「從攻擊手法開始重新認識網路」是一個新的系列文,比起從頭開始講起某個東西如何運作,我會直接先從攻擊手法開始切入,從這點去探討這個攻擊是怎麼做到的,又該如何防禦。
帶著這些問題去閱讀文章,可以更有意識地去理解現在要學的是什麼,待會看到的東西又是為了解決什麼問題。比起平鋪直敘的講解名詞,「從一開始就帶著問題閱讀」是我更想嘗試的方式。
這篇會聊聊 DNS 的運作原理、攻擊手法以及相對應的解法,話不多說直接開始。
從 DNS cache poisoning 開始認識 DNS
以前就聽過一種叫做 DNS 快取污染(DNS cache poisoning)的攻擊手法,能控制 DNS 的回答,例如說正常狀況下 google.com 應該是連到某個 IP 如 142.250.21.139,但若是有攻擊者污染了 DNS,可能會回答另一個 IP,使用者就會連到不同的位置。
有天我突然好奇了起來,這是怎麼做到的?又有什麼防禦方法。
要知道答案之前,我們必須先知道 DNS 這整個系統是怎麼運作的。
DNS 全名為 Domain Name System,中文翻叫域名系統,最廣為人知的、針對一般大眾的解釋,大概就是 DNS 就類似於電話簿,他會把 google.com 轉成 142.250.21.139,把 github.com 轉成 20.27.177.113,在網路世界中,最底層拿來發送封包的地址並不是網域,而是 IP,所以必須把網域解析成 IP。
一個更生活化的解釋是,DNS 伺服器像是個老練的計程車司機,你說要去 101,他就精準開到臺北市信義區信義路 5 段 7 號,幫你把這些地標的名稱轉成地址,送你到目的地。
那到底這背後具體都做了些什麼,你的電腦又是怎麼詢問 DNS server 的呢?
當你連上你家的路由器時,有些路由器會下發一個 IP 給你,跟你說你要使用 DNS 時,就用這個 IP 就對了。例如說知名的 168.95.1.1 是中華電信的 DNS server,每當你想查詢某個網域的 IP 是什麼的時候,就會去問他。
由於這個 server 負責把網域解析成 IP,通常稱為 DNS resolver,運作如下:
雖然對我們來說,就是問他就能得到答案,但其實背後運作不只如此。以我的網域 blog.huli.tw 來說,其實是一層一層的。當我們問中華電信時,中華電信會去問掌管所有 DNS 的服務:「root name server」,而這個服務會記錄 .tw 是誰管的,跟中華電信說:「去問他吧」。
於是接下來中華電信就去問管 .tw 的 TLD name server,這個 name server 查了 huli.tw 之後發現這個網域是由 ken.ns.cloudflare.com 管的,就再回說去找他們吧。
所以中華電信就再去問了 ken.ns.cloudflare.com,拿到了底下的結果:
blog.huli.tw. 300 IN A 104.21.51.169
blog.huli.tw. 300 IN A 172.67.183.1就確認了 blog.huli.tw 對應到的 IP 有這兩個,就會回傳給我的瀏覽器,接著瀏覽器再自己選擇要連去哪裡。
由於整條鏈路中只有 ken.ns.cloudflare.com 知道最終結果,它又叫做 authoritative name server,中文翻叫「權威 DNS」。
整體流程如下方:
這個遞迴解析的過程滿長的,因此不可能每次都這樣,事實是每一個環節都有 cache 的存在,例如說瀏覽器就可能有自己的 cache,作業系統也有,中華電信提供的 DNS resolver 也是,所以並不會每一次都查完整個鏈路才能知道結果,只要碰到 cache 就會返回了。
而這個 DNS 快取污染打的就是 DNS resolver,也就是前面提到的中華電信 168.95.1.1 那台,若是我能污染 google.com,那中華電信的使用者在造訪 google 時,就會連去我的 server,可見這個攻擊的影響力之大。
DNS resolver 是負責把 domain 轉成 IP 的服務,只要知道這點,我們就可以先來談談兩個真實事件了。
喜傑獅事件
筆電品牌喜傑獅原本在官網推出「一讚折一元」的活動,但發現太多讚了所以臨時改規則並且提早關閉網站。由於有些在時間內的訂單也被取消,因此網友告上法院,最後判決喜傑獅敗訴。
這個案件我當時也滿關注的,雖然很多網友都覺得純粹是喜傑獅在無理取鬧,但對於部分被取消的訂單,我很好奇最後會怎麼判。根據喜傑獅的說法,他們已經關閉了網站,但是網友透過「網頁漏洞」連進來下單,因此是無效的。
那這個網頁漏洞到底是什麼?網頁又是怎麼關閉的?
