前言
如果要舉出一個在 JavaScript 裡面很重要也很常用,但新手常常搞混的概念,那「非同步(Asynchronous)」當仁不讓,絕對是第一名。跟其他那些 this、closure、prototype 或是 hoisting 比起來,非同步在實際開發的時候用到的頻率高太多了,而且是初學者常常會踩坑的地方。
非同步真的那麼難嗎?
我相信不是的。只要循著一個正確的脈絡前進,就可以循序漸進理解為什麼需要非同步,也能知道在 JavaScript 裡面是怎麼處理這種操作的。
類似的主題我其實在四年前就寫過,但現在回頭看實在是寫得滿差的,所以四年後重新挑戰這個主題,希望能寫出一篇品質不錯的文章,把非同步這件事情講清楚。
在寫這篇文章之前,參考了 Node.js 的官方文件,發現在非同步的講解上其實做得不錯,因此本文會以類似的切入點開始談這個問題。如果不會 Node.js 也沒關係,我底下會稍微做點介紹。
建議閱讀本文以前需要具備 JavaScript 基礎,知道如何使用 JavaScript 操作 DOM,也知道什麼是 ajax。
接著就讓我們開始吧!
Node.js 基本介紹
JavaScript 是一個程式語言,會有程式語言本身所規範可以用的東西,例如說用var宣告變數,用if else進行判斷,或者是使用function宣告函式,這些東西都是 JavaScript 這個程式語言本身就有的部分。
既然我上面說了「程式語言本身就有的部分」,就代表也有一些東西其實是「不屬於 JavaScript 這個程式語言的」。
例如說document.querySelector('body'),可以讓你拿到 body 的 DOM 物件並且對它做操作,而操作之後會即時反應在瀏覽器的畫面上。
這個 document 是哪來的?其實是瀏覽器給 JavaScript 的,這樣才能讓 JavaScript 透過 document 這個物件與瀏覽器進行溝通,來操控 DOM。
如果你去翻 ECMAScript 的文件,你會發現裡面完全沒有出現document這個東西,因為它不是這個程式語言本身的一部份,而是瀏覽器提供的。
如果在瀏覽器上面跑 JavaScript,我們可以把瀏覽器稱作是 JavaScript 的「執行環境(runtime)」,因為 JavaScript 就跑在上面嘛,十分合理。
除了 document 以外,像是拿來計時的 setTimeout 與 setInterval,拿來做 ajax 的 XMLHttpRequest 與 fetch,這些都是瀏覽器這個執行環境所提供的東西。
那如果換了一個執行環境,是不是就有不同的東西可以用?除了瀏覽器以外,還有別的 JavaScript 的執行環境嗎?
真巧,還真的剛好有,而且剛好你也聽過,就叫做 Node.js。
有很多人都以為它是一個 JavaScript 的 library,但其實不然,不過也不能怪大家,因為最後的.js兩個字很容易讓人誤解。如果你覺得那兩個字一直誤導你的話,可以暫且把它叫做 Node 就好。
Node.js 其實是 JavaScript 的一個執行環境,就如同它自己在官網上所說的:
Node.js® is a JavaScript runtime built on Chrome’s V8 JavaScript engine.
所以 JavaScript 程式碼可以選擇跑在瀏覽器上,就可以透過瀏覽器這個執行環境提供的東西操控畫面,或者是發 Request 出去;也可以選擇跑在 Node.js 這個執行環境上面,就可以利用 Node.js 提供的東西。
那 Node.js 提供了什麼呢?例如說fs,全稱為 file system,是控制檔案的介面,所以可以用 JavaScript 來讀寫電腦裡的檔案!還提供了http這個模組,可以用 JavaScript 來寫 server!
詳情請參考底下的示意圖:
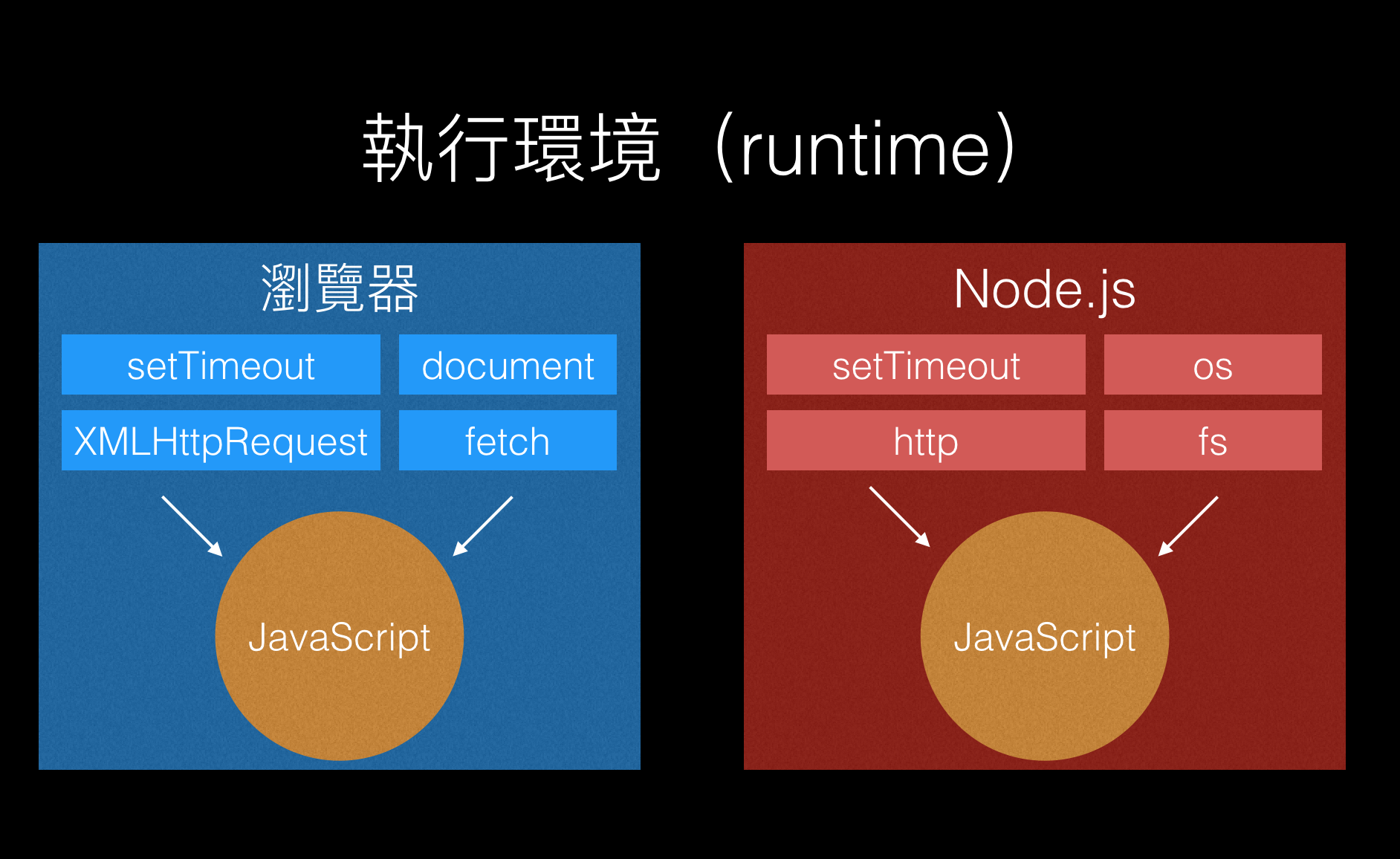
可以很清楚地看到當 JavaScript 在不同環境底下執行時,可以用的東西也不一樣,端看執行環境提供了什麼。眼尖的人可能會發現上圖中 setTimeout 在兩個環境都有出現,這是為什麼呢?
