
// 成功拿到使用者資料,我可以傳送到我自己的 server
console.log(res)
// 把使用者導回真正的網站
window.location = 'http://example.com'
})我用 fetch 去打 http://api.example.com/me 拿資料,並且帶上 cookie。接著因為 server 不管怎樣都會回覆正確的 header,所以 CORS 檢查就通過了,我就拿到資料了。
因此這個攻擊只要使用者點了釣魚網站並且在 example.com 是登入狀態,就會中招。至於影響範圍要看網站的 api,最基本的就是只拿得到使用者資料,比較嚴重一點的可能可以拿到 user token(如果有這個 api)。
這個攻擊有幾件事情要注意:
- 這不是 XSS,因為我沒有在
example.com執行程式碼,我是在我自己的釣魚網站http://fake-example.com上執行 - 這有點像是 CSRF,但是網站通常對於 GET 的 API 並不會加上 CSRF token 的防護,所以可以過關
- 如果有設定 SameSite cookie,攻擊就會失效,因為 cookie 會帶不上去
因此這個攻擊要成立有幾個前提:
- CORS header 給到不該給的 origin
- 網站採用 cookie 進行身份驗證,而且沒有設定 SameSite
- 使用者要主動點擊釣魚網站並且是登入狀態
針對第一點,可能沒有人會像我上面那樣子寫,直接用 request header 的 origin。比較有可能的做法是這樣:
app.use((req, res, next) => {
res.headers['Access-Control-Allow-Credentials'] = 'true'
const origin = req.headers['Origin']
// 偵測是不是 example.com 結尾
if (/example\.com$/.test(origin)) {
res.headers['Access-Control-Allow-Origin'] = origin
}
})如此一來,底下的 origin 都可以過關:
- example.com
- buy.example.com
- social.example.com
可是這樣寫是有問題的,因為這樣也可以過關:
- fakeexample.com
像是這類型的漏洞是經由錯誤的 CORS 設置引起,所以稱為 CORS misconfiguration。
而解決方法就是不要用 RegExp 去判斷,而是事先準備好一個清單,有在清單中出現的才通過,否則都是失敗,如此一來就可以保證不會有判斷上的漏洞,然後也記得把 cookie 加上 SameSite 屬性。
const allowOrigins = [
'example.com',
'buy.example.com',
'social.example.com'
]
app.use((req, res, next) => {
res.headers['Access-Control-Allow-Credentials'] = 'true'
const origin = req.headers['Origin']
if (allowOrigins.includes(origin)) {
res.headers['Access-Control-Allow-Origin'] = origin
}
})想知道更多的話可以參考:
- 3 Ways to Exploit Misconfigured Cross-Origin Resource Sharing (CORS)
- JetBrains IDE Remote Code Execution and Local File Disclosure
- AppSec EU 2017 Exploiting CORS Misconfigurations For Bitcoins And Bounties by James Kettle
繞過 Same-origin Policy?
除了 CORS 以外,Same-origin policy 其實出現在瀏覽器的各個地方,例如說 window.open 以及 iframe。當你使用 window.open 打開一個網頁的時候,回傳值會是那個新的網頁的 window(更精確來說是 WindowProxy 啦,可以參考 MDN: Window.open()),但只有在 same origin 的狀況下才能存取,如果不是 same origin 的話,只能存取很小一部分的東西。
假設我現在在 a.example.com 好了,然後寫了這一段 script:
var win = window.open('http://b.example.com')
// 等新的頁面載入完成
setTimeout(() => {
console.log(win)
}, 2000)用 window.open 去開啟 b.example.com,等頁面載入完成之後去存取 b.example.com 的 window。
執行之後會看到 console 有一段錯誤:

因為 a.example.com 跟 b.example.com 是 cross origin,所以沒辦法存取到 window。這個規範其實也十分合理,因為如果能存取到 window 的話其實可以做滿多事情的,所以限制在 same origin 底下才能拿到 window。
不過「沒辦法存取 window」這個說法不太精確,因為就算是 cross origin,仍然有一些操作是允許的,例如說:
var win = window.open('http://b.example.com')
// 等新的頁面載入完成
setTimeout(() => {
// 變更開啟的 window 的位置
win.location = 'https://google.com'
setTimeout(() => {
// 關閉視窗
win.close()
}, 2000)
}, 2000)可以改變開啟的 window 的 location,也可以關閉開啟的視窗。
相對地,身為被開啟的那個視窗(b.example.com),也可以用 window.opener 拿到開啟它的網頁(a.example.com)的 window,不過一樣只有部分操作是被允許的。
但是呢,如果這兩個網站是在同一個 subdomain 底下,而且你對兩個網站都有控制權,是可以透過更改 document.domain 來讓他們的 origin 相同的!