關閉其實就是喜傑獅把他們的 DNS 紀錄拔掉,等快取失效之後,官網自然就連不進來了,你輸入網址之後會回一個錯誤。而所謂的「網頁漏洞」是網友自己修改本機的 /etc/hosts 檔案,把記錄加回去,就可以連回官網了,不需要靠 DNS resolver。
根據臺灣士林地方法院小額民事判決114年度士消小字第5號,法官最後的見解為:
再者,倘被告有意拒絕一切訂單成立,應可逕將官網伺服器暫時離線,此由前述網友Facebook文章可知被告嗣後亦採此措施即明,則被告未將官網伺服器離線而僅單純將DNS與IP位址解連,猶如商家於營業中將門牌及招牌(DNS)暫時卸下,惟任何知悉商家實際位置(IP位址)之顧客尋覓上門,商家仍如常提供服務(成立訂單),自不能認為顧客有何詐欺行為或商家有何陷於錯誤可言。
就是你店家不想賣東西,應該把伺服器關掉離線,但你只是把 DNS 拿掉,網站還在。如同商家還在營業只是把招牌拿掉,但熟門熟路的顧客自己上門買東西也還是合理的。
我關注的點是「把 DNS 紀錄拿掉算不算關閉網站」,而且我想到一個假想的情境,假設某間公司的其中一個測試環境暴露在公網(IT 也說過應該放內網,但是某些人覺得要連 VPN 很麻煩,想說沒人會去找就放公網了),但是網址沒有公開,裡面所有物品的價格都是正常的一半。
有個路人透過某種方式找到這個網址下單了,會不會被認為是交易成立?
不知道是路人要舉證自己有足夠理由相信這網站是正常的所以才下單,還是公司要舉證這網站雖然暴露公網但非公開網站,不過後者以喜傑獅的判例來看可能行不通,會認為網站公開了就是公開。
小紅書的封鎖與 RPZ
前面提過若是可以讓 DNS resolver 把 google.com 解析到我的 IP,大家在連 Google 的時候就會跑過來我的 server,這算是惡意的攻擊。
但也有一種方式原理相同,做法也相同,卻被視為是善意的。
舉例來說,政府發現某個詐騙網站很猖狂,因此直接叫中華電信把它們的 domain 解析成政府單位的 IP,因此使用者連到該網站時,會顯示警告畫面,看不到原本的內容。
這個機制叫做 DNS RPZ(Response Policy Zone),財團法人台灣網路資訊中心有特別做一個網站來說明:DNS RPZ 治理機制,由各機關提出審核,審核通過之後台灣的各大電信就會特別把這筆紀錄解析的 IP 改掉,跳出警告畫面。
最有名的就是去年年底小紅書被封的案例了,當你用瀏覽器打開小紅書的網站後,會先看到一個憑證錯誤的頁面,點繼續之後會看到這個:

而理解 DNS 是怎麼運作的之後,就能知道為什麼網路上流傳的繞過方法:「改 DNS resolver」可以成功。
儘管大家預設用的可能是中華電信的 DNS resolver,但這是可以改的,你可以改成 Google 提供的 8.8.8.8,也可以改成 Cloudflare 提供的 1.1.1.1,透過這兩個 DNS resolver,照樣可以連上小紅書。
好奇的話,你可以在自己電腦試一下,先透過 168.95.1.1 查詢小紅書的 IP,會得到 140.111.246.32 以及另一條 rpz 相關的說明:
dig @168.95.1.1 www.xiaohongshu.com A
;; ANSWER SECTION:
www.xiaohongshu.com. 300 IN A 140.111.246.32
;; ADDITIONAL SECTION:
rpztw. 60 IN SOA localhost. This.is.an.infringing.website.rpztw. 1781775121 60 60 86400 60而透過 8.8.8.8 就是正常的 IP:
dig @8.8.8.8 www.xiaohongshu.com A
www.xiaohongshu.com.eo.dnse0.com. 60 IN A 43.170.214.10
www.xiaohongshu.com.eo.dnse0.com. 60 IN A 43.175.160.184
www.xiaohongshu.com.eo.dnse0.com. 60 IN A 43.175.164.195