因為這兩個環境都覺得計時器這功能很重要,所以都提供了 setTimeout 這個函式給開發者使用。在兩個環境上的功能雖然是一模一樣的,但要注意的是因為執行環境不同,所以背後的實作方式以及原理也不同。
另外,執行環境不同,執行方式也會不同。以瀏覽器來說,就是用<script src="index.js">去引入一個 JavaScript 檔案,就可以在瀏覽器上執行;以 Node.js 來說,必須先在電腦上安裝 Node.js 這個執行環境,然後以 CLI 的方式用node index.js這個指令來執行。
幫大家整理一下目前的重點:
- JavaScript 只是程式語言,需要搭配執行環境提供的東西,例如說
setTiemout、document等等 - 最常見的 JavaScript 執行環境有兩個,一個是瀏覽器,一個是 Node.js
- 不同的執行環境會提供不同的東西,例如說 Node.js 提供了 http 這個模組讓 JavaScript 可以寫一個伺服器,但瀏覽器就沒有提供這種東西
再來,我們會以 Node.js 的角度來開始介紹同步與非同步。
阻塞與非阻塞
前面有提過 Node.js 有提供控制檔案的介面,讓我們可以寫一段 JavaScript 來讀取與寫入檔案,讓我們來看一段實際的程式碼:
const fs = require('fs') // 引入內建 file system 模組
const file = fs.readFileSync('./README.md') // 讀取檔案
console.log(file) // 印出內容上面這段程式碼先引入Node.js 提供的內建模組fs,再來使用fs.readFileSync來讀取檔案,最後把檔案的內容用console.log給印出來。
(附註:其實上面印出來的東西會是一個Buffer,完整程式碼應該為file.toString('utf8')才會印出檔案內容。但因為這個小細節不妨礙理解,所以在範例程式碼中刻意忽略)
看起來好像沒什麼問題…嗎?
如果檔案小的話的確是沒什麼問題,但如果檔案很大呢?例如說檔案有 777 MB 好了,要把這麼大的檔案讀進記憶體,可能要花個幾秒鐘甚至更久。
在讀取檔案的時候,程式就會停在第二行,要等讀取檔案完畢以後,才會把檔案內容放到 file 這個變數裡,並且執行第三行console.log(file)。
換句話說,fs.readFileSync這個 method「阻擋」了後續指令的執行,這時候我們就說這個 method 是阻塞(blocking)的,因為程式的執行會一直 block 在這裡,直到執行完畢並且拿到回傳值為止。
如果後續的指令本來就都要等到檔案讀取完畢才能執行,例如說在檔案裡面尋找某個字串等等,這樣的方式其實沒什麼問題。但如果後續有些指令跟讀取檔案完全不相干,這不就虧大了嗎?
舉例來說,如果我們想要讀取檔案,並且找出 1 到 99999999 之間的偶數:
const fs = require('fs')
const file = fs.readFileSync('./README.md') // 在這邊等好幾秒才往下執行
console.log(file)
const arr = []
for (let i = 2; i <= 99999999; i+=2) {
arr.push(i)
}
console.log(arr)上面的程式碼會先在讀取檔案那一行卡個幾秒,接著才執行下面的那一個部分,算出 1 到 99999999 之間的偶數並且印出來。
這兩件事情明明一點關聯都沒有,憑什麼印出偶數這件事情要等讀取檔案讀完才能做?難道兩件事情不能同時做嗎?這樣豈不是更有效率?
還真的有這種東西,有另外一種方法可以讓這兩件事情同時進行。
原本readFileSync的問題在於它會阻塞後續程式碼的執行,就好像我去家裡附近的滷味攤買滷味,點好了交給老闆之後就要站在旁邊等,哪裡也不能去,因為我想吃到熱騰騰的滷味。如果我回家了然後每隔十分鐘再過來,可能滷味已經冷掉了,我不想這樣,我買的又不是冰滷味。
所以我只能站在旁邊癡癡等,癡癡冷,才能在第一時間就拿到剛起鍋的滷味。
阻塞(blocking)的對照就叫做非阻塞(non-blocking),意思就是不會阻擋後續程式碼的執行,就好像我去百貨公司美食街點餐一樣,點完以後店家會給我一個呼叫器(本體是紅茶的那間速食店也有),我拿到呼叫器以後就可以回位子上等,或我想先去逛個街也可以。等到餐點準備好的時候,呼叫器就會響,我就可以去店家領取餐點,不用在原地傻傻地等。
以讀取檔案來說,如果是非阻塞的話,是怎麼做到的呢?如果不會阻擋後續程式碼執行,那我該怎麼拿到檔案的內容?
就跟美食街需要透過呼叫器來通知餐點完成一樣,在 JavaScript 想要做到非阻塞,你必須提供一個呼叫器給這個讀取檔案的 method,這樣它才能在檔案讀取完畢時來通知你。在 JavaScript 裡面,function 就很適合當作呼叫器!
意思就是「當檔案讀取完畢時,請來執行這個 function,並且把結果傳進來」,而這個 function 又被稱作 callback function(回呼函式),有沒有突然覺得這名字取得真好?
Node.js 裡的 fs 模組除了readFileSync這一個 blocking 的 method 以外,還提供了另一個叫做readFile的 method,就是我們前面提到的非阻塞版本的讀取檔案,我們來看看程式碼長什麼樣子:
// 讀取內建 fs 模組
const fs = require('fs')
// 定義讀取檔案完成以後,要執行的 function
function readFileFinished(err, data) {
if (err) {
console.log(err)
} else {
console.log(data)
}
}
// 讀取檔案,第二個參數是 callback function
fs.readFile('./README.md', readFileFinished);可以看得出來readFile的用法跟readFileSync差不多,但差別在於:
readFile多了一個參數,而且要傳進參數的是一個 functionreadFileSync有回傳值,回傳值就是檔案內容,readFile看起來沒有
這就呼應到我上面所說的,blocking 與 non-blocking 的差別就在於 blocking 的 method 會直接回傳結果(也是因為這樣所以才會阻塞),但 non-blocking 的 method 執行完 function 以後就可以直接跳下一行了,檔案讀取完畢以後會把結果傳進 callback function。
在上面的程式碼中,readFileFinished 就是 callback function,就是美食街的呼叫器。「等餐點好了,讓呼叫器響」就跟「等檔案讀取完畢,讓 callback 被呼叫」是一樣的事情。
所以這一行:fs.readFile('./README.md', readFileFinished)的白話文解釋很簡單,就是:「請去讀取./README.md這個檔案,並且在讀取完畢以後呼叫readFileFinished,把結果傳進去」。
那我怎麼知道結果會怎麼傳進來?這就要看 API 文件了,每個 method 傳進來的參數都不一樣,以readFile來說,官方文件是這樣寫的:

裡面清楚寫到 callback 的第一個參數是 err,第二個參數是 data,也就是檔案內容。
所以fs.readFile做的事情很簡單,就是以某種不會阻塞的方式去讀取檔案,並且在讀取完成之後呼叫 callback function 並且把結果傳進去。
通常 callback function 都會使用匿名函式(Anonymous function)的寫法讓它變得更簡單,所以比較常見的形式其實是這樣:
// 讀取內建 fs 模組
const fs = require('fs')
// 讀取檔案
fs.readFile('./README.md', function(err, data) {
if (err) {
console.log(err)
} else {
console.log(data)
}
});可以想成就是直接在第二個參數的地方宣告一個 function 啦,因為沒有名稱也不用給名稱,所以就叫做匿名函式。
而readFile既然不會阻塞,就代表後面的程式碼會立刻執行,因此我們來把前面找偶數的版本改寫成非阻塞看看:
const fs = require('fs')
/*
原來的阻塞版本:
const file = fs.readFileSync('./README.md') // 在這邊等好幾秒才往下執行
*/
fs.readFile('./README.md', function(err, data) {
if (err) {
console.log(err)
} else {
console.log(data)
}
});
const arr = []
for (let i = 2; i <= 99999999; i+=2) {
arr.push(i)
}
console.log(arr)這樣子在等待讀檔的那幾秒鐘,系統就可以先往下執行做其他事情,不需要卡在那邊。
幫大家重點回顧一下:
- 阻塞(blocking)代表執行時程式會卡在那一行,直到有結果為止,例如說
readFileSync,要等檔案讀取完畢才能執行下一行 - 非阻塞(non-blocking)代表執行時不會卡住,但執行結果不會放在回傳值,而是需要透過回呼函式(callback function)來接收結果
同步與非同步
讀到這邊,你可能會疑惑說:「不是說要講同步(synchronous)與非同步(asynchronous)嗎?怎麼還沒出現?」
其實已經講完了。
Node.js 的官方文件是這麼說的:
Blocking methods execute synchronously and non-blocking methods execute asynchronously.