在 a.example.com,這樣子做:
// 新增這個,把 domain 設為 example.com
document.domain = 'example.com'
var win = window.open('http://b.example.com')
// 等新的頁面載入完成
setTimeout(() => {
console.log(win.secret) // 12345
}, 2000)在 b.example.com 裡面也需要做一樣的事情:
document.domain = 'example.com'
window.secret = 12345然後你就會神奇地發現,你現在可以拿到 b.example.com 的 window 了!而且幾乎是什麼操作都可以做。
更詳細的介紹可以參考 MDN:Document.domain,會這樣可能是有什麼歷史因素,但未來因為安全性的問題有可能會被拔掉就是了。
相關的 spec 可以參考:7.5.2 Relaxing the same-origin restriction
進入正題:其他各種 COXX 是什麼?
前面這兩個其實都只是小菜而已,並不是這一篇著重的主題。這一篇最想跟大家分享的其實是:
- CORB(Cross-Origin Read Blocking)
- CORP(Cross-Origin Resource Policy)
- COEP(Cross-Origin-Embedder-Policy)
- COOP(Cross-Origin-Opener-Policy)
這幾個東西。
開頭我有提過了,這幾個東西沒有好好講的話很容易搞混,所以我會用我自己覺得可能比較好懂的方式來講解,接下來就開始吧。
嚴重的安全漏洞:Meltdown 與 Spectre
在 2018 年 1 月 3 號,Google 的 Project Zeror 對外發布了一篇名為:Reading privileged memory with a side-channel 的文章,裡面講述了三種針對 CPU data cache 的攻擊:
- Variant 1: bounds check bypass (CVE-2017-5753)
- Variant 2: branch target injection (CVE-2017-5715)
- Variant 3: rogue data cache load (CVE-2017-5754)
而前兩種又被稱為 Spectre,第三種被稱為是 Meltdown。如果你有印象的話,在當時這可是一件大事,因為問題是出在 CPU,而且並不是個容易修復的問題。
而這個漏洞的公佈我覺得對於瀏覽器的運作機制有滿大的影響(或至少加速了瀏覽器演進的過程),尤其是 spectre 可以拿來攻擊瀏覽器,而這當然也影響了這系列的主題:跨來源資源存取。
因此,稍微理解一下 Spectre 在幹嘛我覺得是很有必要的。如果想要完全理解這個攻擊,需要有滿多的背景知識,但這不是這一篇主要想講的東西,因此底下我會以非常簡化的模型來解釋 Spectre,想要完全理解的話可以參考上面的連結。
超級簡化版的 Spectre 攻擊解釋
再次強調,這是為了方便理解所簡化過的版本,跟原始的攻擊有一定出入,但核心概念應該是類似的。
假設現在有一段程式碼(C 語言)長這樣子:
uint8_t arr1[16] = {1, 2, 3};
uint8_t arr2[256];
unsigned int array1_size = 16;
void run(size_t x) {
if(x < array1_size) {
uint8_t y = array2[array1[x]];
}
}
size_t x = 1;
run(x);我宣告了兩個陣列,型態是 uint8_t,所以每個陣列的元素大小都會是 1 個 byte(8 bit)。而 arr1 的長度是 16,arr2 的長度是 256。
接下來我有一個 function 叫做 run,會吃一個數字 x,然後判斷 x 是不是比 array1_size 小,是的話我就先把 array1[x] 的值取出來,然後作為索引去存取 array2,再把拿到的值給 y。
以上面的例子來說,run(1) 的話,就會執行:
uint8_t y = array2[array1[1]];而 array1[1] 的值是 2,所以就是 y = array2[2]。
這段程式碼看起來沒什麼問題,而且我有做了陣列長度的判斷,所以不會有超出陣列索引(Out-of-Bounds,簡稱 OOB)的狀況發生,只有在 x 比 array1_size 小的時候才會繼續往下執行。
不過這只是你看起來而已。
在 CPU 執行程式碼的時候,有一個機制叫做 branch prediction。為了增進程式碼執行的效率,所以 CPU 在執行的時候如果碰到 if 條件,會先預測結果是 true 還是 false,如果預測的結果是 true,就會先幫你執行 if 裡面的程式碼,把結果先算出來。
剛剛講的都只是「預測」,等到實際的 if 條件執行完之後,如果跟預測的結果相同,那就皆大歡喜,如果不同的話,就會把剛剛算完的結果丟掉,這個機制稱為:預測執行(speculatively execute)
因為 CPU 會把結果丟掉,所以我們也拿不到預測執行的結果,除非 CPU 有留下一些線索。
而這就是 Spectre 攻擊成立的主因,因為還真的有留下線索。
一樣是為了增進執行的效率,在預測執行的時候會把一些結果放到 CPU cache 裡面,增進之後讀取資料的效率。
假設現在有 ABC 三個東西,一個在 CPU cache 裡面,其他兩個都不在,我們要怎麼知道是哪一個在?
