Introduction
In the previous articles, we learned that the CORS protocol is essentially a security protocol. In addition to CORS, there are actually a series of things related to cross-origin, such as:
- CORB (Cross-Origin Read Blocking)
- CORP (Cross-Origin Resource Policy)
- COEP (Cross-Origin-Embedder-Policy)
- COOP (Cross-Origin-Opener-Policy)
Doesn’t just seeing this series of similar terms make you dizzy? Yes, me too. In the process of organizing this information, I found that the security issues related to cross-origin are more complicated than I thought, but after spending some time organizing them, I found that there is still a logical sequence to follow. Therefore, this article will explain why these things appear in a context that I think should be easier to understand.
In addition to the various COXX things mentioned above, there are other cross-origin related security issues that I want to mention in this article.
Before we continue, I would like to remind everyone that this article is about “security issues of cross-origin”, not just “security issues of CORS”. The things protected by the CORS protocol and their content have been introduced before. What this article is going to talk about is actually somewhat deviating from the main title “CORS” complete guide, because this is not very related to the CORS protocol, but rather raises the level again and talks about “cross-origin” itself.
So when you read the following things, don’t confuse them with CORS. Except for the first thing to be discussed later, the others are not very related to CORS.
CORS misconfiguration
If you still remember, I mentioned earlier that if a cross-origin request wants to carry a cookie, Access-Control-Allow-Origin cannot be *, but must specify a single origin, otherwise the browser will not pass it.
But the reality is that we cannot have only one origin. We may have many origins, such as buy.example.com, social.example.com, note.example.com, all of which need to access api.example.com. At this time, we cannot hard-code the origin in the response header, but must adjust it dynamically.
Let’s talk about the worst way first, like this:
app.use((req, res, next) => {
res.headers['Access-Control-Allow-Credentials'] = 'true'
res.headers['Access-Control-Allow-Origin'] = req.headers['Origin']
})For convenience, the origin in the request header is directly mapped. By doing so, it actually means that any origin can pass the CORS check.
What problems will this cause?
The problem is huge.
Assuming that I make a phishing website today, the URL is http://fake-example.com, and I try to make the user click on this website, and the phishing website writes a script:
// 用 api 去拿使用者資料,並且帶上 cookie
fetch('http://api.example.com/me', {
credentials: 'include'
})
.then(res => res.text())
.then(res => {
// 成功拿到使用者資料,我可以傳送到我自己的 server
console.log(res)
// 把使用者導回真正的網站
window.location = 'http://example.com'
})I use fetch to request http://api.example.com/me to get data and carry cookies. Then, because the server will always respond with the correct header, the CORS check will pass and I will get the data.
Therefore, this attack will be successful as long as the user clicks on the phishing website and is logged in to example.com. As for the scope of influence, it depends on the website’s api. The most basic thing is to only get user data, and more serious things may be able to get user tokens (if there is this api).
There are several things to note about this attack:
- This is not XSS, because I did not execute code on
example.com, but executed it on my own phishing websitehttp://fake-example.com. - This is somewhat like CSRF, but the website usually does not add CSRF token protection to GET APIs, so it can pass.
- If SameSite cookie is set, the attack will fail because the cookie cannot be carried.
Therefore, there are several prerequisites for this attack to succeed:
- The CORS header is given to the wrong origin.
- The website uses cookies for identity authentication and does not set SameSite.
- The user actively clicks on the phishing website and is logged in.
Regarding the first point, no one may write like me above, directly using the origin in the request header. The more likely approach is like this:
app.use((req, res, next) => {
res.headers['Access-Control-Allow-Credentials'] = 'true'
const origin = req.headers['Origin']
// 偵測是不是 example.com 結尾
if (/example\.com$/.test(origin)) {
res.headers['Access-Control-Allow-Origin'] = origin
}
})In this way, the origins below can all pass:
- example.com
- buy.example.com
- social.example.com
However, writing like this is problematic because it can also pass:
- fakeexample.com
This type of vulnerability is caused by incorrect CORS settings, so it is called CORS misconfiguration.