阻塞的方法會同步地(synchronously)執行,而非阻塞的方法會非同步地(asynchronously)執行
readFileSync最後面的 Sync 就是代表synchronous的意思,說明這個方法是同步的。而readFile則是非同步的。
如果硬要用中文字面上的意思去解釋,會非常的痛苦,會想說:「同步不是同時進行嗎?感覺比較像是非阻塞阿,但怎麼卻反過來了?」
我從程式設計該同步還是非同步?得到了一個啟發,那就是只要換個方式解釋「同步」在電腦的領域中代表的意思就行了。
現在請想像有一群人腳綁在一起,在玩兩人三腳。這時候我們若是想讓他們「統一步伐」,也就是大家的腳步一致(同步),該怎麼做呢?當然是大家互相協調互相等待啊,腳速比較快的要放慢,比較慢的要變快。如果你已經踏了第一步,要等還沒踏出第一步的,等到大家都踏出第一步之後,才能開始踏出第二步。
所以不同的人在協調彼此的步伐,試著讓大家的腳步一致,就必須互相等待,這個就是同步。
非同步就很簡單了,就是意思反過來。雖然在玩兩人三腳,但沒有想要等彼此的意思,大家都各踏各的,所以有可能排頭已經到終點了,排尾還在中間的地方,因為大家腳步不一致,不同步。
程式也是一樣的,前面提過的又要讀檔又要印出偶數的範例中,同步指的就是彼此互相協調互相等待,所以讀檔還沒完成的時候,是不能印偶數的,印出偶數一定要等到讀取檔案結束之後才能進行。
非同步就是說各做各的,你讀檔就讀你的,我繼續印我的偶數,大家腳步不一致沒關係,因為我們本來就不同步。
總之呢,在討論到 JavaScript 的同步與非同步問題時,基本上你可以把非同步跟非阻塞劃上等號,同步與阻塞劃上等號。如果你今天執行一個同步的方法(例如說readFileSync),就一定會阻塞;如果執行一個非同步的方法(readFile),就一定不會阻塞。
不過要幫大家稍微補充一下,如果你不是在 JavaScript 而是在其他的層次討論這個問題時,答案就不一樣了。舉例來說,當你在查阻塞非阻塞以及同步非同步的時候,一定會查到一些跟系統 I/O 有關的資料,我覺得那是不同層次的討論。
當你是在討論系統或是網路 I/O 的時候,非同步跟非阻塞講的就是兩件事情,同步跟阻塞也是兩件事,是有不同含義的。
但如果我們的 context 侷限在討論 JavaScript 的同步與非同步問題,基本上 blocking 就是 synchronous,non-blocking 就是 asynchronous。前面提到的 Node.js 的官方文件也是把這兩個概念給混用。
一旦我們把這兩個東西劃上等號,就很好理解什麼是同步,什麼是非同步了,我直接把上一個段落的重點回顧改一下就行了:
- 同步(synchronous)代表執行時程式會卡在那一行,直到有結果為止,例如說
readFileSync,要等檔案讀取完畢才能執行下一行 - 非同步(asynchronous)代表執行時不會卡住,但執行結果不會放在回傳值,而是需要透過回呼函式(callback function)來接收結果
瀏覽器上的同步與非同步
前面都是以 Node.js 當做例子,現在終於要回歸到我們比較熟悉的前端瀏覽器了。
在前端寫 JavaScript 的時候有一個很常見的需求,那就是跟後端 API 串接拿取資料。假設我們有一個函式叫做getAPIResponse好了,可以 call API 拿資料回來。
同步的版本會長得像這樣:
const response = getAPIResponse()
console.log(response)同步會發生什麼事?就會阻塞後面的執行,所以假設 API Server 主機規格很爛跑很慢需要等 10 秒,整個 JavaScript 引擎都必須等 10 秒,才能執行下一個指令。在我們用 Node.js 當範例的時候,有時候等 10 秒是可以接受的,因為只有執行這個程式的人需要等 10 秒而已,我可以去滑個 Instagram 再回來就好。
可是瀏覽器可以接受等 10 秒嗎?