www.xiaohongshu.com.eo.dnse0.com. 60 IN A 43.175.161.148所以,DNS RPZ 跟真正意義上的封鎖還是有一段距離,原意是想保護民眾連線到違法的網站,但如果你不想被保護或是你知道你在幹嘛,只要改個 DNS 還是能連到,不會被城牆擋下來。
像這樣主動干預網路世界的行為,想當然耳也有許多法規以及制度上的討論,到底政府能介入到什麼程度?又該怎麼防止 RPZ 胡亂封鎖?也有人認為政府壓根就不該干預,網路世界應該是自由的。
而台灣的 RPZ 確實不小心封過許多重要服務,如 Azure Web App 或是 WordPress 都慘遭過毒手。
想了解更多網路治理的話題,可以參考 OCF 財團法人開放文化基金會或是臺灣網路治理論壇 TWIGF,以前在臉書上也有一些公開的討論,如這個 2023 對 RPZ 機制的討論以及 2025 小紅書被封的討論。
DNS cache poisoning 的原理
把話題拉回 DNS cache poisoning,既然我們現在了解 DNS 的運作了,那到底這個污染是怎麼做到的?
前面提過 DNS resolver 會去 ken.ns.cloudflare.com 問 blog.huli.tw 的 IP,攻擊者是怎麼干預這個結果的?
歷史上出現過的第一個攻擊手法是:「買一送一」,第二個是:「搶答」。
首先,「問 blog.huli.tw 的 IP」這所謂的「問」,背後就是傳了個封包,而 DNS 走的協議是 UDP,所以對 DNS resolver 來說,就是傳了個封包給負責解析 blog.huli.tw 的 IP,假設是 108.162.193.127,內容寫著:
From: 168.95.1.1:53
To: 108.162.193.127:53
Question:
blog.huli.tw A?
Transaction ID: 12345而正常狀況下,該 name server 收到以後會回答:
From: 108.162.193.127:53
To: 168.95.1.1:53
Transaction ID: 12345
Answer:
blog.huli.tw A 104.21.51.169此時 resolver 驗證過 transaction ID 跟來源 IP 一致,就相信這個結果,把這個結果放到自己的快取中,下次有人再問就直接回答。
而第一種手法「買一送一」,負責解析 blog.huli.tw 的 name server 會在回傳的封包中偷偷送你其他 domain 的結果:
From: 108.162.193.127:53
To: 168.95.1.1:53
Transaction ID: 12345
Answer:
blog.huli.tw A 104.21.51.169
google.com A 104.21.51.169等同於「雖然你沒問但我順便告訴你,google.com 的 IP 是這個喔」。
不過你必須要有一個負責解析域名的合法 name server 才有辦法攻擊,攻擊前提滿高的,一般人做不到,但是 30 年前發生過。
1997 年,Eugene Kashpureff 經營的 AlterNIC 負責一部分頂級域名的 DNS 解析,而他就是利用這個手法,去影響另一個 DNS 服務 www.internic.net 的解析結果。
這不是資安研究而是真的犯罪,所以被抓了,現在還可以找到紐約時報的報導:From Jail and Boardroom, A Street Fight for the Internet 以及相關的新聞稿。
這個問題後來被修掉,多了一個叫「bailiwick checking」的機制,會檢查該 DNS 伺服器是否有權限回答這個網域的解析紀錄,不讓你買一送一了。
接著講第二種「搶答」,由於 resolver 驗證 transaction ID 跟來源 IP 一致就會信任結果,那反過來講,只要攻擊者能偽造這兩個東西,並且速度比原本的更快,那 resolver 就會相信這個造假的結果。
先來講偽造 IP 這件事情,所謂的 IP,最終就只是放在封包裡的一組字串,雖然 OS 會幫你填好,但你可以自己竄改一下,填入自己想要的 IP,就偽造成功了。
但是,像是 HTTP 那種走 TCP 的情境,開頭有個三向交握,你先發給對方,對方再發給你,這個第二步「對方發給你」,他會發到你偽造的目的地去,你就收不到,就沒辦法成功建立連接,所以就算偽造也沒用。