The solution is not to use RegExp for judgment, but to prepare a list in advance. Only those that appear in the list pass, otherwise they all fail. In this way, it can be ensured that there are no vulnerabilities in the judgment, and remember to add the SameSite attribute to the cookie.
const allowOrigins = [
'example.com',
'buy.example.com',
'social.example.com'
]
app.use((req, res, next) => {
res.headers['Access-Control-Allow-Credentials'] = 'true'
const origin = req.headers['Origin']
if (allowOrigins.includes(origin)) {
res.headers['Access-Control-Allow-Origin'] = origin
}
})For more information, please refer to:
- 3 Ways to Exploit Misconfigured Cross-Origin Resource Sharing (CORS)
- JetBrains IDE Remote Code Execution and Local File Disclosure
- AppSec EU 2017 Exploiting CORS Misconfigurations For Bitcoins And Bounties by James Kettle
Bypass Same-origin Policy?
In addition to CORS, Same-origin policy actually appears in various places in the browser, such as window.open and iframe. When you use window.open to open a webpage, the return value will be the window of the new webpage (more precisely, it is WindowProxy, you can refer to MDN: Window.open()), but only in the same origin. Accessible, if it is not the same origin, only a small part of things can be accessed.
Assuming that I am now in a.example.com, and then wrote this script:
var win = window.open('http://b.example.com')
// 等新的頁面載入完成
setTimeout(() => {
console.log(win)
}, 2000)Use window.open to open b.example.com, and then go to access the window of b.example.com after the page is loaded.
After execution, you will see an error message in the console:

Because a.example.com and b.example.com are cross-origin, the window cannot be accessed. This specification is actually very reasonable, because if you can access the window, you can actually do a lot of things, so it is limited to being able to get the window only under the same origin.
However, the statement “cannot access the window” is not very accurate, because even if it is cross-origin, there are still some operations that are allowed, such as:
var win = window.open('http://b.example.com')
// 等新的頁面載入完成
setTimeout(() => {
// 變更開啟的 window 的位置
win.location = 'https://google.com'
setTimeout(() => {
// 關閉視窗
win.close()
}, 2000)
}, 2000)Can change the location of the opened window and close the opened window.
On the other hand, as the opened window (b.example.com), you can also use window.opener to get the window of the webpage (a.example.com) that opened it, but only some operations are allowed.
However, if these two websites are under the same subdomain and you have control over both websites, you can make their origins the same by changing document.domain!
In a.example.com, do this:
// 新增這個,把 domain 設為 example.com
document.domain = 'example.com'
var win = window.open('http://b.example.com')
// 等新的頁面載入完成
setTimeout(() => {
console.log(win.secret) // 12345
}, 2000)In b.example.com, you also need to do the same thing:
document.domain = 'example.com'
window.secret = 12345Then you will magically find that you can now get the window of b.example.com! And almost everything can be done.
For more detailed introduction, please refer to MDN: Document.domain. This may be due to historical factors, but it may be removed in the future due to security issues.
You can refer to the related spec: 7.5.2 Relaxing the same-origin restriction
Let’s get to the point: What are the other COXXs?
The first two are just small potatoes and not the main focus of this article. What I really want to share with you are:
- CORB (Cross-Origin Read Blocking)
- CORP (Cross-Origin Resource Policy)
- COEP (Cross-Origin-Embedder-Policy)
- COOP (Cross-Origin-Opener-Policy)
I will explain these things in a way that I think is easier to understand, as they can be easily confused if not explained properly.
Serious Security Vulnerabilities: Meltdown and Spectre
On January 3, 2018, Google’s Project Zero released an article titled Reading privileged memory with a side-channel, which described three attacks on CPU data cache:
- Variant 1: bounds check bypass (CVE-2017-5753)
- Variant 2: branch target injection (CVE-2017-5715)
- Variant 3: rogue data cache load (CVE-2017-5754)
The first two are called Spectre, and the third is called Meltdown. This was a big deal at the time because the problem was with the CPU and was not an easy fix.
The disclosure of this vulnerability had a significant impact on the operation of browsers (or at least accelerated the evolution of browsers), especially since Spectre can be used to attack browsers, which of course also affects this series of topics: Cross-Origin Resource Sharing.
Therefore, it is necessary to understand what Spectre is doing. If you want to fully understand this attack, you need a lot of background knowledge, but this is not the main topic of this article. Therefore, I will explain Spectre in a very simplified model below. If you want to fully understand it, you can refer to the link above.