你想想看喔,如果把 JavaScript 的執行凍結在那邊 10 秒,就等於說讓執行 JavaScript 的執行緒(thread)凍結 10 秒。在瀏覽器裡面,負責執行 JavaScript 的叫做 main thread,負責處理跟畫面渲染相關的也是 main thread。換句話說,如果這個 thread 凍結 10 秒,就代表你怎麼點擊畫面都不會有反應,因為瀏覽器沒有資源去處理這些其他的事情。
也就是說,你的畫面看起來就像當掉了一樣。
(如果不知道什麼是 thread,請參考:Inside look at modern web browser,建議從 part1 開始讀,main thread 在 part3 的地方)
舉一個生活中的例子來比喻,如果你去你家巷口的店面點一塊雞排,點完之後一定要在現場等,這時候如果你朋友來找你玩,按你家門鈴,你就沒辦法回應,因為你不在家。所以你朋友只好乾等在那邊,等你買完雞排才能幫他們開門。
但如果店家導入了線上排隊系統,點完雞排之後可以透過 App 查看雞排製作狀況,那你就可以回家邊看電視邊等雞排,這時候如果朋友來按門鈴,你就可以直接幫他們開門,你朋友不用乾等。
「等雞排」指的就是「等待 Response」,「幫你朋友開門」指的就是「針對畫面的反應」,而「你」就是「main thread」。在你忙著等雞排的時候,是沒辦法幫朋友開門的。
畫面凍結的部分可以自己做一個很簡單的 demo 來驗證,只要建立一個這樣的 html 檔案就好了:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
</head>
<body>
<div>凍結那時間,凍結初遇那一天</div>
</body>
<script>
var delay = 3000 // 凍結 3 秒
var end = +new Date() + delay
console.log('delay start')
while(new Date() < end) {
}
console.log('delay end')
</script>
</html>原理就是裡面的 while 會不斷去檢查時間到了沒,沒到的話就繼續等,所以會阻塞整個 main thread。也可以參考底下的 gif,在 delay end 出現之前,怎麼反白文字都沒有用,直到 delay end 出現以後才正常:
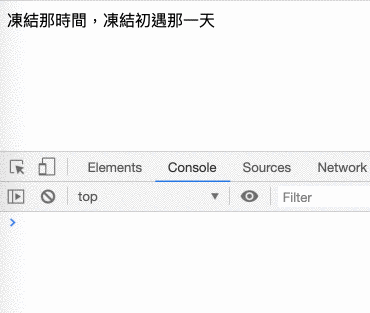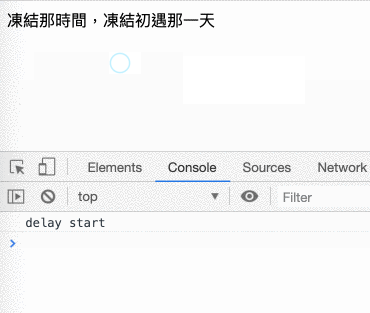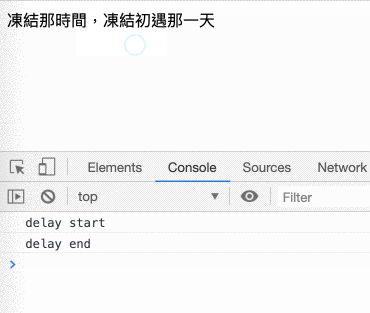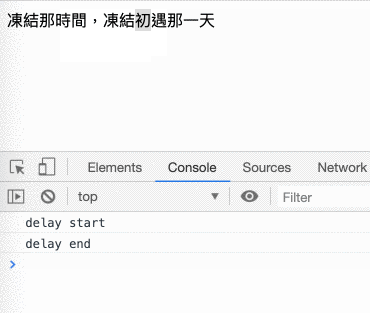
你可以接受畫面凍結嗎?不行嘛,就算你可以接受,你老闆、你客戶也不可能接受,所以像是網路這麼耗時的操作,是不可能讓它同步執行的。既然要改成非同步,那依據之前學過的,就要改成用 callback function 來接收結果:
// 底下會有三個範例,都在做一模一樣的事情
// 主要是想讓初學者知道底下三個是一樣的,只是寫法不同
// 範例一
// 最初學者友善的版本,額外宣告函式
function handleResponst() {
console.log(response)
}
getAPIResponse(handleResponst)
// 範例二
// 比較常看到的匿名函式版本,功能跟上面完全一樣
getAPIResponse(function(err, response) {
console.log(response)
})
// 範例三
// 利用 ES6 箭頭函式簡化過後的版本
getAPIResponse((err, response) => {
console.log(response)
})AJAX 的全名是:Asynchronous JavaScript and XML,有沒有看到開頭那個 A 的全名是:Asynchronous,就代表是非同步送出 Request 的意思。
上面我們用了一個假想中的函式 getAPIResponse 來做示範,主要是想說明「網路操作在前端不可能用同步的方式」,接著可以來看一下實際在前端呼叫後端 API 的程式碼會長什麼樣子:
var request = new XMLHttpRequest();
request.open('GET', 'https://jsonplaceholder.typicode.com/users/1', true);
request.onload = function() {
if (this.status >= 200 && this.status < 400) {
console.log(this.response)
}
};
request.send();你可能會想說:咦,怎麼看起來不太一樣?callback function 在哪裡?
這邊的 callback function 就是 request.onload = 後面的那個函式,這一行的意思就是說:「當 response 回來時,請執行這個函式」。
此時,眼尖的人可能會發現:「咦?怎麼request.onload這個形式有點眼熟?」
你以為陌生卻熟悉的 callback
callback function 的意思其實就是:「當某事發生的時候,請利用這個 function 通知我」,雖然乍看之下會以為很陌生,但其實你早就在用了。
例如說:
const btn = document.querySelector('.btn_alert')
btn.addEventListener('click', handleClick)
function handleClick() {
alert('click!')
}「當某事(有人點擊 .btn_alert 這個按鈕)發生時,請利用這個 function(handleClick)通知我」,handleClick不就是個 callback function 嗎?
又或者是:
window.onload = function() {
alert('load!')
}「當某事(網頁載入完成)發生時,請利用這個 function(匿名函式)通知我」,這不也是 callback function 嗎?
再舉最後一個範例:
setTimeout(tick, 2000)
function tick() {
alert('時間到!')
}「當某事(過了兩秒)發生時,請利用這個 function(tick)通知我」,這都是一樣的模式。
在使用 callback function 時,有一個初學者很常犯的錯誤一定要特別注意。都說了傳進去的參數是 callback function,是一個「function」,不是 function 執行後的結果(除非你的 function 執行完會回傳 function,這就另當別論)。
舉例來說,標準錯誤範例會長得像這樣:
setTimeout(tick(), 2000)
function tick() {
alert('時間到!')
}
// 或者是這樣
window.onload = load()
function load() {
alert('load!')
}tick是一個 function,tick()則是執行一個 function,並且把執行完的回傳結果當作 callback function,簡單來講就是這樣:
// 錯誤範例
setTimeout(tick(), 2000)
function tick() {
alert('時間到!')
}
// 上面的錯誤範例等同於
let fn = tick()
setTimeout(fn, 2000)
function tick() {
alert('時間到!')
}由於 tick 執行後會回傳 undefined,所以 setTimeout 那行可以看成:setTimeout(undefined, 2000),一點作用都沒有。
把 function 誤寫成 function call 以後,會產生的結果就是,畫面還是跳出「時間到!」三個字,可是兩秒還沒過完。因為這樣寫就等於是你先執行了 tick 這個 function。
window.onload 的例子也是一樣,可以看成是這樣:
// 錯誤範例
window.onload = load()
function load() {
alert('load!')
}
// 上面的錯誤範例等同於
let fn = load()
window.onload = fn所以網頁還沒載入完成時就會執行 load 這個 function 了。
再次重申,tick 是 function,tick()是執行 function,這兩個的意思完全不一樣。
幫大家重點複習:
- 瀏覽器裡執行 JavaScript 的 main thread 同時也負責畫面的 render,因此非同步顯得更加重要而且必須,否則等待的時候畫面會凍結
- callback function 的意思其實就是:「當某事發生的時候,請利用這個 function 通知我」
fn是一個 function,fn()是執行 function
Callback function 的參數
前面有提到說 callback function 的參數需要看文件才能知道,我們舉底下這個點擊按鈕為例:
const btn = document.querySelector('.btn_alert')
btn.addEventListener('click', handleClick)
function handleClick() {
alert('click!')