答案是,透過存取這三個東西的時間!因為在 CPU cache 裡面的東西讀取一定比較快,所以如果讀取 A 花了 10ms,B 花了 10ms,C 只花了 1ms,我們就知道 C 一定是在 CPU cache 裡面。這種透過其他線索來得知資訊的攻擊方法,叫做 side-channel attack,從其他管道來得知資訊。
上面的方法我們透過時間來判斷,所以又叫做 timing-attack。
結合上述知識之後,我們再回來看之前那段程式碼:
uint8_t arr1[16] = {1, 2, 3};
uint8_t arr2[256];
unsigned int array1_size = 16;
void run(size_t x) {
if(x < array1_size) {
uint8_t y = array2[array1[x]];
}
}
size_t x = 1;
run(x);假設現在我跑很多次 run(10),CPU 根據 branch prediction 的機制,合理推測我下一次也會滿足 if 條件,執行到裡面的程式碼。就在這時候我突然把 x 設成 100,跑了一個 run(100)。
這時候 if 裡面的程式碼會被預測執行:
uint8_t y = array2[array1[100]];假設 array1[100] 的值是 38 好了,那就是 y = array2[38],所以 array2[38] 會被放到 CPU cache 裡面,增進之後載入的效率。
接著實際執行到 if condition 發現條件不符合,所以把剛剛拿到的結果丟掉,什麼事都沒發生,function 執行完畢。
然後我們根據剛剛上面講的 timing attack,去讀取 array2 的每一個元素,並且計算時間,會發現 array2[38] 的讀取時間最短。
這時候我們就知道了一件事:
array1[100] 的內容是 38
你可能會問說:「那你知道這能幹嘛?」,能做的事情可多了。array1 的長度只有 16,所以我讀取到的值並不是 array1 本身的東西,而是其他部分的記憶體,是我不應該存取到的地方。而我只要一直複製這個模式,就能把其他地方的資料全都讀出來。
這個攻擊如果放在瀏覽器上面,我就能讀取同一個 process 的其他資料,換句話說,如果同一個 process 裡面有其他網站的內容,我就能讀取到那個網站的內容!
這就是 Spectre 攻擊,透過 CPU 的一些機制來進行 side-channal attack,進而讀取到本來不該讀到的資料,造成安全性問題。
所以用一句白話文解釋,在瀏覽器上面,Spectre 可以讓你有機會讀取到其他網站的資料。
有關 Spectre 的解釋就到這裡了,上面簡化了很多細節,而那些細節我其實也沒有完全理解,想知道更多的話可以參考:
- Reading privileged memory with a side-channel
- 解读 Meltdown & Spectre CPU 漏洞
- 浅谈处理器级Spectre Attack及Poc分析
- [閒聊] Spectre & Meltdown漏洞概論(翻譯)
- Spectre漏洞示例代码注释
- Google update: Meltdown/Spectre
- Mitigating Spectre with Site Isolation in Chrome
而那些 COXX 的東西,目的都是差不多的,都是要防止一個網站能夠讀取到其他網站的資料。只要不讓惡意網站跟目標網站處在同一個 process,這類型的攻擊就失效了。
從這個角度出發,我們來看看各種相關機制。
CORB(Cross-Origin Read Blocking)
Google 於 Spectre 攻擊公開的一個月後,也就是 2018 年 2 月,在部落格上面發了一篇文章講述 Chrome 做了哪些事情來防堵這類型的攻擊:Meltdown/Spectre。
文章中的 Cross-Site Document Blocking 就是 CORB 的前身。根據 Chrome Platform Status,在 Chrome for desktop release 67 的時候正式預設啟用,那時候大概是 2018 年 5 月,也差不多那個時候,被 merge 進去 fetch 的 spec,成為規格的一部分(CORB: blocking of nosniff and 206 responses)。
前面有提到過 Spectre 能夠讀取到同一個 process 底下的資料,所以防禦的其中一個方式就是不要讓其他網站的資料出現在同一個 process 底下。
一個網站有許多方式可以把跨來源的資源設法弄進來,例如說 fetch 或是 xhr,但這兩種已經被 CORS 給控管住了,而且拿到的 response 應該是存在 network 相關的 process 而不是網站本身的 process,所以就算用 Spectre 也讀不到。
