Recently, I shared this topic at the online pre-event of JSDC. Since I already shared it, I thought it would be good to write an article. The inspiration and content of this article actually come from “JavaScript Relearning” (only available in Chinese). When I wrote the book, I referenced some elements from the React source code, and this article is just a reorganization and rewriting of the various React-related chapters that were originally scattered throughout the book.
I find it interesting to learn new concepts from the code of these open-source projects. After all, the more bugs these widely used frameworks encounter, the more solutions to these problems can be learned, allowing for reflection on what one has previously learned.
This article is divided into three small sections:
- XSS Vulnerabilities in Older Versions of React
- Learning the Event Loop from React Fiber
- Learning Underlying Mechanics from V8 Bugs
XSS Vulnerabilities in Older Versions of React
What security issues can you find in the following code?
function Test() {
const name = qs.parse(location.search).name;
return (
<div className="text-red">
<h1>{name}</h1>
</div>
)
}At first glance, it seems there’s no problem, right? Isn’t it just rendering a name? In React, it automatically encodes, so even if an <img> is inserted, it won’t be parsed as a tag but will be converted to plain text, which seems fine.
If we continue to expand this code, transforming JSX into JavaScript, it would look something like this:
function Test() {
const name = qs.parse(location.search).name;
return createElement(
'div',
{ className: 'text-red' },
createElement(
'h1',
{},
name
)
)
}JSX syntax is converted back to JavaScript during compilation. The old version uses React.createElement, while the new version has changed to _jsx, but regardless of how the API looks, it’s essentially a piece of JavaScript that creates an element.
After these functions are executed, they produce what is known as the virtual DOM. If we expand it into an object, it would look like this:
function Test() {
const name = qs.parse(location.search).name;
return ({
type: 'div',
props: {
className: 'text-red',
children: {
type: 'h1',
props: {
children: name
}
}
}
})
}When React renders, it will render based on this object and display the name we passed in.
But the problem arises: libraries like qs actually support objects. For example, ?name[test]=1 would make name become {"test": 1}. Therefore, although this name should appear to be a string, it can actually be an object.
Even though passing objects is usually blocked by React, have you ever thought that these components are also objects? So how does React determine whether an object is a component?
In older versions of React, this check is very simple:
ReactElement.isValidElement = function(object) {
return !!(
typeof object === 'object' &&
object !== null &&
'type' in object &&
'props' in object
)
}As long as there is a type and props, it is considered a React component. Therefore, if our name looks like this:
{
type: "div",
props: {
dangerouslySetInnerHTML: {
__html: "<img src=x onerror=alert()>"
}
}
}It would be treated as a React component and rendered accordingly.
In this way, this feature is successfully exploited to pretend to be a React component and render arbitrary HTML, creating an XSS vulnerability.
This vulnerability was first discovered by Daniel LeCheminan in 2015, who wrote an article: XSS via a spoofed React element, although the context in the original text is slightly different.
In summary, this issue caught React’s attention, leading to a discussion in an issue: How Much XSS Vulnerability Protection is React Responsible For? #3473, and the final fix can be found here: Use a Symbol to tag every ReactElement #4832.
The solution is: Symbol.
By adding a $$typeof: Symbol.for('react.element') to the React component and including this check in isValidElement, we can ensure that other objects cannot forge a React component.
The underlying principle is the characteristic of symbols; unlike regular objects, a symbol is only equal to the same symbol, and JSON deserialization does not support symbols. Therefore, you can only create ordinary objects and cannot create a symbol, which naturally prevents the forgery of components.
In the future, if someone asks you where symbols can be used, you can use this case as an answer.
Additionally, this is not only applicable to the frontend; the backend is the same. For example, in older versions of JavaScript ORM: Sequelize, operators were also represented as strings, such as:
Post.findAll({
where: {
authorId: {
'$or': [12, 13]
}
}
});However, starting from v5, they have all been replaced with symbols, and the original strings have been deprecated:
const { Op } = require('sequelize');
Post.findAll({
where: {
authorId: {
[Op.or]: [12, 13]
}
}
});
// operators.ts
export const Op: OpTypes = {
eq: Symbol.for('eq'),
ne: Symbol.for('ne'),
gte: Symbol.for('gte'),
or: Symbol.for('or'),
// [...]
}The underlying reason is the same, which is a consideration for information security. The original PR can be found here: Secure operators #8240.