}從 MDN 的文件上,你可以看到它是這樣寫的:
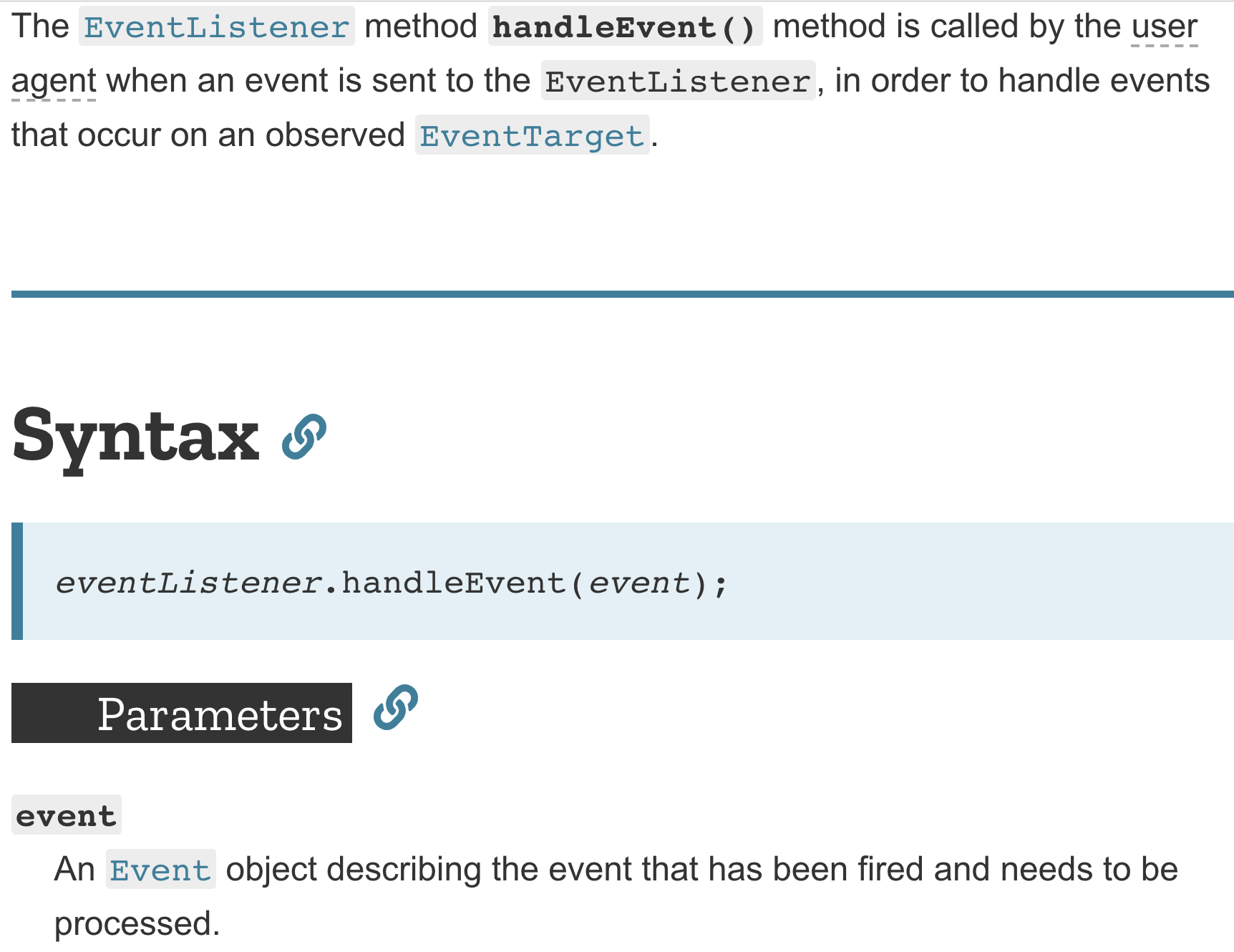
一個叫做 event 的 object 會被傳進去,而這個 object 是在描述這個發生的事件。聽起來很抽象,但我們可以實際來實驗看看:
const btn = document.querySelector('.btn_alert')
btn.addEventListener('click', handleClick)
function handleClick(e) {
console.log(e)
}當我們點擊這個按鈕之後,可以看到 console 印出了一個有超級多屬性的物件:
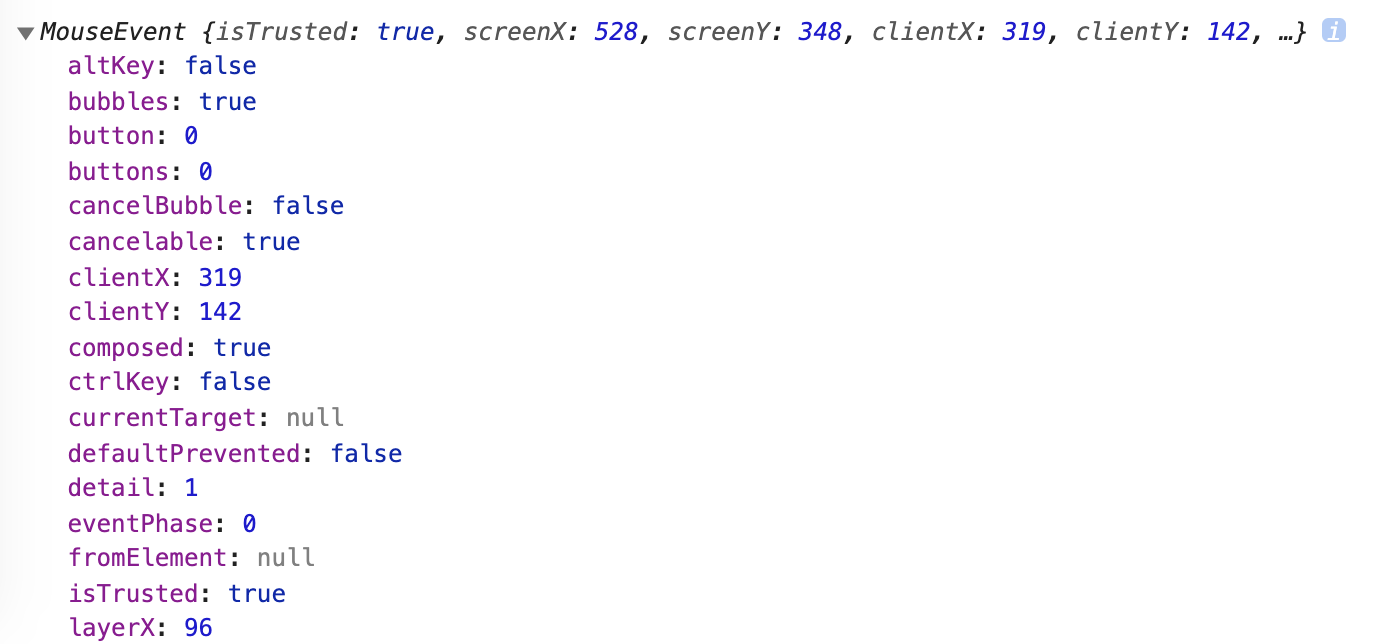
仔細看你會發現這個物件其實就是在描述我剛剛的「點擊」,例如說 clientX 與 clientY 其實代表著剛剛這個點擊的座標。最常用的,你一定也聽過的就是e.target,可以拿到這個點擊事件發生的 DOM 物件。
不過這時新手可能會有個疑問:「剛剛文件上明明寫說傳進來的參數叫做 event,為什麼你用 e 也可以?」
這是因為 function 在傳送以及接收參數的時候,注重的只有「順序」,而不是文件上的名稱。文件上的名稱只是參考用的而已,並不代表你就一定要用那個名稱來接收。function 沒有那麼智慧,不會根據變數名稱來判斷是哪個參數。
所以你的 callback function 參數名稱想要怎麼取都可以,handleClick(e)、handleClick(evt)、handleClick(event) 或是 handleClick(yoooooo)都可以,都可以拿到瀏覽器所傳的event這個物件,只是叫做不同名稱而已。
Callback function 會接收什麼參數,要看文件才會知道。如果沒有文件的話,沒有人知道 callback 會被傳什麼參數進來。
話雖然是這樣講,但其實在很多地方,參數都會遵循一個慣例。
Callback 的 error first 慣例
同步與非同步的差別除了 callback 以外還有一個,那就是錯誤處理。
回到我們開頭舉的那個同步讀取檔案的範例:
const fs = require('fs') // 引入內建 file system 模組
const file = fs.readFileSync('./README.md') // 讀取檔案
console.log(file) // 印出內容如果今天 ./README.md 這個檔案不存在,執行之後就會在 console 印出錯誤訊息:
fs.js:115
throw err;
^
Error: ENOENT: no such file or directory, open './README.md'
at Object.openSync (fs.js:436:3)
at Object.readFileSync (fs.js:341:35)要處理這種錯誤,可以用 try...catch 的語法去包住:
const fs = require('fs') // 引入內建 file system 模組
try {
const file = fs.readFileSync('./README.md') // 讀取檔案
console.log(file) // 印出內容
} catch(err) {
console.log('讀檔失敗')
}當我們用 try...catch 包住以後,就能夠針對錯誤進行處理,以上面的例子來說,就會輸出「讀檔失敗」這四個字。
可是如果換成非同步的版本,事情就有點不太一樣了,請先看底下的範例程式碼:
const fs = require('fs') // 引入內建 file system 模組
try {
// 讀取檔案
fs.readFile('./README.md', (err, data) => {
console.log(data) // 印出內容
})
} catch(err) {
console.log('讀檔失敗')
}執行以後,console 居然沒有任何反應!明明發生了錯誤,可是卻沒有被 catch 到,這是為什麼呢?