Super Simplified Explanation of Spectre Attack
Again, this is a simplified version for easy understanding, and there are some differences from the original attack, but the core concept should be similar.
Assume that there is a piece of code (in C language) that looks like this:
uint8_t arr1[16] = {1, 2, 3};
uint8_t arr2[256];
unsigned int array1_size = 16;
void run(size_t x) {
if(x < array1_size) {
uint8_t y = array2[array1[x]];
}
}
size_t x = 1;
run(x);I declared two arrays, both of type uint8_t, so each element of the array will be 1 byte (8 bits) in size. The length of arr1 is 16, and the length of arr2 is 256.
Next, I have a function called run, which takes a number x, and checks if x is less than array1_size. If it is, I first take the value of array1[x], then use it as an index to access array2, and assign the obtained value to y.
For example, if run(1) is executed, the following code will be executed:
uint8_t y = array2[array1[1]];And the value of array1[1] is 2, so it is y = array2[2].
This code looks fine, and I have done the length check of the array, so there will be no Out-of-Bounds (OOB) situation, only when x is less than array1_size will it continue to execute.
However, this is just what you see.
When the CPU executes the code, there is a mechanism called branch prediction. In order to improve the efficiency of code execution, if the CPU encounters an if condition during execution, it will first predict whether the result is true or false. If the predicted result is true, it will first execute the code inside the if statement and calculate the result.
All of the above are just “predictions”. After the actual if condition is executed, if the result is the same as the predicted result, everything is fine. If it is different, the result just calculated will be discarded. This mechanism is called speculative execution.
Because the CPU discards the result, we cannot get the result of speculative execution unless the CPU leaves some clues.
And this is the main reason why the Spectre attack is successful, because there are indeed clues left.
To improve execution efficiency, some results are placed in the CPU cache during speculative execution to improve the efficiency of subsequent data reads.
Assuming there are three things, ABC, and one is in the CPU cache while the other two are not, how do we know which one is in the cache? The answer is by accessing these three things and measuring the time it takes to access them. Since the thing in the CPU cache is always accessed faster, if it takes 10ms to read A, 10ms to read B, and only 1ms to read C, we know that C must be in the CPU cache. This type of attack that obtains information through other clues is called a side-channel attack, which obtains information from other channels.
Using the timing-attack method mentioned above, we can now look back at the previous code:
uint8_t arr1[16] = {1, 2, 3};
uint8_t arr2[256];
unsigned int array1_size = 16;
void run(size_t x) {
if(x < array1_size) {
uint8_t y = array2[array1[x]];
}
}
size_t x = 1;
run(x);Suppose I run run(10) many times, and the CPU predicts that I will satisfy the if condition next time and execute the code inside it. At this point, I suddenly set x to 100 and run run(100).
The code inside the if statement will be predicted to execute:
uint8_t y = array2[array1[100]];Suppose the value of array1[100] is 38, then y = array2[38], so array2[38] will be placed in the CPU cache, improving the efficiency of subsequent loading.
Then, when actually executing the if condition, it is found that the condition is not met, so the result obtained is discarded, and nothing happens, and the function is executed.
Then, according to the timing attack mentioned above, we read each element of array2 and calculate the time, and find that the reading time of array2[38] is the shortest.
At this point, we know one thing:
The content of array1[100] is 38.
You may ask, “What can you do with this?” There are many things you can do. The length of array1 is only 16, so the value I read is not the thing in array1 itself, but the memory of other parts, which is the place I should not access. And as long as I keep copying this pattern, I can read all the data from other places.
If this attack is placed on a browser, I can read data from other websites in the same process. In other words, if there is content from other websites in the same process, I can read that content!
This is the Spectre attack, which uses some mechanisms of the CPU to perform side-channel attacks and read data that should not be read, causing security issues.
So, to put it simply, in a browser, Spectre can give you the opportunity to read data from other websites.