但是呢,用 <img> 或是 <script> 這些標籤也可以輕易地把其他網站的資源載入。例如說:<img src="https://bank.com/secret.json">,假設 secret.json 是個機密的資料,我們就可以把這個機密的資料給「載入」。
你可能會好奇說:「這樣做有什麼用?那又不是一張圖片,而且我用 JS 也讀取不到」。沒錯,這不是一張圖片,但以 Chrome 的運作機制來說,Chrome 在下載之前不知道它不是圖片(有可能副檔名是 .json 但其實是圖片對吧),因此會先下載,下載之後把結果丟進 render process,這時候才會知道這不是一張圖片,然後引發載入錯誤。
看起來沒什麼問題,但別忘了 Spectre 開啟了一扇新的窗,那就是「只要在同一個 process 的資料我都有機會讀取到」。因此光是「把結果丟進 render process」這件事情都不行,因為透過 Spectre 攻擊,攻擊者還是拿得到存在記憶體裡面的資料。
因此 CORB 這個機制的目的就是:
如果你想讀的資料類型根本不合理,那我根本不需要把讀到 render process,我直接把結果丟掉就好!
延續上面的例子,那個 json 檔的 MIME type 如果是 application/json,代表它絕對不會是一張圖片,因此也不可能放到 img 標籤裡面,這就是我所說的「讀的資料類型不合理」。
CORB 主要保護的資料類型有三種:HTML、XML 跟 JSON,那瀏覽器要怎麼知道是這三種類型呢?不如就從 response header 的 content type 判斷吧?
很遺憾,沒辦法。原因是有很多網站的 content type 是設定錯誤的,有可能明明就是 JavaScript 檔案卻設成 text/html,就會被 CORB 擋住,網站就會壞掉。
因此 Chrome 會根據內容來探測(sniffing)檔案類型是什麼,再決定要不要套用 CORB。
但這其實也有誤判的可能,所以如果你的伺服器給的 content type 都確定是正確的,可以傳一個 response header 是 X-Content-Type-Options: nosniff,Chrome 就會直接用你給的 content type 而不是自己探測。

總結一下,CORB 是個已經預設在 Chrome 裡的機制,會自動阻擋不合理的跨來源資源載入,像是用 <img> 來載入 json 或是用 <script> 載入 HTML 等等。而除了 Chrome 之外,Safari 跟 Firefox 好像都還沒實裝這個機制。
更詳細的解釋可以參考:
CORP(Cross-Origin Resource Policy)
CORB 是瀏覽器內建的機制,自動保護了 HTML、XML 與 JSON,不讓他們被載入到跨來源的 render process 裡面,就不會被 Spectre 攻擊。但是其他資源呢?如果其他類型的資源,例如說有些照片跟影片可能也是機密資料,我可以保護他們嗎?
這就是 CORP 這個 HTTP response header 的功能。CORP 的前身叫做 From-Origin,下面引用一段來自 Cross-Origin-Resource-Policy (was: From-Origin) #687 的敘述:
Cross-Origin Read Blocking (CORB) automatically protects against Spectre attacks that load cross-origin, cross-type HTML, XML, and JSON resources, and is based on the browser’s ability to distinguish resource types. We think CORB is a good idea. From-Origin would offer servers an opt-in protection beyond CORB.
如果你自己知道該保護哪些資源,那就可以用 CORP 這個 header,指定這些資源只能被哪些來源載入。CORP 的內容有三種:
- Cross-Origin-Resource-Policy:
same-site - Cross-Origin-Resource-Policy:
same-origin - Cross-Origin-Resource-Policy:
cross-origin
第三種的話就跟沒有設定是差不多的(但其實跟沒設還是有差,之後會解釋),就是所有的跨來源都可以載入資源。接下來我們實際來看看設定這個之後會怎樣吧!