不過 DNS 是走 UDP,因此封包送出去就結束了,所以才能偽造成功。
除此之外,有些 ISP 有做過濾,當它發現你封包內的 IP 怪怪的,不是分配給你的網段,就會直接把封包丟掉,所以你根本傳不出去,這個機制叫 BCP 38: Network Ingress Filtering。
但這並不是強制的,所以找到沒有做 BCP 38 的 ISP 以後,你就能偽造來源 IP,把偽造的回應發給 DNS resolver。
那 transaction ID 呢?這是個 16 bit 的 ID,可能性只有 65536 種,就一直狂猜就好,只要猜到了就是你的,每次都隨機猜的話,猜 45426 次就有 50% 的機率至少中一次。
但這只是理論上的可行性而已,有個致命的缺點沒有考慮到。前面提過這些 name server 都是有 cache 的,我如果這次猜錯了,就要等 cache 過期才能再猜一次,就算是 1 分鐘好了,我也要猜 1 個月才能猜到 45000 多次,有點不太實際。
而這個缺點,在 2008 年時被 Dan Kaminsky 給克服了。
Black Ops 2008 – Its The End Of The Cache As We Know It
這是 Dan Kaminsky 在 Black Hat USA 2008 的演講標題,投影片只找到這個在 Black Hat Japan 的版本。
他提出的攻擊手法是,既然猜錯會被擋,我們換一個 subdomain 猜就好。
先猜 1.huli.tw,猜錯再猜 2.huli.tw,以此類推,一直不斷往後猜。由於每次猜的 domain 都不同,因此就算猜錯也不需要等待 cache 過期,原本每猜一次就 CD 五分鐘,現在根本不用等。
若是每秒猜個 100 次,8 分鐘就可以把 45000 多次猜完,成功機率大幅提升。
但是,猜中又能如何呢?又沒有人去訪問 42.huli.tw 這種根本不存在的 domain。
這就是重點了,當我們猜中時,我們偽造的 response 並不是「42.huli.tw 在 x.x.x.x」,而是「我也不知道 42.huli.tw 在哪,你去問 x.x.x.x,huli.tw 都是他管的」,所以 DNS resolver 對於負責解析 huli.tw 的 name server IP 就被污染了,在這之後就會去偽造的地方問。
這有一點類似剛提過的買一送一,但有本質上的區別。買一送一是:「你問我 huli.tw,我順便告訴你 google.com」,但這根本不該發生,所以被封掉了。
而現在是:「你問我 42.huli.tw,我告訴你誰在管 huli.tw」,這是允許的,因為兩個都是屬於同一個網域底下。
整個攻擊流程如下:
最後的修復方式是本來只要猜 16 bit 的 transaction ID,現在連 port 都變成隨機的了,而 port 的範圍也是 16 bit,因此可能性就變成 32 個 bit,從原本的 6 萬種暴增到 40 億種。
話說 Dan Kaminsky 本人有在 O’Reilly FOO Camp 2008 講過背後修復漏洞的一些故事,影片在這:Geek Alert: Dan Kaminsky on the DNS Bug of 2008,因為影響範圍實在太大,每一間公司都需要配合修復。
既然可能性變 40 億種,要猜中看起來就是不可能的事了。但駭客就厲害在他總會追根究底,40 億個隨機數是不可能猜到,但你的隨機數又是怎麼產生的呢?
DNS Cache Poisoning Like it’s 2006
USENIX Security 是全球最重要的資安學術會議之一,雖然今年的會議要到 8 月才舉辦,但是已經能看到被接受的 paper,而標題的 DNS Cache Poisoning Like it’s 2006 就是其中一例,作者是希伯來大學的 Omer Ben-Simhon 與 Amit Klein。
在 2008 年 Dan Kaminsky 發現的漏洞被修補之後,DNS 快取污染的攻擊可能性就變低了許多,畢竟要在短時間內猜中 40 億以內的隨機數,怎麼想都很困難。
然而,你有想過這些隨機數是怎麼產生的嗎?