This is the explanation of Spectre. The above simplifies many details, and I do not fully understand those details. If you want to know more, you can refer to the following:
- Reading privileged memory with a side-channel
- 解读 Meltdown & Spectre CPU 漏洞
- 浅谈处理器级Spectre Attack及Poc分析
- [閒聊] Spectre & Meltdown漏洞概論(翻譯)
- Google update: Meltdown/Spectre
- Mitigating Spectre with Site Isolation in Chrome
All those COXX things have the same purpose, which is to prevent a website from being able to read data from other websites. As long as the malicious website and the target website are not in the same process, this type of attack will fail.
From this perspective, let’s take a look at various related mechanisms.
CORB (Cross-Origin Read Blocking)
A month after Google publicly announced the Spectre attack, in February 2018, they published a blog post explaining what Chrome did to prevent this type of attack: Meltdown/Spectre.
The Cross-Site Document Blocking mentioned in the article is the predecessor of CORB. According to the Chrome Platform Status, it was officially enabled by default in Chrome for desktop release 67, which was around May 2018. At that time, it was also merged into the fetch spec and became part of the specification (CORB: blocking of nosniff and 206 responses).
As mentioned earlier, Spectre can read data under the same process, so one way to defend against it is not to let data from other websites appear under the same process.
A website has many ways to bring in cross-origin resources, such as fetch or xhr, but these two have been controlled by CORS, and the response obtained should be stored in the network-related process rather than the website’s own process, so even with Spectre, it cannot be read.
However, using tags such as <img> or <script> can easily load resources from other websites. For example: <img src="https://bank.com/secret.json">, assuming that secret.json is confidential data, we can “load” this confidential data.
You may wonder, “What’s the point of doing this? It’s not an image, and I can’t even read it with JS.” That’s right, this is not an image, but in terms of Chrome’s operation mechanism, Chrome does not know that it is not an image before downloading it (it may have a file extension of .json but is actually an image), so it will download it first. After downloading, it will put the result into the render process. At this time, it will know that this is not an image and then trigger a loading error.
It seems that there is no problem, but don’t forget that Spectre has opened a new window, which is “I have the opportunity to read data in the same process.” Therefore, just “putting the result into the render process” is not enough, because through Spectre attacks, attackers can still get data stored in memory.
Therefore, the purpose of the CORB mechanism is:
If the data type you want to read is completely unreasonable, then I don’t need to put the result into the render process at all, I can just discard it!
Continuing with the example above, if the MIME type of that json file is application/json, it means that it cannot be an image at all, so it cannot be placed in the img tag. This is what I mean by “the data type you want to read is completely unreasonable.”
CORB mainly protects three types of data: HTML, XML, and JSON. How does the browser know that it is one of these three types? Why not judge from the content type in the response header?
Unfortunately, it is not possible. The reason is that the content type of many websites is set incorrectly. It may be a JavaScript file but set as text/html, which will be blocked by CORB and the website will break.
Therefore, Chrome will detect (sniffing) the file type based on the content and then decide whether to apply CORB.
But this may also cause misjudgments, so if the content type provided by your server is confirmed to be correct, you can pass a response header X-Content-Type-Options: nosniff, and Chrome will directly use the content type you provided instead of detecting it by itself.
In summary, CORB is a mechanism that is already enabled by default in Chrome, which automatically blocks unreasonable cross-origin resource loading, such as using <img> to load json or using <script> to load HTML, etc. In addition to Chrome, Safari and Firefox have not yet implemented this mechanism.
For more detailed explanations, please refer to:
- Cross-Origin Read Blocking for Web Developers
- Cross-Origin Read Blocking (CORB)
CORP (Cross-Origin Resource Policy)
CORB is a built-in mechanism in browsers that automatically protects HTML, XML, and JSON from being loaded into a cross-origin render process, preventing Spectre attacks. But what about other resources? If other types of resources, such as some photos and videos, are also confidential data, can I protect them?
This is where the CORP HTTP response header comes in. CORP, formerly known as From-Origin, is described in Cross-Origin-Resource-Policy (was: From-Origin) #687:
Cross-Origin Read Blocking (CORB) automatically protects against Spectre attacks that load cross-origin, cross-type HTML, XML, and JSON resources, and is based on the browser’s ability to distinguish resource types. We think CORB is a good idea. From-Origin would offer servers an opt-in protection beyond CORB.
