Introduction
Although I’ve heard about React replacing its internal reconciler with something called Fiber for a long time, I’ve never studied it in detail and didn’t know what impact this change would have on higher-level components.
I only began to understand it more deeply when I encountered a related bug while using Redux Form. I learned that since React officially switched to Fiber, there have been some changes to higher-level components.
The title of this article, “A Brief Introduction,” is not a lie. I won’t talk about the underlying operation of Fiber (because I haven’t studied it seriously yet). I will only use plain language to explain what Fiber is, what problems it was created to solve, and its impact on React lifecycles.
A Journey of a Thousand Miles Begins with a Single Bug
Every time I encounter a bug, I take the opportunity to learn from it.
Why? Because it’s a chance to force yourself to learn. If you can’t solve the bug, you can’t move forward. So to solve the bug, you must explore the cause, understand why the problem occurred, and figure out how to solve it.
Of course, you can also find answers directly from Stack Overflow and copy and paste them to cover the problem. But after working for a while, you’ll find that not all problems can be solved that way.
For example, the most difficult cookie problem I encountered a year ago was a great learning opportunity for me.
So what bug did I encounter this time?
Our company’s product uses redux-form, and the problem is this: I have two pages that both use the same component called FormBlock.
I went to page A first, then to page B, and then back to page A. My redux-form validation failed, and no validation was executed when I submitted the form.
At that time, I found several related issues, but I still wanted to find out for myself. So I went to the Redux Form source code and studied it for a few hours until I finally found the problem.
When redux-form performs validation, it first checks whether the fields have been registered. If they haven’t been registered, it returns true without performing any validation. After adding a few console.log statements, I found that the problem was here, and the field was not registered.
Then I looked for where the registration was done and found that in componentWillMount, an action was dispatched to register all the form fields (REGISTER_FIELD).
Then in componentWillUnmount, redux-form dispatches an action called DESTROY (related code) to clear all registered fields.
So far, everything seems reasonable. When I leave page B, componentWillUnmount of FormBlock is triggered, unregistering all fields. When I enter page A, componentWillMount of FormBlock is triggered, re-registering all fields.
But if you open redux-devtool, you’ll find that the order is not quite what you expected:
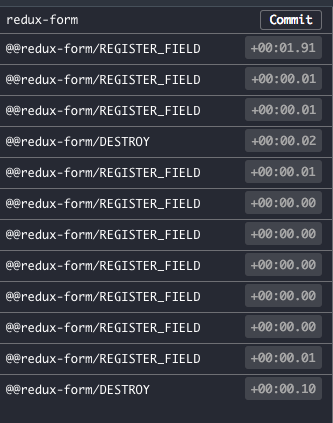
Huh? Why is it registering first and then deleting? And because it was deleted, the validation failed, and no validation logic was executed.
After looking for related information, I found this Browser back button not working with [email protected] and [email protected] issue and the response from gaearon, a developer of Redux and React, below:
In React 15, if A is replaced by B, we unmount A, and then create and mount B:
- A.componentWillUnmount
- B.constructor
- B.componentWillMount
- B.componentDidMount
In Fiber, we create B first, and only later unmount A and mount B:
- B.constructor
- B.componentWillMount
- A.componentWillUnmount
- B.componentDidMount
After React 16, due to this change in order, the execution order of the redux-form lifecycle mentioned above is different from what was expected, which indirectly caused the bug mentioned at the beginning.
At this point, the reason for the problem has been traced from redux-form itself to React, and then to Fiber in more detail. It seems that we can no longer avoid Fiber.
First, let me provide some other reference materials related to redux-form and the execution order, and then let’s take a closer look at Fiber.
- Re-mounting a Field component erases the field-level validation function
- Ordering of componentWillMount/Unmount in React 16
- Asynchronous ComponentWillUnmount in React 16
What is Fiber?
The fastest way to understand a new thing is to answer the following questions:
- What problem is it designed to solve?
- What is the solution?
By understanding these two questions, you can have a preliminary idea of the new thing. Although you still don’t know the implementation details, at least you know what impact and changes it brings.
Let’s first take a look at a problem that has always existed in React.
Suppose you have a super-functional app with a lot of components, and you change the state of the top-level component (let’s say it’s
<App />).Because the state has changed, the render function of
<App />will be executed, and then the render function of the components underAppwill be executed, and so on until the bottom is reached.If you look at the call stack, you will find that the call stack is huge:
(Image source: React Fiber現状確認)
What problems does this cause? Because there are too many things to do, and this process cannot be interrupted, it will cause the main thread to be blocked, and anything you do during this time will not be responsive in the browser.
In short, the problem with React’s performance is that the main thread is blocked because there are too many things to do.
At this point, we have answered the first question. Fiber is a solution designed to solve this problem. Next, let’s answer the second question: what is the solution?