我們先用 express 起一個簡單的 server,加上 CORP 的 header 然後放一張圖片,圖片網址是 http://b.example.com/logo.jpg:
app.use((req, res, next) => {
res.header('Cross-Origin-Resource-Policy', 'same-origin')
next()
})
app.use(express.static('public'));接著在 http://a.example.com 引入這張圖片:
<img src="http://b.example.com/logo.jpg" />重新整理打開 console,就會看到圖片無法載入的錯誤訊息,打開 network tab 還會跟你詳細解釋原因:
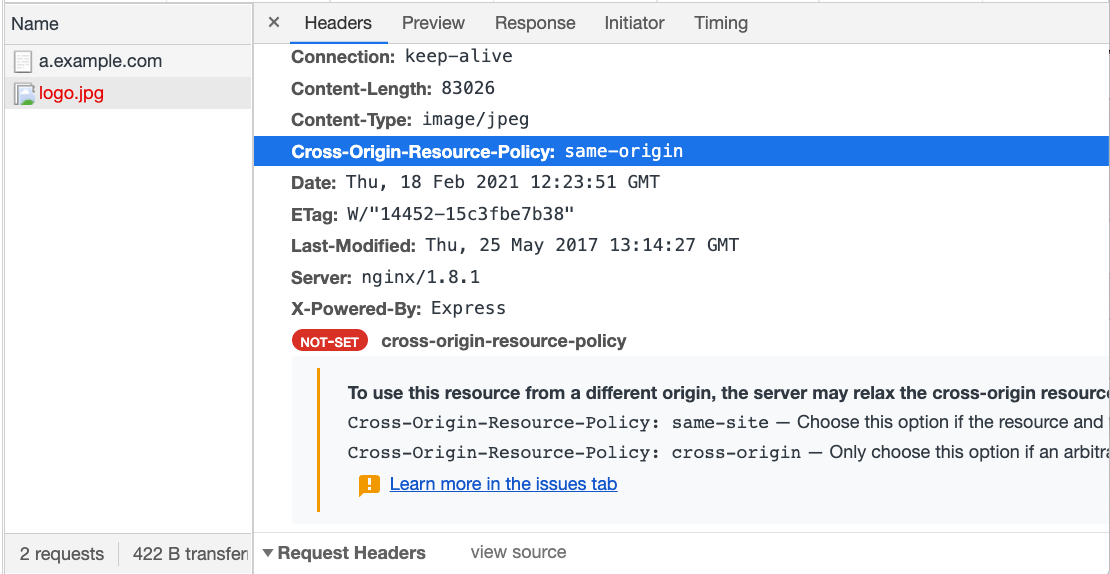
如果把 header 改成 same-site 或是 cross-origin,就可以看到圖片正確被載入。
所以這個 header 其實就是「資源版的 CORS」,原本的 CORS 比較像是 API 或是「資料」間存取的協議,讓跨來源存取資料需要許可。而資源的載入例如說使用 <img> 或是 <script>,想要阻止跨來源載入的話,應該是只能透過 server side 自行去判斷 Origin 或是 Referer 之類的值,動態決定是否回傳資料。
而 CORP 這個 header 出現之後,提供了阻止「任何跨來源載入」的方法,只要設定一個 header 就行了。所以這不只是安全性的考量而已,安全性只是其中一點,重點是你可以阻止別人載入你的資源。
就如同 CORP 的前身 From-Origin 的 spec 所寫到的:
The Web platform has no limitations on embedding resources from different origins currently. E.g. an HTML document on http://example.org can embed an image from http://corp.invalid without issue. This has led to a number of problems:
對於這種 embedded resource,基本上 Web 沒有任何限制,想載入什麼就載入什麼,雖然方便但也會造成一些問題,像是:
Inline linking — the practice of embedding resources (e.g. images or fonts) from another server, causing the owner of that server to get a higher hosting bill.
Clickjacking — embedding a resource from another origin and attempting to let the visitor click on a concealed link thereof, causing harm to the visitor.
例如說在我的部落格直接連到別人家的圖片,這樣流量就是別人家 server 的,帳單也是他要付。除此之外也會有 Clickjacking 的問題。
Privacy leakage — sometimes resource availability depends on whether a visitor is signed in to a particular website. E.g. only with a I’m-signed-in-cookie will an image be returned, and if there is no such cookie an HTML document. An HTML document embedding such a resource (requested with the user’s credentials) can figure out the existence of that resource and thus whether the visitor is signed in and therefore has an account with a particular service.
這個我之前有看過一個網站但找不到連結了,他可以得知你在某些網站是不是登入狀態。那他怎麼知道的呢?因為有些資源可能只有在你登入的時候有權限存取。假設某個圖片網址只有登入狀態下會正確回傳圖片,沒登入的話就會回傳 server error,那我只要這樣寫就好:
<img src=xxx onerror="alert('not login')" onload="alert('login')">透過圖片是否載入成功,就知道你是否登入。不過設定了 SameSite cookie 之後應該就沒這問題了。
License checking — certain font licenses require that the font be prevented from being embedded on other origins.