By the way, during a live stream, someone asked, if you can create a symbol, does that mean these defenses are useless? The answer is: yes. But usually, to create a symbol, either you already have the ability to execute code, or the developer needs to add a deserializer that can create symbols, both of which are quite difficult to achieve.
Learning Event Loop from React Fiber
In 2018, I wrote an article related to React Fiber: A Brief Discussion on React Fiber and Its Impact on Lifecycles, and the mechanism can be summed up as: “breaking large synchronous tasks into multiple asynchronous small tasks” to avoid blocking the main thread.
So how can this mechanism be implemented in JavaScript? How should these asynchronous tasks be scheduled?
React 16.0.0 - requestIdleCallback
In the earliest version of React 16.0.0, it used the browser’s built-in API: requestIdleCallback. The MDN description is:
The window.requestIdleCallback() method queues a function to be called during a browser’s idle periods. This enables developers to perform background and low priority work on the main thread, without impacting latency-critical events such as animation and input response.
After breaking the original large task into smaller tasks, requestIdleCallback is used to schedule the next task, allowing the browser to execute it when idle, thus not blocking the main thread.
React 16.4.0 - requestAnimationFrame + postMessage
However, in React 16.4.0, it was replaced with a combination of requestAnimationFrame (hereafter referred to as rAF) and postMessage (this method was initially intended as a fallback for when requestIdleCallback was not available, but in this version, it was promoted and directly replaced requestIdleCallback).
In this mechanism, two types of callbacks are created: one is a callback scheduled using rAF, which is automatically triggered by the browser, and the other is a callback scheduled using window.addEventListener('message', fn), triggered through window.postMessage.
The actual operation of this mechanism works like this: each tick below represents one event loop. We first schedule an rAF, and within it, calculate the time when the next rAF should be triggered (which is the current time + frame length, e.g., 16ms):