Since the cause of the problem is “too many things to do and cannot be interrupted”, we just need to invent an “interruptible” mechanism! Instead of updating all at once, we can update incrementally (incremental rendering), which can solve this problem!
If we can cut the work to be updated into small pieces and execute only one small piece at a time, then the main thread will not be blocked because there can be gaps between each small piece of work to do other things (respond to user clicks, draw new screens, etc.).
Just like the cartoon below, we complete a little bit of work each time, instead of completing everything at once:


(Picture source: Lin Clark - A Cartoon Intro to Fiber - React Conf 2017)
Now that you know what Fiber is, this is Fiber. Each small task is called a Fiber, and Fiber means “fiber” in English, so some people call this mechanism “Fiber”.
Or to put it another way, the original problem was that the render function was executed layer by layer through the call stack in the program, and each time a function was called, a new task was thrown into the stack frame. However, this mechanism would cause tasks to be unable to be interrupted.
So Fiber implemented a virtual stack frame, which is simply to simulate the feeling of a call stack using JavaScript, but the advantage is that you have complete control, rather than being bound by the JavaScript runtime mechanism.
To summarize, before Fiber, updates were “one-time” updates that could not be interrupted, causing the main thread to be blocked during this period.
With the Fiber mechanism, we divide a large update into many small updates, updating only a little bit each time, so that the main thread can do other things during the update gap without being bound.
It sounds very good, and the problem is solved, but what are the side effects?
Changes brought by Fiber
After replacing the core with Fiber, there are some costs to be paid. The work in Fiber is actually divided into two stages:
- render/reconciliation
- commit
Simply put, the first stage is to find the parts that need to be changed, and the second stage is to actually apply these changes to the DOM. The first stage can be interrupted and can be re-executed, while the second stage is the same as before and must be done in one go.
And these two stages correspond to different life cycles:
First stage
- componentWillMount
- componentWillReceiveProps
- shouldComponentUpdate
- componentWillUpdate
Second stage
- componentDidMount
- componentDidUpdate
- componentWillUnmount
Because the first stage can be interrupted and re-executed, the functions in this stage may be called many times.

(Picture source: Lin Clark - A Cartoon Intro to Fiber - React Conf 2017)
So, if you used to call the API to get data in componentWillMount, for example, you would call the API more than once, wasting some bandwidth. If you want to change it, you need to move this code to componentDidMount, which will ensure that it is only called once.
In short, since the internal mechanism was changed to Fiber (starting from React 16, so if you are using version 16 or above, it is already Fiber), the number and method of calling React’s lifecycle functions will be different from before.
In addition, there is the difference in the order I mentioned at the beginning, which is also a noteworthy part. Although it doesn’t seem like a big problem, if you don’t know this, you may encounter some inexplicable bugs.
The future of React
React 16.3 was officially released yesterday, accompanied by the official context API and lifecycle changes.
With the official launch of Fiber, we can expect more exciting new features in the future. For example, time slicing mentioned in Sneak Peek: Beyond React 16, which makes the entire app experience smoother.
And Update on Async Rendering also mentions progress on asynchronous rendering.
Since the internal mechanism was changed to Fiber, async rendering has been able to achieve maximum performance.
However, there are some costs to pay for async rendering. The original lifecycle API may have some problems in this scenario. The official website has given many common examples, including the problem that componentWillMount will be called multiple times:
(Ignoring the original sample code, but the idea is to call the API in componentWillMount)
The above code is problematic for both server rendering (where the external data won’t be used) and the upcoming async rendering mode (where the request might be initiated multiple times).
The recommended upgrade path for most use cases is to move data-fetching into componentDidMount.
For async rendering, the following three lifecycles will cause problems:
- componentWillMount
- componentWillReceiveProps
- componentWillUpdate
These three lifecycles will be removed in React 17 (if you still want to use them, you can add UNSAFE_, for example, change to UNSAFE_componentWillMount to use them), but since they are marked as UNSAFE, there is no reason to continue using them.
In the latest release of 16.3, two new lifecycles were introduced to solve the above problems:
- getDerivedStateFromProps
- getSnapshotBeforeUpdate
The first one is obviously to replace componentWillReceiveProps, and the second one is to replace componentWillUpdate. In fact, in some scenarios, componentDidUpdate can also replace the original two lifecycles.
As for the componentWillMount mentioned earlier, it is recommended to move the code inside to componentDidMount.