字型網站會阻止沒有 license 的使用者載入字型,這種狀況也很適合用這個 header。
總而言之呢,前面介紹的 CORB 只是「阻止不合理的讀取」,例如說用 img 載入 HTML,這純粹是為了安全性考量而已。
但是 CORP 則是可以阻止任何的讀取(除了 iframe,對 iframe 沒作用),可以保護你網站的資源不被其他人載入,是功能更強大而且應用更廣泛的一個 header。
現在主流的瀏覽器都已經支援這個 header 了。
Site Isolation
要防止 Spectre 攻擊,有兩條路線:
- 不讓攻擊者有機會執行 Spectre 攻擊
- 就算執行攻擊,也拿不到想要的資訊
前面有提過 Spectre 攻擊的原理,透過讀取資料的時間差得知哪一個資料被放到 cache 裡面,就可以從記憶體裡面「偷」資料出來。那如果瀏覽器上面提供的計時器時間故意不精準的話,不就可以防禦了嗎?因為攻擊者算出來的秒數會差不多,根本不知道哪一個讀取比較快。
Spectre 攻擊出現之後瀏覽器做了兩件事:
- 降低
performance.now的精準度 - 停用
SharedArrayBuffer
第一點很好理解,降低拿時間函式的精準度,就可以讓攻擊者無法判斷正確的讀取速度。那第二點是為什麼呢?
先講一下 SharedArrayBuffer 這東西好了,這東西可以讓你 document 的 JS 跟 web worker 共用同一塊記憶體,共享資料。所以在 web worker 裡面你可以做一個 counter 一直累加,然後在 JS 裡面讀取這個 counter,就達成了計時器的功能。
所以 Spectre 出現之後,瀏覽器就做了這兩個調整,從「防止攻擊源頭」的角度下手,這是第一條路。
而另一條路則是不讓惡意網站拿到跨來源網站的資訊,就是前面所提到的 CORB,以及現在要介紹的:Site Isolation。
先來一段來自 Site Isolation for web developers 的介紹:
Site Isolation is a security feature in Chrome that offers an additional line of defense to make such attacks less likely to succeed. It ensures that pages from different websites are always put into different processes, each running in a sandbox that limits what the process is allowed to do. It also blocks the process from receiving certain types of sensitive data from other sites
簡單來說呢,Site Isolation 會確保來自不同網站的資源會放在不同的 process,所以就算你在自己的網站執行了 Spectre 攻擊也沒關係,因為你讀不到其他網站的資料。
Site Isolation 目前在 Chrome 是預設啟用的狀態,相對應的缺點是使用的記憶體會變多,因為開了更多的 process,其他的影響可以參考上面那篇文章。
而除了 Site Isolation 之外,還有另外一個很容易搞混的東西(我在寫這篇的時候本來以為是一樣的,後來才驚覺原來不同),叫做:「cross-origin isolated state」。
這兩者的差別在哪裡呢?根據我自己的理解(不保證完全正確),在 Mitigating Spectre with Site Isolation in Chrome 這篇文章中有提到:
Note that Chrome uses a specific definition of “site” that includes just the scheme and registered domain. Thus, https://google.co.uk would be a site, and subdomains like https://maps.google.co.uk would stay in the same process.