If you know which resources to protect, you can use the CORP header to specify which sources can load these resources. There are three types of CORP content:
- Cross-Origin-Resource-Policy:
same-site - Cross-Origin-Resource-Policy:
same-origin - Cross-Origin-Resource-Policy:
cross-origin
The third type is similar to not setting it (but there is still a difference, which will be explained later), meaning that all cross-origin sources can load resources. Let’s see what happens after setting this up!
First, we use express to start a simple server, add the CORP header, and put a picture with the URL http://b.example.com/logo.jpg:
app.use((req, res, next) => {
res.header('Cross-Origin-Resource-Policy', 'same-origin')
next()
})
app.use(express.static('public'));Then, we import this picture at http://a.example.com:
<img src="http://b.example.com/logo.jpg" />After refreshing and opening the console, you will see an error message that the picture cannot be loaded, and opening the network tab will explain the reason in detail:
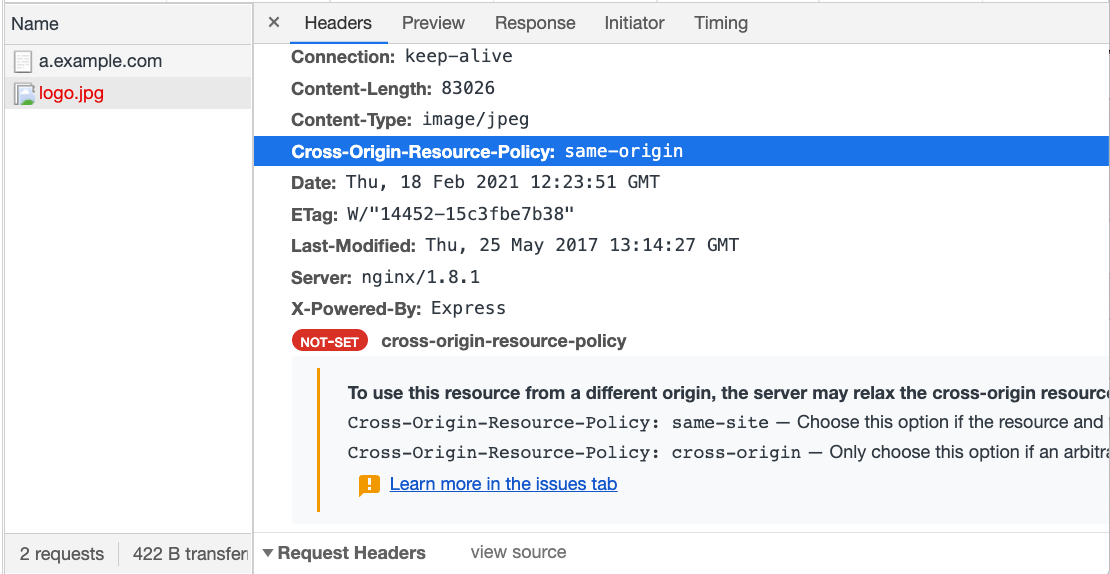
If the header is changed to same-site or cross-origin, the picture can be loaded correctly.
So this header is actually the “CORS for resources”. The original CORS is more like a protocol for accessing APIs or “data” between sources, requiring permission for cross-origin access to data. For resource loading, such as using <img> or <script>, if you want to prevent cross-origin loading, you should only judge the Origin or Referer values on the server side and dynamically determine whether to return data.
After the appearance of the CORP header, it provides a way to prevent “any cross-origin loading” by simply setting a header. So this is not just a security consideration, security is just one point, the key is that you can prevent others from loading your resources.
As the spec of CORP’s predecessor From-Origin states:
The Web platform has no limitations on embedding resources from different origins currently. E.g. an HTML document on http://example.org can embed an image from http://corp.invalid without issue. This has led to a number of problems:
For this type of embedded resource, the Web has no restrictions, and you can load whatever you want, which is convenient but also causes some problems, such as:
Inline linking — the practice of embedding resources (e.g. images or fonts) from another server, causing the owner of that server to get a higher hosting bill.
Clickjacking — embedding a resource from another origin and attempting to let the visitor click on a concealed link thereof, causing harm to the visitor.
For example, if I directly link to someone else’s image on my blog, the traffic will be on their server, and they will have to pay the bill. In addition, there may be Clickjacking issues.