Next, let’s quickly see how the new lifecycles replace the old ones. Here, I will directly use the official example. This example detects props to determine whether to change the state, which is a common application scenario:
// Before
class ExampleComponent extends React.Component {
state = {
isScrollingDown: false,
};
componentWillReceiveProps(nextProps) {
if (this.props.currentRow !== nextProps.currentRow) {
this.setState({
isScrollingDown:
nextProps.currentRow > this.props.currentRow,
});
}
}
}The new lifecycle static getDerivedStateFromProps will be called when the component is created and receives new props, but only new props and old state will be passed in. Therefore, we can make the following changes:
// After
class ExampleComponent extends React.Component {
// 初始化 state
state = {
isScrollingDown: false,
lastRow: null,
};
static getDerivedStateFromProps(nextProps, prevState) {
// 把新的 props 跟舊的 state 做比較
if (nextProps.currentRow !== prevState.lastRow) {
// 回傳新的 state
return {
isScrollingDown: nextProps.currentRow > prevState.lastRow,
lastRow: nextProps.currentRow, // 同步一下 state
};
}
// return null 代表不用改變 state
return null;
}
}In fact, it just means that you save the prevProps passed by componentWillReceiveProps to the state and compare it with the state.
You may be very puzzled when you see this: “Why doesn’t getDerivedStateFromProps just pass in prevProps?”
The reason given by the React official website is twofold:
- Because
getDerivedStateFromPropsis also called during initialization, the firstprevPropswill be null, which means you have to do a null check every time, which is not good. - Not passing
prevPropsmeans that React does not need to rememberprevPropsfor you, which is helpful for future memory optimization.
In short, there will be no componentWillReceiveProps to use in the future. You need to save the required prevProps in the state and compare them in getDerivedStateFromProps.
Looking at another example, the purpose of this example is to maintain the position of the scroll bar when adding a new item, so the old height must be saved before the update, and the position of the scroll bar must be adjusted after the update:
class ScrollingList extends React.Component {
listRef = null;
previousScrollHeight = null;
componentWillUpdate(nextProps, nextState) {
// 有新增 item 的話,記住現在的高度
if (this.props.list.length < nextProps.list.length) {
this.previousScrollHeight = this.listRef.scrollHeight;
}
}
componentDidUpdate(prevProps, prevState) {
// 如果 previousScrollHeight 不是 null,代表有新增 item
// 調整捲軸位置
if (this.previousScrollHeight !== null) {
this.listRef.scrollTop += this.listRef.scrollHeight - this.previousScrollHeight;
this.previousScrollHeight = null;
}
}
render() {
return (
<div ref={this.setListRef}>
{/* ...contents... */}
</div>
);
}
setListRef = ref => {
this.listRef = ref;
};
}What is the problem with this? Do you remember that we mentioned earlier that Fiber has two stages? Render and commit. There is a time difference between these two stages, and componentWillUpdate belongs to the first stage, and componentDidUpdate belongs to the second stage.
If the user does something between these two stages, such as adjusting the size of the window, then the height you saved will not be correct, but the old value will be obtained.
The solution is to use the new lifecycle getSnapshotBeforeUpdate, which will be called before the DOM is updated, which can ensure that you get the latest information.
class ScrollingList extends React.Component {
listRef = null;
getSnapshotBeforeUpdate(prevProps, prevState) {
// 如果 list 有變動,就回傳現在的捲軸高度
// 這個回傳值會被當作 componentDidUpdate 的第三個參數
if (prevProps.list.length < this.props.list.length) {
return this.listRef.scrollHeight;
}
return null;
}
componentDidUpdate(prevProps, prevState, snapshot) {
// snapshot 就是上面回傳的那個值
// 如果不是 null,就利用 snapshot 來調整捲軸高度
if (snapshot !== null) {
this.listRef.scrollTop +=
this.listRef.scrollHeight - snapshot;
}
}
render() {
return (
<div ref={this.setListRef}>
{/* ...contents... */}
</div>
);
}
setListRef = ref => {
this.listRef = ref;
};
}In short, by combining the use of the commit phase lifecycle (componentDidMount, componentDidUpdate, componentWillUnmount) with the newly introduced getDerivedStateFromProps and getSnapshotBeforeUpdate, the old lifecycles that may cause problems can be replaced.
If you want to see more examples, this article is worth referring to: Update on Async Rendering.
Conclusion
Performance has always been a focus of Web Apps, and the principle to grasp is simple: do not block the main thread. As long as the main thread can work, it can handle other things, such as responding to user clicks or drawing new screens.
However, React’s original mechanism caused problems, so the internal core was rewritten using Fiber, which cuts a large, uninterrupted task into many small, interruptible tasks. This also makes parallelization possible in the future, and the rendering speed may be faster.
But because of this change in mechanism, it affects the original lifecycle, and a small mistake can cause problems. The official also released two new lifecycles to solve this problem.
As a long-term user of React, although I find it annoying to change the code due to such major changes, in the long run, it is actually beneficial because there are more things that can be done, and performance will continue to improve.
This article summarizes some of my recent insights into Fiber and the latest changes in React. I don’t dare to talk about the implementation mechanism of Fiber because I don’t understand it very well. I just hope to use plain language to help everyone understand what this mechanism looks like.
If there is anything wrong, please correct me. Thank you.
References:
Comments