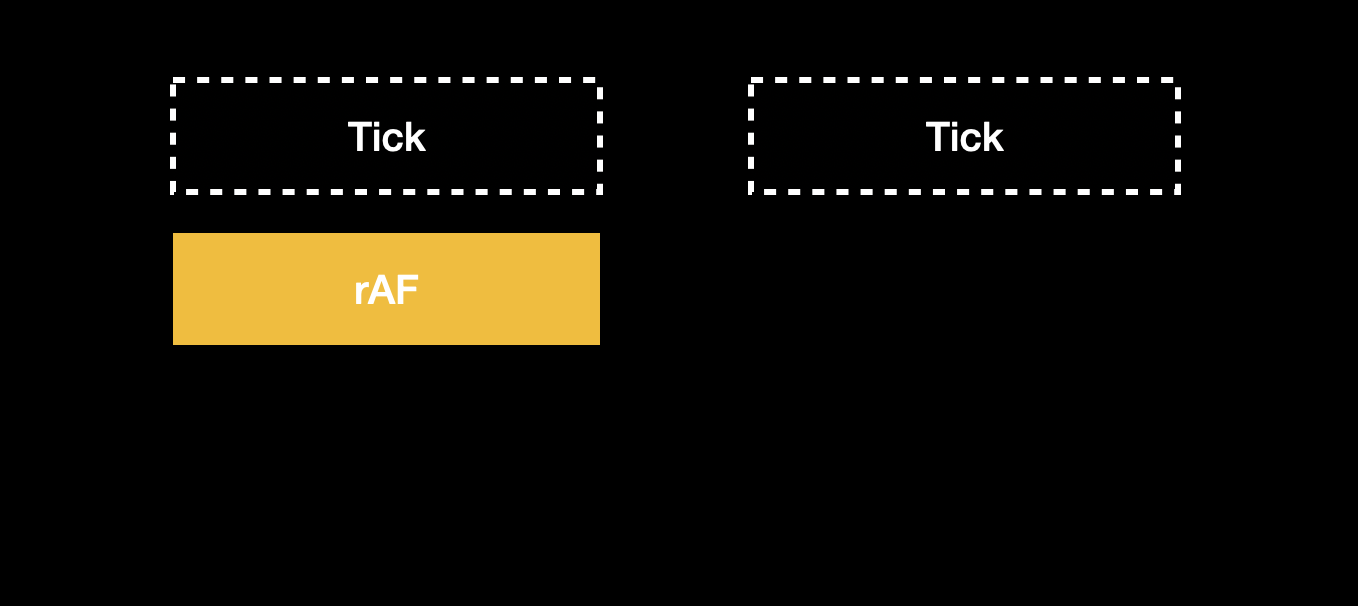
Next, call rAF and postMessage again inside to schedule the callback for the next tick:
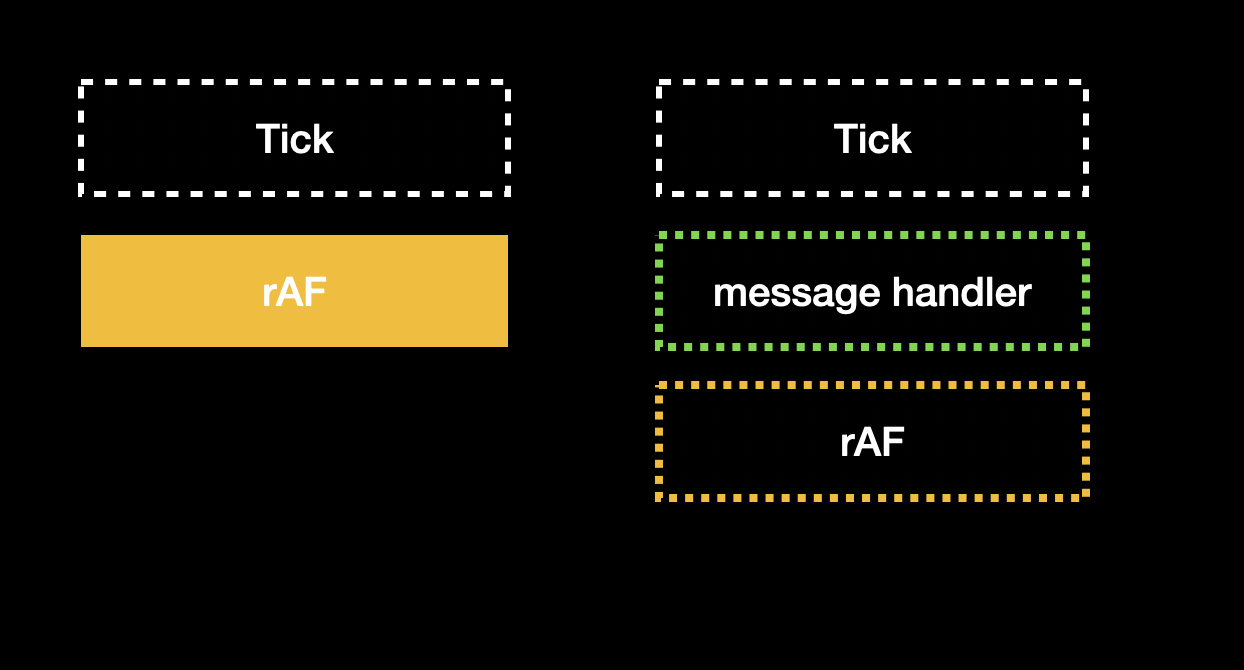
The next step is browser render. After it finishes, it enters the next tick, and then the message handler is triggered:
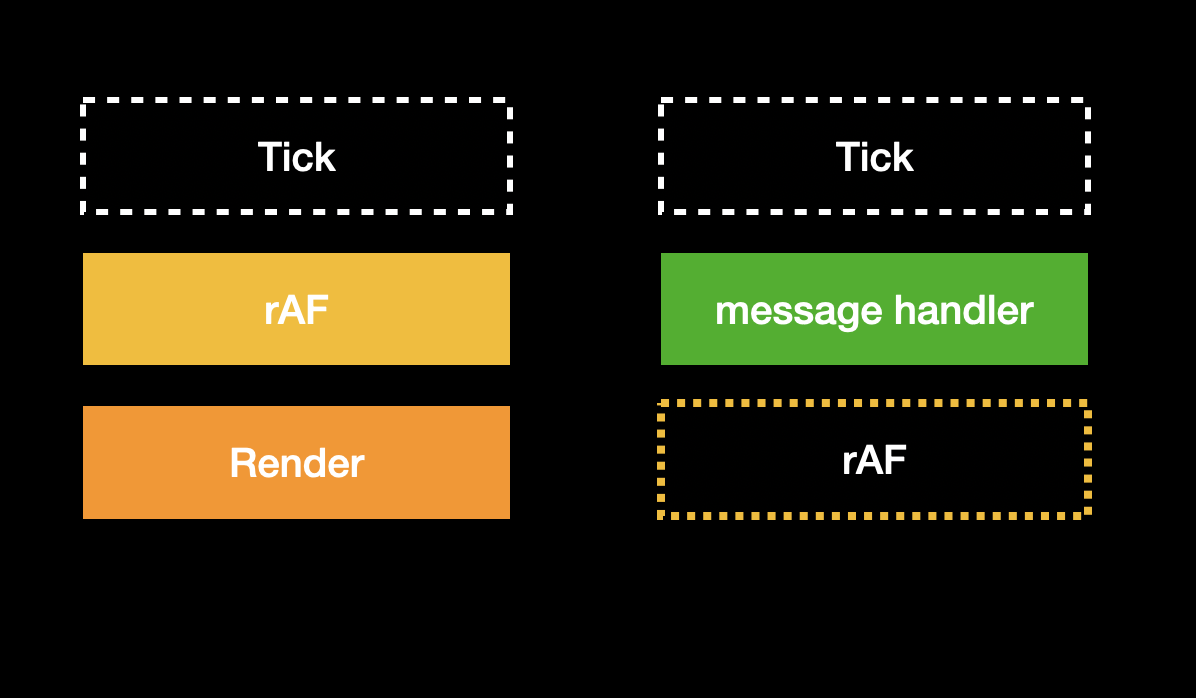
Since the time for the next rAF to be triggered has already been calculated, the message handler can take advantage of this time (which could be around 5ms or longer) to perform tasks, executing small tasks continuously before the time is up.
After execution, rAF will be triggered again, doing the same thing as before, scheduling the callback for the next tick, and then browser render, ending this tick:
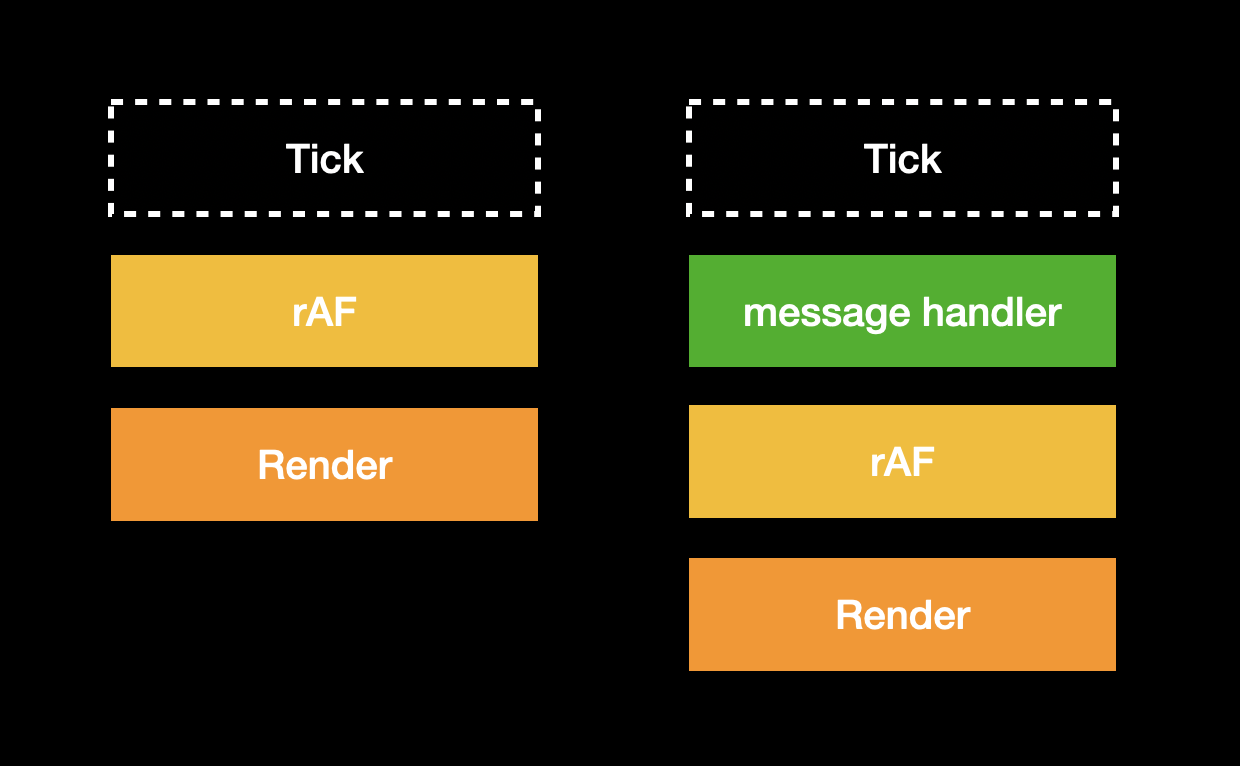
This process continues to execute, which is the entire asynchronous task scheduling mechanism. In simple terms, it is:
- Calculate how much time can be spent executing tasks without interfering with rendering in rAF.