Privacy leakage - sometimes resource availability depends on whether a visitor is signed in to a particular website. E.g. only with a I’m-signed-in-cookie will an image be returned, and if there is no such cookie an HTML document. An HTML document embedding such a resource (requested with the user’s credentials) can figure out the existence of that resource and thus whether the visitor is signed in and therefore has an account with a particular service.
I have seen a website before that can tell whether you are logged in to certain websites, but I can’t find the link now. How does it know? Because some resources may only be accessible when you are logged in. Suppose a certain image URL will only return the image correctly when logged in, and will return a server error if not logged in. Then I just need to write like this:
<img src=xxx onerror="alert('not login')" onload="alert('login')">By whether the image is loaded successfully, you can know whether you are logged in. However, after setting the SameSite cookie, this should not be a problem.
License checking - certain font licenses require that the font be prevented from being embedded on other origins.
Font websites will prevent users without a license from loading fonts, which is also suitable for this header.
In short, the CORB introduced earlier only “prevents unreasonable reading”, such as using img to load HTML, which is purely for security considerations.
But CORP can prevent any reading (except for iframe, which has no effect on iframe) and can protect your website’s resources from being loaded by others. It is a more powerful and widely used header.
Nowadays, mainstream browsers already support this header.
Site Isolation
There are two ways to prevent Spectre attacks:
- Don’t give attackers a chance to execute Spectre attacks
- Even if the attack is executed, the desired information cannot be obtained
The principle of Spectre attack was mentioned earlier. By knowing which data is placed in the cache by reading the time difference, data can be “stolen” from memory. If the timer provided on the browser intentionally is not accurate, can’t it be defended? Because the seconds calculated by the attacker will be similar, and they don’t know which reading is faster.
After the Spectre attack appeared, the browser did two things:
- Reduce the accuracy of
performance.now - Disable
SharedArrayBuffer
The first point is easy to understand. By reducing the accuracy of the time function, attackers cannot determine the correct reading speed. Why is the second point?
Let’s talk about SharedArrayBuffer first. This thing allows the JS of your document and web worker to share the same memory and share data. So in the web worker, you can make a counter that keeps adding up, and then read this counter in JS to achieve the function of a timer.
So after Spectre appeared, the browser made these two adjustments, starting from the perspective of “preventing the source of the attack”, which is the first way.
The other way is not to let malicious websites get information from cross-origin websites, which is the CORB mentioned earlier, and now to introduce: Site Isolation.
Here is an introduction from Site Isolation for web developers:
Site Isolation is a security feature in Chrome that offers an additional line of defense to make such attacks less likely to succeed. It ensures that pages from different websites are always put into different processes, each running in a sandbox that limits what the process is allowed to do. It also blocks the process from receiving certain types of sensitive data from other sites.
In short, Site Isolation ensures that resources from different websites are placed in different processes. Therefore, even if you execute a Spectre attack on your own website, it doesn’t matter because you cannot read data from other websites.
Site Isolation is currently enabled by default in Chrome, and the corresponding disadvantage is that more memory is used because more processes are opened. Other impacts can be found in the article mentioned above.
In addition to Site Isolation, there is another thing that is easy to confuse (I originally thought they were the same when writing this article, but later found out that they are different), called “cross-origin isolated state.”
What is the difference between these two? According to my understanding (not guaranteed to be completely correct), the article “Mitigating Spectre with Site Isolation in Chrome” mentions:
Note that Chrome uses a specific definition of “site” that includes just the scheme and registered domain. Thus, https://google.co.uk would be a site, and subdomains like https://maps.google.co.uk would stay in the same process.
The definition of “Site” in Site Isolation is the same as that of the same site. http://a.example.com and http://b.example.com are the same site, so even under Site Isolation, these two web pages will still be placed in the same process.
Cross-origin isolated state should be a stronger isolation, isolating everything that is not the same origin, even if it is the same site. Therefore, http://a.example.com and http://b.example.com will be isolated. Moreover, the object of Site Isolation is the process, while cross-origin isolated state seems to isolate the browsing context group, not allowing cross-origin things to be in the same browsing context group.
This cross-origin isolated state is not enabled by default, and you must set these two headers on your webpage to enable it:
- Cross-Origin-Embedder-Policy: require-corp
- Cross-Origin-Opener-Policy: same-origin
As for why these two are used, I will tell you later.