這就是同步與非同步另一個巨大的差異。
在同步的版本當中,我們會等待檔案讀取完畢才執行下一行,所以讀取檔案的時候出了什麼錯,就會把錯誤拋出來,我們就可以 try…catch 去處理。
但是在非同步的版本中,fs.readFile這個 function 只做了一件事,就是跟 Node.js 說:「去讀取檔案,讀取完之後呼叫 callback function」,做完這件事情之後就繼續執行下一行了。
所以讀取檔案那一頭發生了什麼事,我們是完全不知道的。
舉個例子,這就好像是餐廳的內外場,假設我負責外場,有人點了一碗牛肉麵,我就會朝廚房大喊:「一碗牛肉麵!」,就繼續服務下一個客戶了。喊完之後內場有沒有真的開始做牛肉麵?我不知道,但應該要有。內場如果牛肉賣完了做不出來,我喊的當下也是不會知道的。
那我要怎麼知道?
假設牛肉真的賣完了,內場會主動來跟我說嘛,這時候我才會知道牛肉賣完了。
這就好像非同步的範例一樣,那一行只負責告訴系統「去讀檔」,剩下的不甘它的事,如果發生什麼事,必須主動告訴它,要用 callback 的方式來傳遞。
我們再複習一次開頭提過的 Node.js 的 readFile 的文件:
callback 會有兩個參數,第一個是 err,第二個是 data,這樣你就知道 err 是怎麼來的了。只要在讀檔的時候碰到任何錯誤,例如說檔案不存在、檔案超過記憶體大小或是檔案沒有權限開啟等等,都會透過這個 err 參數傳進來,這個錯誤你用 try…catch 是抓不到的。
所以,當我們非同步地執行某件事情的時候,有兩點我們一定會想知道:
- 有沒有發生錯誤,有的話錯誤是什麼
- 這件事情的回傳值
舉例來說,讀取檔案我們會想知道有沒有錯誤,也想知道檔案內容。或是操作資料庫,我們會想知道指令有沒有下錯,也想知道回傳的資料是什麼。
既然非同步一定會想知道這兩件事,那就代表至少會有兩個參數,一個是錯誤,另一個是回傳值。小標題所說的「error first」,就代表錯誤「依照慣例」通常會放在第一個參數,其他回傳值放第二個以及第二個之後。
為什麼呢?
因為錯誤只會有一個,但回傳值可能有很多個。
舉例來說,假設有一個getFileStats的 function 會非同步地去抓取檔案狀態,並且回傳檔案名稱、檔案大小、檔案權限以及檔案擁有者。如果把 err 放最後一個參數,我們的 callback 就會長這個樣子:function cb(fileName, fileSize, fileMod, fileOwner, err)
我一定要把所有參數都明確地寫出來,我才能拿到 err。換句話說,假設我今天只想要檔案名稱跟檔案大小,其他的我不在意,該怎麼辦?不怎麼辦,一樣得寫這麼長,因為 err 在最後一個。
如果把 err 擺前面的話,我就只要寫:function cb(err, fileName, fileSize) 就好,後面的參數我不想拿的話不要寫就好。
這就是為什麼要把 err 擺在最前面,因為我們一定會需要 err,但不一定需要後面所有的參數。因此你只要看到有 callback function,通常第一個參數都代表著錯誤訊息。
所以很常會看到這種處理方式,先判斷有沒有錯誤再做其他事情:
const fs = require('fs')
fs.readFile('./README.md', (err, data) => {
// 如果錯誤發生,處理錯誤然後返回,就不會繼續執行下去
if (err) {
console.log(err)
return
}
console.log(data)
});最後補充三點,第一點是 error first 只是個「慣例」,實際上會傳什麼參數還是要根據文件而定,你也可以寫一個把錯誤放在最後一個參數的 API 出來(但你不應該這樣做就是了)。
第二點是儘管是非同步,還是有可能利用 try catch 抓到錯誤,但是錯誤的「類型」不一樣,例如說:
const fs = require('fs')
try {
// 讀取檔案
fs.readFile('./README.md')
} catch(err) {
console.log('讀檔失敗')
console.log(err)
// TypeError [ERR_INVALID_CALLBACK]: Callback must be a function
}這邊抓到的錯誤並不是「讀取檔案」所產生的錯誤,而是「呼叫讀取檔案這個 fucntion」所產生的錯誤。以前面餐廳的例子來說,就是客人點餐的時候你就知道東西賣完了,所以你根本不必去問內場,就可以直接跟客人說:「不好意思我們牛肉麵賣完囉,你要不要考慮點別的」。
最後一點想補充的是,有些人可能會問說:「那為什麼 setTimeout 或是 event listener 這些東西都沒有 err 這個參數?」
那是因為這幾個東西的應用場合不太一樣。
setTimeout 的意思是:「過了 n 秒後,請呼叫這個 function」,而 event listener 的意思是:「當有人點擊按鈕,請呼叫這個 function」。
「過了 n 秒」以及「點擊按鈕」這兩件事情是不會發生錯誤的。
但像是 readFile 去讀取檔案,就有可能在讀取檔案時發生錯誤;而 XMLHttpRequest 則是有另外的 onerror 可以用來捕捉非同步所產生的錯誤。
一樣來整理重點:
- callback function 的參數跟一般 function 一樣,是看「順序」而不是看名稱,沒有那麼智慧
- 依照慣例,通常 callback function 的第一個參數都是 err,用來告訴你有沒有發生錯誤(承第一點,你想取叫 e、error 或是 fxxkingError 都可以)
- 非同步還是有可能用 try catch 抓到錯誤,但那是代表你在「呼叫非同步函式」的時候就產生錯誤
理解非同步的最後一塊拼圖:Event loop
前面講了這麼多非同步的東西,你有沒有想過非同步到底是怎麼做的?
不是常常聽別人說 JavaScript 是 single thread,只有一個執行緒在跑嗎?可是如果真的是 single thread,怎麼可能達成非同步?
想要理解非同步操作到底怎麼達成的,我唯一推薦這個影片:What the heck is the event loop anyway? | Philip Roberts | JSConf EU,每個看過的人都讚不絕口。
只要你看了這個影片,就會知道非同步背後是怎麼一回事了。因為這影片實在是講得太好了,因此我底下只會幫大家重點複習一下,請看完影片再往下閱讀,如果你還沒看的話…看一下啦,拜託。
在程式的執行裡面,會有一個東西叫做 call stack,基本上就是紀錄著每個 function 執行時需要用到的資源,以及記錄著 function 執行的順序。
舉例來說,考慮以下程式碼:
function a() {
return 1
}
function b() {
a()
}
function c() {
b()
}
c()我們先呼叫了 c,所以 call stack 長這樣(底下的範例會往上長):
cc 裡面呼叫了 b:
b
cb 裡面再呼叫了 a:
a
b
c當 a 執行完之後要回到哪一個 function 呢?很簡單,把 a 從 call stack 移除,在最上面的那個就是了:
b
c接著 b 執行完,從 call stack 裡面拿出來:
cc 執行完,call stack 清空,程式執行結束。
記錄著 function 執行順序以及其他需要的東西的地方就是 call stack,而知名的錯誤 stack overflow 指的就是 stack 太多東西滿出來了,例如說你遞迴呼叫一個 function 十萬次,stack 沒辦法存這麼多東西,於是就丟出 stack overflow 的錯誤。
JavaScript 的「只有一個 thread」指的就是只有一個 call stack,所以同一個時間只能執行一件事情。
那非同步到底是怎麼做到的呢?