- Execute tasks as much as possible in the message handler.
In the React source code, rAF is referred to as Animation Tick, while the message handler is called Idle Tick.
So why use postMessage and message handler? The reason is that if you use setTimeout(fn, 0), there is a classic 4ms limitation. If you keep using setTimeout to schedule tasks, after a few recursive arrangements, the shortest execution interval will become 4ms, regardless of how much you set the interval.
On the other hand, postMessage and message handler do not have this limitation, which is why this approach was chosen.
However, there is a downside to using the message handler, which is that the current usage is window.addEventListener('message', fn), so every time a task is scheduled, window.postMessage must be used. If there are other listeners on the page, it will be triggered repeatedly.
For example, some extensions might print out all received messages to help with debugging, potentially receiving one every 30ms, which could flood the logs. Such side-effect behavior is clearly not ideal and can interfere with other implementations.
React 16.7.0 - requestAnimationFrame + MessageChannel
Starting from React 16.7.0, this part was changed to use MessageChannel, which is another Web API for message exchange. Its usage is quite similar to the original, just with the added concept of a port:
// DOM and Worker environments.
// We prefer MessageChannel because of the 4ms setTimeout clamping.
const channel = new MessageChannel();
const port = channel.port2;
channel.port1.onmessage = performWorkUntilDeadline;
schedulePerformWorkUntilDeadline = () => {
port.postMessage(null);
};In the comments of the code, you can also see why React does not use setTimeout, which is the same reason I just mentioned. The PR for this change is here: [scheduler] Post to MessageChannel instead of window #14234.
It seems like that’s it? This mechanism is quite reasonable, using two different types of asynchronous tasks to do different things while trying to perform tasks without interfering with rendering.
React 16.12.0 - MessageChannel
However, in React 16.12.0, the mechanism changed again, removing rAF and leaving only MessageChannel, executing for a maximum of 5ms each time:
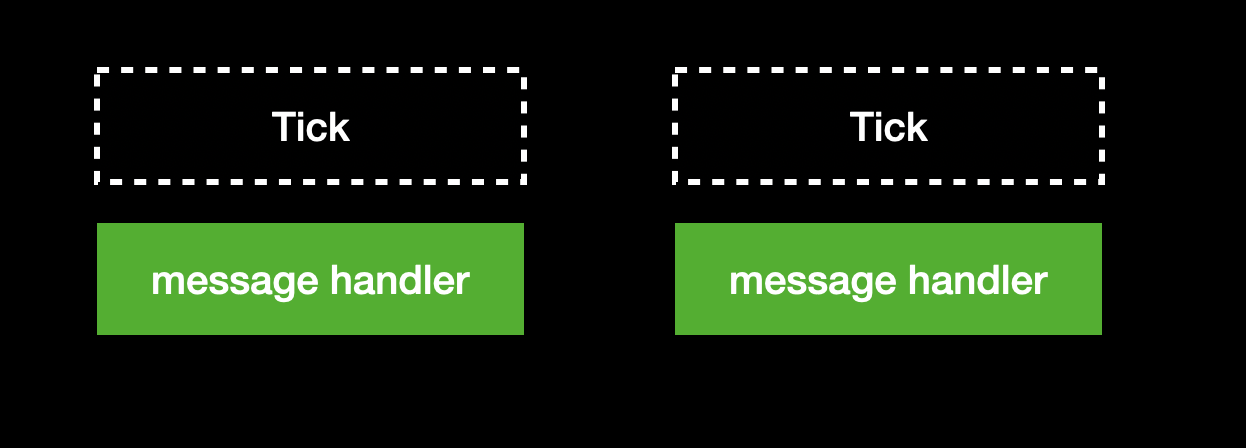
So why switch to this mechanism? There are two places that explain it. The first is the code in 16.12.0:
// Scheduler periodically yields in case there is other work on the main
// thread, like user events. By default, it yields multiple times per frame.