COEP (Cross-Origin-Embedder-Policy)
To achieve cross-origin isolated state, you must ensure that all cross-origin access on your website is legal and authorized.
The COEP (Cross-Origin-Embedder-Policy) header has two values:
- unsafe-none
- require-corp
The first is the default value, which means there are no restrictions, and the second is related to CORP (Cross-Origin-Resource-Policy) mentioned earlier. If you use require-corp, it means telling the browser that “all resources I load on the page must have the existence of CORP (or CORS), and they must be legal.”
Now, suppose we have a website a.example.com and we want to make it a cross-origin isolated state, so we add a header to it: Cross-Origin-Embedder-Policy: require-corp, and then introduce a resource in the webpage:
<img src="http://b.example.com/logo.jpg">Then we send the correct header on the b side:
app.use((req, res, next) => {
res.header('Cross-Origin-Resource-Policy', 'cross-origin')
next()
})This completes the first step.
In addition, I mentioned earlier that there is a slight difference between not setting CORP and setting it to cross-origin, which is the difference here. If b does not send this header in the above example, the Embedder Policy will not pass.
COOP (Cross-Origin-Opener-Policy)
The second step is the COOP (Cross-Origin-Opener-Policy) header. As I mentioned earlier, when you use window.open to open a webpage, you can manipulate the location of that webpage, and the opened webpage can also manipulate your webpage using window.opener. This creates a connection between the windows, which violates cross-origin isolation. Therefore, the COOP header is used to regulate the relationship between windows and openers, and there are three values:
- Cross-Origin-Opener-Policy:
unsafe-none - Cross-Origin-Opener-Policy:
same-origin - Cross-Origin-Opener-Policy:
same-origin-allow-popups
The first one is the default value and has no effect. The second one is the strictest. If you set it to same-origin, the “window you opened” must also have this header and must also be set to same-origin so that you can share the window between them.
Let’s do an experiment. We have two webpages:
The content of page1.html is as follows:
<script>
var win = window.open('http://localhost:5566/page2.html')
setTimeout(() => {
console.log(win.secret)
}, 2000)
</script>The content of page2.html is as follows:
<script>
window.secret = 5566
</script>If page1 successfully outputs 5566, it means that the two windows are shared. Otherwise, they are not.
Let’s try without any header first. Since these two are the same origin, they can already share windows, and 5566 is successfully output.
Next, we change the server-side code to this:
app.use((req, res, next) => {
if (req.url === '/page1.html') {
res.header('Cross-Origin-Opener-Policy', 'same-origin')
}
next()
})Only page1.html has COOP, and page2.html does not. The result of the experiment is “cannot share”. Even if it is changed to this:
app.use((req, res, next) => {
if (req.url === '/page1.html') {
res.header('Cross-Origin-Opener-Policy', 'same-origin')
}
if (req.url === '/page2.html') {
res.header('Cross-Origin-Opener-Policy', 'same-origin-allow-popups')
}
next()
})It is still impossible to share because the same-origin condition is:
- The opened window must be in the same origin.
- The response header of the opened window must have COOP, and the value must be
same-origin.
Only when these two points are met can you successfully access the complete window. And one thing to note is that once this header is set but the rules are not met, not only can you not access the complete window, but you cannot even get openedWindow.close and window.opener. The two windows are completely unrelated.
The conditions for same-origin-allow-popups are more relaxed:
- The opened window must be in the same origin.
- The opened window does not have COOP, or the value of COOP is not
same-origin.
In short, same-origin not only protects others but also protects yourself. When you set it to this value, whether you open someone else’s or are opened by someone else, you must be in the same origin and have the same header to access each other’s windows.
For example, I adjusted it to this:
app.use((req, res, next) => {
if (req.url === '/page1.html') {
res.header('Cross-Origin-Opener-Policy', 'same-origin-allow-popups')
}
next()
})Only page1 has set same-origin-allow-popups, and page2 has not set anything. In this case, they can access each other’s windows.