我只說「JavaScript 同一個時間只能執行一件事」,但是並沒有說「執行環境也是如此」。
例如說讀檔好了,我們上面把非同步讀檔的程式碼解釋為:「叫系統去讀檔,讀完檔之後透過 callback function 把結果傳回來」,在這背後 Node.js 可以用另一個 thread 去讀取檔案,這是完全沒有問題的。
setTimeout 也是如此,setTimeout(fn, 2000) 只是在告訴瀏覽器說:「2 秒以後幫我呼叫 fn 這個 function」,瀏覽器就可以開另外一個 thread 去計時,而不是利用 main thread。
重點是,當這些其他 thread 的事情做完以後,要怎麼樣重新丟回 main thread?因為只有 main thread 可以執行 JavaScript 嘛,所以一定要丟回去,不然沒辦法跑。
這就是 event loop 在做的事情了。
先來看一張經典的圖:
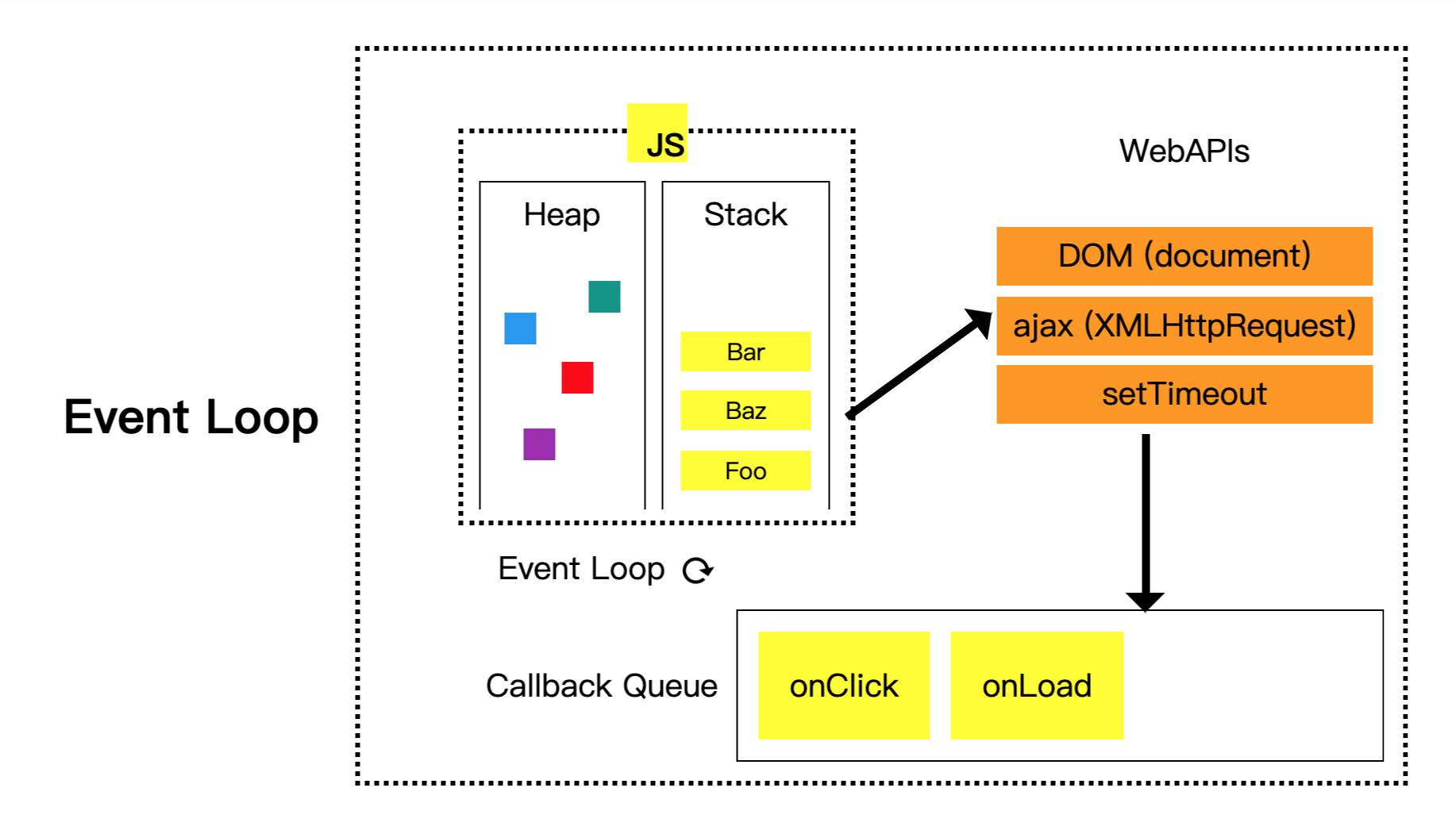
(圖片來源:Understanding Event Loop, Call Stack, Event & Job Queue in Javascript 裡面附的 codepen 截圖)
我們先來解釋右半部,假設我們執行了 setTimeout(fn, 2000) 這一行程式碼,會先把 setTimeout(fn, 2000) 丟到 call stack 去執行,然後 setTimeout 屬於 Web API,所以會跟瀏覽器說:「欸欸,幫我設定一個計時器,2000 毫秒以後呼叫 fn」,然後就執行結束,從 call stack 裡面 pop 掉。
當瀏覽器的計時器時間一到,就會把 fn 這個 function 丟進去 callback queue,為什麼這邊要有一個 queue 呢?因為可能會有很多 callback function 都在等待執行嘛,所以需要有一個排隊機制讓大家在這邊排隊,一個一個慢慢來,所以才叫做 callback queue,而不是 callback array 或是 callback stack。
接著就是重點 event loop 了,它扮演的角色很簡單,用白話文講就是:
不斷偵測 call stack 是否為空,如果是空的話就把 callback queue 裡面的東西丟到 call stack
以程式的角度去想,event loop 之所以叫做 loop,就是因為它可以表示成這樣:
while(true) {
if (callStack.length === 0 && callbackQueue.length > 0) {
// 拿出 callbackQueue 的第一個元素,並放到 callStack 去
callStack.push(callbackQueue.dequeue())
}
}就是這樣子而已,就是那麼簡單。
這就好像很多知名的博物館都有人數管制,你得先去買票,買票完以後去排隊。接著門口的警衛看到前面的人都已經到下一個景點了,才會把隊伍裡面的人放進來。
while(true) {
if (博物館入口沒有人 && 排隊的隊伍有人) {
放人進去博物館()
}
}這邊只要掌握一個重點就好:「非同步的 callback function 會先被放到 callback queue,並且等到 call stack 為空時候才被 event loop 丟進去 call stack」
Event loop 就是那種只會出一張嘴不會做事的人,它不負責幫你執行 callback function,只會幫你把 function 丟到 call stack,真正在執行的還是 JavaScript 的 main thread。
理解 event loop 這個機制之後,就可以來解釋非同步的行為了,這邊影片裡面已經解釋得很清楚了,我就不再多講了,我只舉一個常見的範例:
setTimeout(() => {
console.log('0ms')
}, 0)
console.log('hello')請問是 hello 會先被印出來,還是 0ms 會先被印出來,還是不一定?