// It does not attempt to align with frame boundaries, since most tasks don't
// need to be frame aligned; for those that do, use requestAnimationFrame.
let yieldInterval = 5;The main idea is that since the task does not need to align with the rendering of the screen, it ignores rendering and just keeps yielding.
The second explanation is from the issue Concurrency / time-slicing by default #21662, where someone asked if the scheduler was still using requestIdleCallback. Dan’s comment was:
No, it fired too late and we’d waste CPU time. It’s really important for our use case that we utilize CPU to full extent rather than only after some idle period. So instead we rewrote to have our own loop that yields every 5ms.
This clarifies why requestIdleCallback was eliminated at the beginning, because it fired too late.
So how is the implementation in the latest version v19.2.0?
From the code, it can be seen that it is basically the same mechanism as above, with not much change. It still uses MessageChannel to schedule tasks and yields every so often.
In the Near Future: Native Scheduler API
In fact, the Scheduler is not just for React; it is used whenever asynchronous task scheduling is needed. Therefore, browsers actually provide a native Scheduler API, but it is still new and not well supported. However, it can be anticipated that in the future, there may be no need to write a custom implementation, as using the native browser API would be the best option.
In fact, React is already using this to implement a set, but it is still in an unstable state: SchedulerPostTask.js. The native API directly supports scheduling tasks with different priorities, which is much more convenient than writing it yourself.
In summary, from React’s code for scheduling asynchronous tasks, we can learn about the differences in timing and frequency of triggering different functions. We can also understand why React made such choices through these changes in mechanisms, allowing us to better grasp the nuances of these asynchronous details.
Learning About Underlying Operations from V8 Bug
Continuing from the earlier discussion about React fiber, there is a section related to the profiler in the code:
if (enableProfilerTimer) {
this.actualDuration = -0;
this.actualStartTime = -1.1;
this.selfBaseDuration = -0;
this.treeBaseDuration = -0;
}The question arises: why is the initial value here -0 instead of 0? What is the difference between these two?
In even older versions, it was first assigned as NaN before becoming 0. What kind of magic is this?
if (enableProfilerTimer) {
this.actualDuration = Number.NaN;
this.actualStartTime = Number.NaN;
this.selfBaseDuration = Number.NaN;
this.treeBaseDuration = Number.NaN;
this.actualDuration = 0;
this.actualStartTime = -1;
this.selfBaseDuration = 0;
this.treeBaseDuration = 0;
}All of this is related to the underlying operations of V8 and a bug.
Regarding this matter, V8 itself has a blog post: The story of a V8 performance cliff in React, which explains it very well. Please read this article yourself or look at it with AI; I won’t repeat it here, and will only mention the conclusions and key points below.
First of all, although we all know that in the JavaScript specification, all numbers are doubles, the JavaScript engine does not necessarily implement it that way. After all, if every number were stored as a 64-bit double, there would be both space and performance issues, and integer addition and subtraction would also be floating-point operations, which is unbearable.
Therefore, in the V8 engine, numbers are actually divided into two types: one is a 32-bit int called a small integer, abbreviated as Smi, and the other is truly a floating-point number, called HeapNumber. The two types are stored in different locations, with floating-point numbers needing to be stored in the heap.
To optimize objects, they are associated with something called a shape when stored, similar to the metadata of the object, which stores the type and offset of each value. Similarly, objects of the same interface will share the same shape.
When the type of an object value changes, this shape will also change. For example, if it changes from Smi to double, a new shape will be created.
The bug in V8 can be simply described as follows: in the React profiler, certain values are initially initialized to 0, with the type being Smi. Then, Object.preventExtensions is used to prevent new properties from being added, and this value is changed to a floating-point number (the return value of performance.now()).
This behavior causes V8 to break, as it does not know how to handle the change in shape, resulting in the creation of an entirely new shape. Moreover, this issue is not limited to just one object; all similar objects cannot share the shape and instead each have their own.
Although most people may not notice this underlying difference, when React is tested with a large number of nodes, the difference becomes apparent as the base increases, evolving into a performance issue.
Although V8 has fixed the bug, so this issue no longer exists, React has also made a fix. For instance, the NaN mentioned earlier is set to NaN because it is fundamentally a floating-point number rather than Smi. The current version being -0 is for the same reason; -0 is a floating-point number, while 0 is Smi.
When both the initial value and the subsequent value are floating-point numbers, there will be no issue with the change in shape, and thus the V8 bug will not be encountered.