通常在程式中會有兩種產生隨機數的方式,一種安全的,另一種不安全,這裡的安全專有名詞是「cryptographically strong」,密碼學上的安全。
以 JavaScript 而言,不安全的是 Math.random,安全的是 crypto.getRandomValues,差別在於背後的實作為何,前者是可以預測的,而後者不行。
為什麼可以預測呢?因為大部分的隨機數都不是真的隨機數,而是「假裝成隨機數」,例如說有個簡單的產生隨機數的演算法叫 LCG(Linear Congruential Generator),寫成 JavaScript 程式碼是:
class LCG {
constructor(seed) {
this.state = seed;
}
next() {
const a = 1664525;
const c = 1013904223;
const m = 2 ** 32;
this.state = (a * this.state + c) % m;
return this.state;
}
}
const rng = new LCG(123);
console.log(rng.next());
console.log(rng.next());
console.log(rng.next());你傳入一個 seed 當作初始狀態 state,然後透過固定的公式:1664525 * state + 1013904223 再對 m 取餘數,得到的結果就是隨機數,同時也會成為下一個狀態。上面這個負責產生隨機數的函式會被稱為 PRNG(Pseudo-Random Number Generator),中文是偽隨機數產生器。
所以只要你的 seed 一樣,每次產生出來的隨機數序列都一樣。反過來講,當你拿到足夠的隨機數以後,就可以反推回去原本的 seed 是什麼,這就是為什麼它可以被預測,就是單純的數學而已。
DNS resolver 背後用的軟體叫 BIND,而 BIND 在產生隨機數時,用的是一個叫 Xoshiro128** 的 PRNG,在拿到多個 output 之後,就可以往回推它的初始狀態,拿到初始狀態以後,就可以預測下一個以及之後每一個隨機數會是多少。
這其實就是解聯立方程式啦,跟 2x+y+z=3、5x+2y+3z=2、x+y+z=9,請問 x、y、z 是多少的意思。
那重點是這些 output 要怎麼拿到呢?除了 transaction ID 跟 port 以外,BIND 在其他地方也用了相同的隨機數產生器。舉例來說,當我 query google.com 的紀錄時,第一次的回覆是:
google.com. 252 IN A 142.250.21.102
google.com. 252 IN A 142.250.21.138
google.com. 252 IN A 142.250.21.139
google.com. 252 IN A 142.250.21.113
google.com. 252 IN A 142.250.21.101
google.com. 252 IN A 142.250.21.100而第二次的回覆是:
google.com. 247 IN A 142.250.21.138
google.com. 247 IN A 142.250.21.139
google.com. 247 IN A 142.250.21.113
google.com. 247 IN A 142.250.21.101
google.com. 247 IN A 142.250.21.100