如果你的答案不是「hello 會先被印出來」,就代表其實沒有理解 event loop 這個機制,麻煩回去把影片重看一遍。
上面的範例中那個 callback function 會在 0ms 之後被放到 callback queue 去,但請注意,這時候 call stack 還不是空的,所以 console.log('hello') 會先被執行,執行完之後 call stack 清空,event loop 才把 callback 放到 call stack,然後才執行 callback 裡面的 console.log('0ms')。
所以輸出的順序保證會是 hello 先,再來才是 0ms。
最後做幾個小補充,第一個是 setTimeout 傳 0 只是代表「儘快執行」,不一定在 0ms 以後就會觸發,可能會是 4ms 或是更長,詳情可參考:MDN: Reasons for delays longer than specified
第二個補充是 event loop 其實還有一個小細節,那就是 callback queue 還區分成 macro task 跟 micro task 兩種,但這個有點小複雜,以後有機會再說。
第三個補充是雖然 Node.js 跟瀏覽器都有 event loop,但就像這兩個執行環境都有 setTimeout 一樣,背後的原理跟實作是不同的。大致上相同,但是細節不同。
第四個補充是上面提到的「只有 main thread 可以執行 JavaScript」其實不正確,因為在瀏覽器裡面有 Web Worker 可以用。
非同步小測驗
在理解了非同步的原理 event loop 之後,照理來說你應該要對非同步的執行相當熟悉了,底下我會給出幾個題目,讓你驗證一下自己是否有真的理解:
1. 活動網站
小明在一間專門辦活動的網站擔任前端工程師,被主管指派一個任務,那就是要加一段程式碼,呼叫後端 API 來取得「活動是否已經開始」,開始的話才前往活動頁,否則就不做任何事。
假設getAPIResponse是一個非同步的 function,會利用 ajax 去呼叫 API 之後取得結果,而/event這個 API 會回傳 JSON 格式的資料,其中started這個 boolean 的欄位代表著活動是否已經開始。
於是小明寫出以下程式碼:
// 先設一個 flag 並且設為 false,表示活動沒開始
let isEventStarted = false
// call API 並取得結果
getAPIResponse('/event', response => {
// 判斷活動是否開始並設置 flag
if (response.started) {
isEventStarted = true
}
})
// 根據 flag 決定是否前往活動頁面
if (isEventStarted) {
goToEvent()
}請問:這段程式碼有沒有問題?如果有的話,問題在哪裡?
2. 慢慢等
在完成了活動網頁之後,小明覺得自己對非同步好像還是沒有那麼熟悉,於是就想來做個練習,寫出了底下的程式碼:
let gotResponse = false
getAPIResponse('/check', () => {
gotResponse = true
console.log('Received response!')
})
while(!gotResponse) {
console.log('Waiting...')
}
意思就是在 ajax 的 response 回來之前會不斷印出 waiting,直到接收到 response 才停止。
請問:以上寫法可以滿足小明的需求嗎?如果不行,請詳述原因。
3. 詭異的計時器
小明被主管指派要去解一個 bug,在公司的程式碼裡面找到了這一段:
setTimeout(() => {
alert('Welcome!')
}, 1000)
// 後面還有其他程式碼,這邊先略過這個 bug 是什麼呢?就是這個計時器明明指定說 1 秒之後要跳出訊息,可是執行這整段程式碼(注意,底下還有其他程式碼,只是上面先略過而已)以後,alert 卻在 2 秒以後才跳出來。
請問:這有可能發生嗎?無論你覺得可能或不可能,都請試著解釋原因。
4. 執行順序大考驗
a(function() {
console.log('a')
})
console.log('hello')請問:最後的輸出順序為何?是先 hello 再 a,還是先 a 再 hello,還是不一定?
底下會針對每一題來做解答,強烈建議上面四題自己思考完以後再往下滑。
解答:1. 活動網站
答案是有問題,這整段程式碼把同步與非同步混著寫,是最常見的錯誤。
要等 call stack 清空以後,event loop 才會把 callback 丟到 call stack,所以最後判斷 isEventStarted 的這一段程式碼會先被執行。當執行到這一段的時候,儘管 response 已經回來了,但 callback function 還在 callback queue 裡面待著,所以判斷isEventStarted的時候一定會是 false。
正確的方法是把判斷活動是否開啟的邏輯放在 callback 裡面,就可以確保拿到 response 以後才做判斷:
// call API 並取得結果
getAPIResponse('/event', response => {
// 判斷活動是否開始並設置 flag
if (response.started) {
goToEvent()
}
})解答:2. 慢慢等
答案是不行。
還記得 event loop 的條件嗎?「當 call stack 為空,才把 callback 丟到 call stack」。
while(!gotResponse) {
console.log('Waiting...')
}這一段程式碼會不斷執行,成為一個無窮迴圈。所以 call stack 永遠都有東西,一直被佔用,callback queue 裡面的東西根本丟不進 call stack。
因此小明原本的程式碼無論有沒有拿到 response,都只會一直印出 waiting。
解答:3. 詭異的計時器
答案是有可能。
WebAPI 會在一秒之後把 callback 丟到 callback queue,那為什麼兩秒之後才會執行呢?因為這一秒 call stack 被佔用了。
只要 setTimeout 底下的程式碼做了很多事情並佔用了一秒鐘,callback 就會在一秒之後才被丟到 call stack 去,例如說:
setTimeout(() => {
alert('Welcome!')
}, 1000)
// 底下這段程式碼會在 call stack 佔用一秒鐘
const end = +new Date() + 1000
while(end > new Date()){
}所以 setTimeout 只能保證「至少」會在 1 秒後執行,但不能保證 1 秒的時候一定執行。
解答:4. 執行順序大考驗
答案是不一定。
因為我沒有說a是同步還是非同步的,你不要看到 callback 就以為是非同步。
我的 a 可以這樣實作:
function a(fn) {
fn() // 同步執行 fn
}
a(function() {
console.log('a')
})
console.log('hello')輸出就會是 a 然後 hello。
也可以這樣實作:
function a(fn) {
setTimeout(fn, 0) // 非同步執行 fn
}
a(function() {
console.log('a')
})
console.log('hello')輸出就是 hello 然後才 a。
結語
想要理解非同步的話必須一步一步來,不要想著一步登天。
這也是為什麼標題會叫做「先成為 callback 大師」,因為你得先對 callback 有一定的熟練程度之後才能進入下一個階段,這樣會容易很多。
這一篇主要是想幫大家建立起幾個重要的觀念:
- 什麼是阻塞?什麼是非阻塞?
- 什麼是同步?什麼是非同步?
- 同步與非同步的差別在哪裡?
- 為什麼需要非同步?
- callback 是什麼?
- 為什麼需要 callback?
- callback 的 error first 慣例
- 什麼是 event loop?它做了什麼?
- 非同步常見的坑有哪些?
若是能夠完全理解這篇,並且把文末的小測驗徹底搞懂,我相信你對非同步的理解應該就沒什麼問題了,實作上也能順利許多。在理解非同步基礎以及 callback 之後,下一篇將會講到使用 callback function 會碰到的問題以及解決方案:Promise,也會稍微提一下比較新的語法 async/await。
(目前還沒有下集,有了之後我會補上)
參考資料:
評論