However, have you ever thought about how to determine that NaN and -0 are floating-point numbers?
Looking at Underlying Types from V8 Bytecode
Aside from translating specifications, compiling code into V8 bytecode is actually a good method. For example, consider the following function:
function test(x) {
return x === 0;
}
function AAAAA () {
test(0);
test(-0);
test(3);
test(0/0); // NaN
}
AAAAA()
After compiling with the command node --print-bytecode test.js > out, the result is:
[generated bytecode for function: AAAAA (0x31bb2f7de971 <SharedFunctionInfo AAAAA>)]
Bytecode length: 41
Parameter count 1
Register count 2
Frame size 16
Bytecode age: 0
62 S> 0x31bb2f7df776 @ 0 : 17 02 LdaImmutableCurrentContextSlot [2]
0x31bb2f7df778 @ 2 : c4 Star0
0x31bb2f7df779 @ 3 : 0c LdaZero
0x31bb2f7df77a @ 4 : c3 Star1
62 E> 0x31bb2f7df77b @ 5 : 62 fa f9 00 CallUndefinedReceiver1 r0, r1, [0]
73 S> 0x31bb2f7df77f @ 9 : 17 02 LdaImmutableCurrentContextSlot [2]
0x31bb2f7df781 @ 11 : c4 Star0
0x31bb2f7df782 @ 12 : 13 00 LdaConstant [0]
0x31bb2f7df784 @ 14 : c3 Star1
73 E> 0x31bb2f7df785 @ 15 : 62 fa f9 02 CallUndefinedReceiver1 r0, r1, [2]
85 S> 0x31bb2f7df789 @ 19 : 17 02 LdaImmutableCurrentContextSlot [2]
0x31bb2f7df78b @ 21 : c4 Star0
0x31bb2f7df78c @ 22 : 0d 03 LdaSmi [3]
0x31bb2f7df78e @ 24 : c3 Star1
85 E> 0x31bb2f7df78f @ 25 : 62 fa f9 04 CallUndefinedReceiver1 r0, r1, [4]
96 S> 0x31bb2f7df793 @ 29 : 17 02 LdaImmutableCurrentContextSlot [2]
0x31bb2f7df795 @ 31 : c4 Star0
0x31bb2f7df796 @ 32 : 13 01 LdaConstant [1]
0x31bb2f7df798 @ 34 : c3 Star1
96 E> 0x31bb2f7df799 @ 35 : 62 fa f9 06 CallUndefinedReceiver1 r0, r1, [6]
0x31bb2f7df79d @ 39 : 0e LdaUndefined
114 S> 0x31bb2f7df79e @ 40 : a9 Return
Constant pool (size = 2)
0x31bb2f7df711: [FixedArray] in OldSpace
- map: 0x3bc7231c0211 <Map(FIXED_ARRAY_TYPE)>
- length: 2
0: 0x31bb2f7df731 <HeapNumber -0.0>
1: 0x3bc7231c0561 <HeapNumber nan>
Handler Table (size = 0)
Source Position Table (size = 21)
0x31bb2f7df7a1 <ByteArray[21]>You can see that 3 is directly LdaSmi, indicating it is Smi, while -0 and NaN are LdaConstant, loaded from the constant pool, which contains:
Constant pool (size = 2)
0x31bb2f7df711: [FixedArray] in OldSpace
- map: 0x3bc7231c0211 <Map(FIXED_ARRAY_TYPE)>
- length: 2
0: 0x31bb2f7df731 <HeapNumber -0.0>
1: 0x3bc7231c0561 <HeapNumber nan>It is clear that both of these are heap numbers and do not belong to Smi.
From a theoretical perspective, NaN cannot be Smi because NaN is defined in IEEE 754, and -0 requires the negative sign, which does not exist in int, so it can only be a double.
In any case, if you encounter confusion regarding underlying types in the future, you can compile to bytecode for confirmation; it is straightforward.
Summary
In this article, we learned several things from the React source code:
- The purpose of Symbol, which can utilize its non-serializable feature to ensure that it cannot be constructed externally.
- The triggering timing and characteristics of various asynchronous functions such as
requestIdleCallback,requestAnimationFrame,MessageChannel, andsetTimeout, as well as how React arranges tasks at a lower level. - While all JavaScript numbers appear to be 64-bit doubles in specifications, V8 actually differentiates between Smi and double at a lower level, which can be confirmed using bytecode.
Comments