Next, if they are the same:
app.use((req, res, next) => {
if (req.url === '/page1.html') {
res.header('Cross-Origin-Opener-Policy', 'same-origin-allow-popups')
}
if (req.url === '/page2.html') {
res.header('Cross-Origin-Opener-Policy', 'same-origin-allow-popups')
}
next()
})This is also fine.
But what if it’s like this?
app.use((req, res, next) => {
if (req.url === '/page1.html') {
res.header('Cross-Origin-Opener-Policy', 'same-origin-allow-popups')
}
if (req.url === '/page2.html') {
res.header('Cross-Origin-Opener-Policy', 'same-origin')
}
next()
})This won’t work.
So to summarize, suppose there is a webpage A that opens a webpage B using window.open:
- If AB is cross-origin, the browser has restrictions and can only access methods such as
window.locationorwindow.close. It cannot access the DOM or other things. - If AB is same-origin, they can access almost the entire window, including the DOM.
- If A adds a COOP header and the value is
same-origin, it means that more restrictions have been imposed on the second case, and only when B also has this header and the value is alsosame-origincan they access each other’s windows. - If A adds a COOP header and the value is
same-origin-allow-popups, it is also a restriction on the second case, but it is more relaxed. As long as the COOP header of B is notsame-origin, they can access each other’s windows.
In short, to “have the opportunity to access the window mutually”, it must first be same-origin, which is unchangeable. In fact, whether it can be accessed or not depends on whether the COOP header and the value of the header are set. If the COOP header is set but does not comply with the rules, window.opener will become null directly, and you cannot even get the location (if the rules are not set, you can get it even if it is cross-origin).
In fact, according to the spec, there is also a fourth type: same-origin-plus-COEP, but it seems more complicated, so let’s not study it for now.
Back to cross-origin isolated state
As mentioned earlier, cross-origin isolated state requires setting these two headers:
- Cross-Origin-Embedder-Policy: require-corp
- Cross-Origin-Opener-Policy: same-origin
Why? Because once set, it means that all cross-origin resources on the page are accessible to you, and if you do not have permission, an error will occur. So if it is set and passed, it means that all cross-origin resources are allowed to be accessed by you, and there will be no security issues.
On the website, you can use:
self.crossOriginIsolatedto determine if you have entered the cross-origin isolated state. If so, you can use some sealed (?) functions because the browser knows you are very safe.
In addition, if you enter this state, the trick of bypassing the same-origin policy by modifying document.domain mentioned earlier will not work, and the browser will not let you modify this thing.
To learn more about COOP, COEP, and cross-origin isolated state, please refer to:
- Making your website “cross-origin isolated” using COOP and COEP
- Why you need “cross-origin isolated” for powerful features
- COEP COOP CORP CORS CORB - CRAP that’s a lot of new stuff!
- Making postMessage() work for SharedArrayBuffer (Cross-Origin-Embedder-Policy) #4175
- Restricting cross-origin WindowProxy access (Cross-Origin-Opener-Policy) #3740
- Feature: Cross-Origin Resource Policy
Summary
This article actually talks about a lot of things, all revolving around security. At the beginning, we talked about the consequences of incorrect CORS settings and defense methods, followed by using document.cookie to modify same-site to same-origin (both websites must agree to do so), and finally the highlight of this article:
- CORB (Cross-Origin Read Blocking)
- CORP (Cross-Origin Resource Policy)
- COEP (Cross-Origin-Embedder-Policy)
- COOP (Cross-Origin-Opener-Policy)
It took a lot of time to find information because the names are too similar and some of the functions are actually quite similar, but after looking at them for a long time, you will find that they are quite different, and each policy focuses on different things. I hope that the context I have organized will help you better understand these things.
If you want to summarize these four things in one sentence, it may be:
- CORB: the default mechanism of the browser, mainly to prevent loading unreasonable resources, such as using img to load HTML
- CORP: an HTTP response header that determines who can load this resource, and can prevent cross-origin loading of images, videos, or any resources
- COEP: an HTTP response header that ensures that all resources on the page are legally loaded
- COOP: an HTTP response header that adds stricter window sharing settings to same-origin
Compared to the others, I am not as familiar with the content of this article. If there are any mistakes, please don’t hesitate to point them out. Thank you.
Next, the next article will be the last one in this series: CORS Complete Guide (Part 6): Summary, Afterword, and Leftovers
Comments