Site Isolation 的 “Site” 的定義就跟 same site 一樣,http://a.example.com 跟 http://b.example.com 是 same site,所以儘管在 Site Isolation 的狀況下,這兩個網頁還是會被放在同一個 process 裡面。
而 cross-origin isolated state 應該是一種更強的隔離,只要不是 same origin 就隔離開來,就算是 same site 也一樣。因此 http://a.example.com 跟 http://b.example.com 是會被隔離開來的。而且 Site Isolation 隔離的對象是 process,cross-origin isolated 看起來是隔離 browsing context group,不讓跨來源的東西處在同一個 browsing context group。
而這個 cross-origin isolated state 並不是預設的,你必須在你的網頁上設置這兩個 header 才能啟用:
- Cross-Origin-Embedder-Policy: require-corp
- Cross-Origin-Opener-Policy: same-origin
至於為什麼是這兩個,待會告訴你。
COEP(Cross-Origin-Embedder-Policy)
要達成 cross-origin isolated state 的話,必須保證你對於自己網站上所有的跨來源存取,都是合法的並且有權限的。
COEP(Cross-Origin-Embedder-Policy)這個 header 有兩個值:
- unsafe-none
- require-corp
第一個是預設值,就是沒有任何限制,第二個則是跟我們前面提到的 CORP(Cross-Origin-Resource-Policy) 有關,如果用了這個 require-corp 的話,就代表告訴瀏覽器說:「頁面上所有我載入的資源,都必須有 CORP 這個 header 的存在(或是 CORS),而且是合法的」
現在假設我們有個網站 a.example.com,我們想讓它變成 cross-rogin isolated state,因此幫他加上一個 header:Cross-Origin-Embedder-Policy: require-corp,然後網頁裡面引入一個資源:
<img src="http://b.example.com/logo.jpg">接著我們在 b 那邊傳送正確的 header:
app.use((req, res, next) => {
res.header('Cross-Origin-Resource-Policy', 'cross-origin')
next()
})如此一來就達成了第一步。
另外,前面我有講過 CORP 沒有設跟設定成 cross-origin 有一個細微的差異,就是差在這邊。上面的範例如果 b 那邊沒有送這個 header,那 Embedder Policy 就不算通過。
COOP(Cross-Origin-Opener-Policy)
而第二步則是這個 COOP(Cross-Origin-Opener-Policy)的 header,在上面的時候我有說過當你用 window.open 開啟一個網頁的時候,你可以操控那個網頁的 location;而開啟的網頁也可以用 window.opener 來操控你的網頁。
而這樣子讓 window 之間有關連,就不符合跨來源的隔離。因此 COOP 這個 header 就是來規範 window 跟 opener 之間的關係,一共有三個值:
- Cross-Origin-Opener-Policy:
unsafe-none - Cross-Origin-Opener-Policy:
same-origin - Cross-Origin-Opener-Policy:
same-origin-allow-popups
第一個就是預設值,不解釋,因為沒什麼作用。
第二個最嚴格,如果你設定成 same-origin 的話,那「被你開啟的 window」也要有這個 header,而且也要設定成 same-origin,你們之間才能共享 window。
底下我們來做個實驗,我們有兩個網頁:
page1.html 的內容如下:
<script>
var win = window.open('http://localhost:5566/page2.html')
setTimeout(() => {
console.log(win.secret)
}, 2000)
</script>page2.html 的內容如下:
<script>
window.secret = 5566
</script>測驗的方式很簡單,如果 page1 成功輸出 5566,代表兩個之間有共享 window。否之則否。
先來試試看不加任何 header 吧!由於這兩個是 same origin,因此本來就可以共享 window,成功印出了 5566。
接下來我們把 server 端的程式碼改成這樣:
app.use((req, res, next) => {
if (req.url === '/page1.html') {
res.header('Cross-Origin-Opener-Policy', 'same-origin')
}
next()
})只有 page1.html 有 COOP,page2.html 沒有,實驗的結果是:「無法共享」。就算改成這樣:
app.use((req, res, next) => {
if (req.url === '/page1.html') {
res.header('Cross-Origin-Opener-Policy', 'same-origin')
}
if (req.url === '/page2.html') {
res.header('Cross-Origin-Opener-Policy', 'same-origin-allow-popups')
}
next()
})也是無法共享,因為 same-origin 的條件就是:
- 開啟的 window 要在同一個 origin
- 開啟的 window 的 response header 要有 COOP,而且值一定要是
same-origin
只有符合這兩點,才能成功存取到完整的 window。而且有一點要特別注意,那就是一旦設定了這個 header 但是沒有符合規則,不只存取不到完整的 window,連之前那什麼 openedWindow.close 跟 window.opener 都會拿不到,兩個 window 之間就是徹徹底底沒關聯了。
再來 same-origin-allow-popups 的條件比較寬鬆,只有:
- 開啟的 window 要在同一個 origin
- 開啟的 window 沒有 COOP,或是 COOP 的值不是 same-origin
簡單來說,same-origin 不只保護他人也保護自己,當你設定成這個值的時候,無論你是 open 別人的,或是被 open 的,都一定要是 same origin 然後有相同的 header,才能互相存取 window。
舉一個例子,我調整成這樣:
app.use((req, res, next) => {
if (req.url === '/page1.html') {
res.header('Cross-Origin-Opener-Policy', 'same-origin-allow-popups')
}
next()
})只有 page1 有設定 same-origin-allow-popups,page2 什麼都沒設定,這種狀況可以互相存取 window。
接下來如果兩個一樣的話:
app.use((req, res, next) => {
if (req.url === '/page1.html') {
res.header('Cross-Origin-Opener-Policy', 'same-origin-allow-popups')
}
if (req.url === '/page2.html') {
res.header('Cross-Origin-Opener-Policy', 'same-origin-allow-popups')
}
next()
})這也可以,沒什麼問題。
那如果是這樣呢?