google.com. 247 IN A 142.250.21.102每個結果都是針對 google.com 的 A type,我們把它稱為一組 Resource Record Set,簡稱 RRSet,而你可以清楚看見雖然兩次回覆的 IP 都是那一些,但順序不一樣。
這個順序就是隨機決定的,因此當你 RRSet 裡面的紀錄夠多時(根據原文是 23 個以上),就可以從排序結果反推出 PRNG 其中一部分的 seed,多做幾次就可以還原所有 128 bits 的 seed,就破解隨機數了。
隨機數被破解以後,port 跟 transaction ID 都一猜就中,40 億次的可能性被你偷看未來以後縮減到只剩下 1,前面加的保護措施都沒用了。而解法的話,就是把隨機數換成更安全的產生方式,以及重要的跟不重要的隨機數不要混在一起。
像這個例子就是重要的隨機數如 transaction ID 跟 port,用的 PRNG instance 跟那些不重要的隨機數如 RRSet 排序相同,所以你可以從其他地方反推回去 seed 是什麼。
這個漏洞已經在去年 10 月修復,官方公告在這:CVE-2025-40780: Cache poisoning due to weak PRNG。
話說我也是意外找到這個還沒公開演講的研究,我問了 codex DNS 快取污染有哪些手法,它就找這個給我,如果是我自己去 google 搞不好搜尋不到,會先搜到其他文章。
不過由於文章很新,所以無論是 ChatGPT 還是 Gemini,只要它沒有用到搜尋工具,給你的答案就會是一堆幻覺(但看起來很真而且頭頭是道),會講出一堆原文沒寫的東西。
在 DNS Cache Poisoning Like it’s 2006 的 paper 中可以看到許多細節,其中一段是在講 DNS cookie,我看到的時候想說:「怎麼又來個我沒聽過的新名詞」,於是就去查了一下這是什麼。
DNS cookie 的提案雖然在 2006 就有了,但一直到 2016 才正式變成 RFC 7873,它想解決的主要就是封包偽造的問題。
前面寫這麼多東西,根本就在於封包偽造這件事,而 DNS cookie 提出來的解法是當 DNS resolver 要問 DNS name server 問題時,先帶上一個 64 bits 的 client cookie,這個 client cookie 的產生方式可以類似這樣,用 client IP + server IP 搭配一個 secret 算出來:
HMAC-SHA256-64(Client IP Address | Server IP Address, Client Secret)接著把這個 client cookie 跟想查詢的 domain 一起傳給 name server。
當 name server 收到後,就用類似的方法產生出一個獨一無二的 server cookie(例如說把 client IP + client cookie + server secret 一起做個 hash),把查詢的答案跟 server cookie 一起發給 client,而 DNS resolver 收到後就把 server cookie 存起來。
從這之後,所有從 DNS resolver 發給該 name server 的查詢請求,都會帶著 client cookie + server cookie。而 name server 也是,兩邊在收到請求時都會檢查 client cookie 與 server cookie 是否正確。
當這個關係建立後,DNS resolver 如果收到偽造的回應,由於攻擊者不知道 client cookie,也沒辦法偽造 server cookie,所以驗證就不會通過。
那在上一個小結討論的猜測隨機數的手法,是怎麼繞過這個 DNS cookie 的防禦呢?
雖然 DNS cookie 這個機制在 BIND 裡面預設就是開啟的,但是新版的過期時間是 60 秒,每 60 秒就會把整個流程重來一次,因此攻擊者每 60 秒就有一次機會攻擊,只要你能比權威 DNS 更快回應,就能先傳送你自己的 client cookie,進而繞過這個保護機制。
所以 DNS cookie 這整個機制看似沒問題,但因為過期時間太短了,所以在剛過期後的那一個 window 裡面,就等於是沒這個防護的。
再者,DNS cookie 其實也沒這麼普及,在 Alexa 排名前一百萬的網站裡面,只有 32% 有支援。
除了 DNS cookie 以外,還有一個保護措施叫做 DNSSEC,而論文中有提到他們假設 victim 沒有開啟這個機制,所以不用繞過。
那 DNSSEC 又是什麼呢?
全名為 DNS Security Extensions,要解決的問題是一樣的,就是該怎麼讓攻擊者無法偽造權威 DNS 的回應。
前面提過的方法其實都治標不治本,一開始 transaction ID 能被猜中,所以加了個隨機的 port,就猜不到了,然後也有了 DNS cookie,再多一個你猜不到的 client cookie 外加 server cookie,以第一個連線的人為準。
但這些方法沒有一個能保證 DNS resolver 收到的回應就是來自於權威 DNS,只是用隨機性來增加難度。真正能保證的,應該是像 HTTPS 那樣,建立一個信任鏈,能靠數位簽章來驗證。
而 DNSSEC 就是如此,簡單來講,可以想成權威 DNS 的回應中會帶有一個 signature,而 DNS resolver 收到以後,可以用密碼學的方式來驗證這個 signature 是不是 huli.tw 簽出來的,是的話才承認,就能夠防止其他人偽造。
但這個聽起來如此好用的機制,實際的使用率非常低,根據 M11: DNSSEC Deployment in TLD and SLD 給的數字,世界前 100 名的網站只有 7% 有設置,而 .tw 也只有 12%。
DNSSEC 是要自己配的,所以是每個 domain owner 自己要去處理,配錯的話可能 user 訪問網站就有問題。查了一圈,推不起來的原因看起來是部署比較麻煩外加沒有誘因。跟實作的成本比起來,帶來的收益似乎更低。
不過現在有些網域代管的服務幫你把這些麻煩事做掉了,如 TWNIC 已經預設啟用 DNSSEC,而 Cloudflare 也可以一鍵開啟。但對於那些有技術債的大公司來說,或許成本還是相對較高的,並不是按個按鍵就能開啟這麼簡單。
DNS 天生的缺陷與隱私保護
其實在討論 DNS 相關的攻擊時,都會先分成兩個種類:on-path 與 off-path。
這個 path 指的是 DNS 封包的傳送路徑。DNS server 彼此之間溝通的封包並沒有任何加密,因此傳送封包時,中間的任何一個節點都可以看到內容或是篡改,這個攻擊路徑就叫 on-path。
而 off-path 指的就是攻擊者並不在路徑上,看不到封包也沒辦法直接竄改,前面講的那些攻擊案例都是基於 off-path 的。由於 on-path 能看能改,因此上面所說的各種防禦手法,就只有 DNSSEC 能真正防禦 on-path 的攻擊,因為它依靠的是數位簽章,而不是某些隨機數。
也因為 DNS 封包沒加密,因此你所使用的 DNS resolver,甚至是這整條鏈路上的節點,都能看到你的封包,知道你查詢了哪些網站,洩漏了你的隱私。