app.use((req, res, next) => {
if (req.url === '/page1.html') {
res.header('Cross-Origin-Opener-Policy', 'same-origin-allow-popups')
}
if (req.url === '/page2.html') {
res.header('Cross-Origin-Opener-Policy', 'same-origin')
}
next()
})這樣子就不行。
所以稍微總結一下,假設現在有一個網頁 A 用 window.open 開啟了一個網頁 B:
- 如果 AB 是 cross-origin,瀏覽器本來就有限制,只能存取
window.location或是window.close之類的方法。沒辦法存取 DOM 或其他東西 - 如果 AB 是 same-origin,那他們可以互相存取幾乎完整的 window,包括 DOM。
- 如果 A 加上 COOP header,而且值是
same-origin,代表針對第二種情況做了更多限制,只有 B 也有這個 header 而且值也是same-origin的時候才能互相存取 window。 - 如果 A 加上 COOP header,而且值是
same-origin-allow-popups,也是對第二種情況做限制只是比較寬鬆,只要 B 的 COOP header 不是same-origin就可以互相存取 window。
總之呢,要「有機會互相存取 window」,一定要先是 same origin,這點是不會變的。實際上是不是存取的到,就要看有沒有設定 COOP header 以及 header 的值。而如果有設定 COOP header 但不符合規則,那 window.opener 會直接變成 null,你連 location 都拿不到(沒設定規則的話,就算是 cross origin 也拿得到)。
其實根據 spec 還有第四種:same-origin-plus-COEP,但看起來更複雜就先不研究了。
再回到 cross-origin isolated state
前面提到了 cross-origin isolated state 需要設置這兩個 header:
- Cross-Origin-Embedder-Policy: require-corp
- Cross-Origin-Opener-Policy: same-origin
為什麼呢?因為一旦設置了,就代表頁面上所有的跨來源資源都是你有權限存取的,如果沒有權限的話會出錯。所以如果設定而且通過了,就代表跨來源資源也都允許你存取,就不會有安全性的問題。
在網站上可以用:
self.crossOriginIsolated來判定自己是不是進入 cross-origin isolated state。是的話就可以用一些被封印(?)的功能,因為瀏覽器知道你很安全。
另外,如果進入了這個狀態,一開始講過的透過修改 document.domain 繞過 same-origin policy 的招數就不管用了,瀏覽器就不會讓你修改這個東西了。
想知道更多 COOP 與 COEP 還有 cross-origin isolated state,可以參考:
- Making your website “cross-origin isolated” using COOP and COEP
- Why you need “cross-origin isolated” for powerful features
- COEP COOP CORP CORS CORB - CRAP that’s a lot of new stuff!
- Making postMessage() work for SharedArrayBuffer (Cross-Origin-Embedder-Policy) #4175
- Restricting cross-origin WindowProxy access (Cross-Origin-Opener-Policy) #3740
- Feature: Cross-Origin Resource Policy
總結
這篇其實講了不少東西,都是圍繞著安全性在打轉。一開始我們講了 CORS 設定錯誤會造成的結果以及防禦方法,接著講了透過修改 document.cookie 讓 same-site 變成 same-origin(要兩個網站都同意這樣做才行),最後則是這篇的重頭戲:
- CORB(Cross-Origin Read Blocking)
- CORP(Cross-Origin Resource Policy)
- COEP(Cross-Origin-Embedder-Policy)
- COOP(Cross-Origin-Opener-Policy)
在找資料的時候花了不少時間,因為名字太像而且功能有些其實有點類似,但看久了其實就會發現差滿多的,每一個 policy 所注重的地方都不同。希望我整理過後的脈絡有幫助大家更好理解這些東西。
如果要用一段話總結這四個東西的話,或許是:
- CORB:瀏覽器預設的機制,主要是防止載入不合理的資源,像是用 img 載入 HTML
- CORP:是一個 HTTP response header,決定這個資源可以被誰載入,可以防止 cross-origin 載入圖片、影片或任何資源
- COEP:是一個 HTTP response header,確保頁面上所有的資源都是合法載入的
- COOP:是一個 HTTP response header,幫 same-origin 加上更嚴格的 window 共享設定
相對於其他幾篇,我對這篇的內容沒有這麼熟悉,如果有哪邊有講錯麻煩不吝指教,感謝。
再來,下一篇就是是這系列文的最後一篇了:CORS 完全手冊(六):總結、後記與遺珠
評論