因此呢,就有兩個技術出現了,一個是 DNS over TLS,簡稱 DoT,把 TLS 那套搬到 DNS 查詢身上,這次改走 TCP 連線外加 TLS 驗證,跟 HTTPS 類似,讓其他人都看不到封包內容。
另一個技術是 DNS over HTTPS,簡稱 DoH,把 DNS 查詢那套換成 HTTPS,例如說要查 DNS 時就用 POST /dns-query 發送請求,也能達到防止隱私外洩的效果。像是 Google 的公用 DNS 就有提供這個功能:
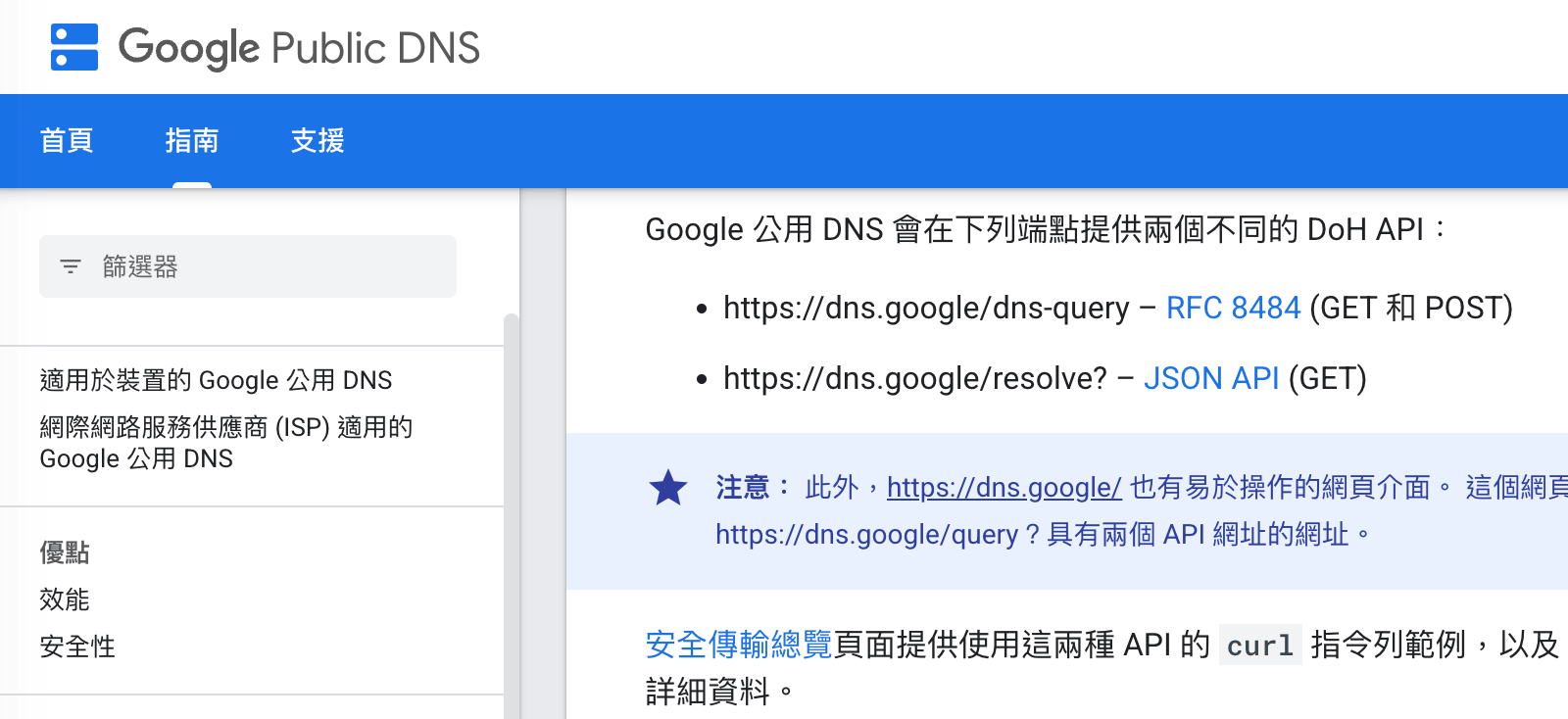
這兩個技術都是運用在:「從你的電腦發封包去 DNS resolver」這個情境上,保護你的隱私不會外洩,讓 ISP 看不到你到底查詢哪些網站。
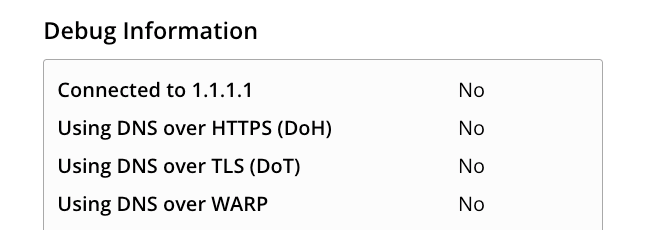
如果想知道你電腦現在有沒有開啟,可以用這個服務:https://one.one.one.one/help/
像我的電腦預設就是沒開的:
結語
當我們想造訪 huli.tw 時,系統就會去問 DNS resolver 這個網域對應到的 IP,而 resolver 會先問 root name server,得到「你去問 .tw」的回覆,接著轉而去問管理 tw 的 TLD name server,得到「你去問 Cloudflare」的回答,而身為 authoritative name server 的 Cloudflare,最終給了 104.21.51.169 的回答。
若是有攻擊者在 Cloudflare 回答之前,搶先回答:「我知道,答案是 8.8.8.8」,那我們訪問 huli.tw 時,就會連到這個假的地址,這就是 DNS 快取污染的攻擊。
為了防止這個攻擊,必須讓攻擊者沒辦法偽造封包,因此出現了隨機的 transaction ID、隨機的 port,或是 DNS cookie 還有 DNSSEC 等機制,想解決的問題都是類似的:「該如何保證 DNS resolver 拿到的結果是正確的」。
而除此之外,明文的 DNS 天生碰到的另一個問題是隱私,當系統在問 DNS resolver huli.tw 的 IP 是什麼的時候,大家都會知道我要造訪 huli.tw。
為了解決這個隱私問題,就出現了 DoT 與 DoH 等機制,透過加密來保護 DNS 查詢的封包,就算攔截到了,也看不到裡面的內容。
以上就是這篇的精華版總結,供大家參考。
最一開始,我只是對 DNS 快取污染有所好奇,去問了 AI 有什麼攻擊手法,得到了 DNS Cache Poisoning Like it’s 2006 那篇論文,從這篇論文知道了 2008 年 Dan Kaminsky 的攻擊手法,也學到了什麼是 DNS cookie。
接著不斷往前推進,再次學習 DNS 查詢的過程(以前學過但沒學這麼細),也順便查了會有哪些問題,把這方面的知識補足。在這學習的路途中,AI 幫了不少忙,很多疑問都直接問 AI 並且獲得答案,我會同時問 ChatGPT、Gemini 還有 Codex(GPT 5.5)交叉比對一下,順便自己動手去 google 相關資料,看是不是對的。
DNS Cache Poisoning Like it’s 2006 因為太新了所以出現不少幻覺:


這樣看了一輪下來,覺得自己終於對 DNS 這整套系統有更多的一些理解,最有收穫的是我自己,然後也想把學到的東西整理過後分享給讀者。這次的文章還有一點不同,那就是開始嘗試搭配 AI 做一些互動式的網頁,希望能幫助理解,不曉得效果如何,有什麼建議都可以在底下留言或是透過表單跟我分享。
評論