Although Same Site and Same Origin may seem similar, they are actually quite different. This difference affects how the browser perceives the relationship between these two websites and the permissions it grants.
This article will cover the following topics:
- What is Origin? What makes it Same Origin?
- What is Site? What makes it Same Site?
- What is the difference between Same Origin and Same Site?
- How to turn Same Site into Same Origin?
Without further ado, let’s get started!
(Before we begin, let’s answer a question. Yes, the title was inspired by the ninja Hattori.)
2022-01-20: Modified the “Examining Same Site” section to supplement the history of the scheme. Thanks to @littlegoodjack.
Exploring Origin and Site
Let’s start with a simple and easy-to-understand explanation, which is somewhat inaccurate, but we’ll correct it one by one later.
Origin is the combination of scheme, port, and host. Therefore, the origin of a URL https://huli.tw/abc is:
- scheme: https
- port: 443 (the default port for https)
- host: huli.tw
Thus, its origin is https://huli.tw. As you can see, the path /abc does not affect the origin, and the port part is already implied as 443 for https.
Same Origin means that the origins of two URLs must be the same. For example:
https://huli.tw/abcandhttps://huli.tw/hello/yoare Same Origin because their scheme, port, and host are the same, and the path does not affect the result.https://huli.twandhttp://huli.tware not Same Origin because their schemes are different.http://huli.twandhttp://huli.tw:8080are not Same Origin because their ports are different.https://huli.twandhttps://blog.huli.tware not Same Origin because their hosts are different.
As you can see from the above examples, the conditions for Same Origin are quite strict. Basically, except for the path, everything else must be the same to be called Same Origin.
Next, let’s take a look at Site. Site looks at fewer things than Origin, only scheme and host, so it doesn’t look at port. The definition of two URLs being Same Site is also more relaxed. The host part does not have to be exactly the same, as long as it is a subdomain, it is also considered Same Site.
For example:
https://huli.tw/abcandhttps://huli.tw/hello/yoare Same Site because their scheme and host are the same.https://huli.twandhttp://huli.tware not Same Site because their schemes are different.http://huli.twandhttp://huli.tw:8080are Same Site because the port does not affect the result.https://huli.twandhttps://blog.huli.tware Same Site because huli.tw and blog.huli.tw are both under the same domain huli.tw.https://abc.huli.twandhttps://blog.huli.tware also Same Site because abc.huli.tw and blog.huli.tw are both under the same domain huli.tw.
Compared to Same Origin, Same Site is obviously more relaxed. Even if the ports are different, it is still Same Site, and as long as the host belongs to the same parent domain, it is basically Same Site.
However, as I mentioned at the beginning, although the above definitions are correct in most cases, they are not precise. Let’s take a look at the spec to see what exceptions there are.
Examining Same Origin
In the article CORS Complete Guide (Part 1): Why CORS Errors Occur?, I mentioned the definition of Origin. In the 7.5 Origin section of the HTML specification, you can see the complete definition. Let’s first take a look at the explanation of Origin in the specification:
Origins are the fundamental currency of the web’s security model. Two actors in the web platform that share an origin are assumed to trust each other and to have the same authority. Actors with differing origins are considered potentially hostile versus each other, and are isolated from each other to varying degrees.
This passage explains that if two websites share the same origin, they trust each other and have the same authority. If they have different origins, they are considered potentially hostile and are isolated from each other to varying degrees.
The specification divides origins into two types: “An opaque origin” and “A tuple origin”. Opaque origins are special cases that occur in certain situations, such as when a web page is opened locally and the URL is “file:///…”. In this case, the origin is an opaque origin, which is “null”.
Tuple origins are more common and are of greater concern. The document states that a tuple contains:
- Scheme (an ASCII string).
- Host (a host).
- Port (null or a 16-bit unsigned integer).
- Domain (null or a domain). Null unless stated otherwise.
You may wonder why there is both a host and a domain. We will discuss this later.
The specification also includes an algorithm for determining whether two origins, A and B, are the same origin:
- If A and B are the same opaque origin, then return true.
- If A and B are both tuple origins and their schemes, hosts, and port are identical, then return true.
- Return false.
Either the two are the same opaque origin, or their schemes, hosts, and ports are all the same to be the same origin. In addition to the same origin, you will also see the term “same origin-domain” in the spec, which we will discuss later.
As I mentioned earlier, the same origin is a strict restriction. For example, for the URL “https://huli.tw/api“, because the origin does not include the path, its origin will be “https://huli.tw“. This means that the URLs of websites that share the same origin must all be “https://huli.tw/*” to be considered the same origin.
Although “https://huli.tw“ and “https://blog.huli.tw“ are only related to domain and subdomain, they are not the same origin because the hosts are different.
Remember this, it is important.
The definition of origin and same origin explored here, as well as the “inaccurate statement” mentioned at the beginning, differ in that there is an opaque origin and same origin-domain, and the origin tuple includes a “domain” that we did not use.
Finally, one more thing to note is that when I say “‘https://huli.tw/api‘ has an origin of ‘https://huli.tw‘“, a more accurate statement is: “‘https://huli.tw/api‘ serialized its origin as ‘https://huli.tw‘“.
This is because the origin is actually a tuple, which is represented as follows: “(https, huli.tw, null, null)”. The tuple becomes a string, which is “https://huli.tw“. When the information represented by both the tuple and the serialized string is similar, I prefer to use the latter method.
Examining SameSite
The definition of site is also in the same spec, which states:
A site is an opaque origin or a scheme-and-host.
Therefore, a site can be an opaque origin or a scheme-and-host.
In the spec, we can find another term called “schemelessly same site” in addition to same site, and the difference between the two is also very clear. Same site considers the scheme, while schemelessly same site does not.
Therefore, the algorithm for determining whether two origins A and B are same site is as follows:
Two origins, A and B, are said to be same site if both of the following statements are true:
- A and B are schemelessly same site
- A and B are either both opaque origins, or both tuple origins with the same scheme
If A and B are same site, either they are both opaque origins, or both have the same scheme and are schemelessly same site.
So same site considers the scheme, and two URLs with different schemes like http and https will never be same site, but they may be schemelessly same site.
There is actually a small historical context here. When same site was first introduced, it did not consider the scheme, and it was not until later that the scheme was included in the consideration.
In this 2016 RFC: Same-site Cookies, you can see that the judgment of same site did not include the scheme, so at that time, https://huli.tw and http://huli.tw were same site.
It wasn’t until June 2019 that the discussion began on whether to include the scheme in the consideration. For more details, please refer to: Treat http://foo.com -> https://foo.com requests as Sec-Fetch-Site: cross-site. #34.
At that time, the spec for same site was not defined in the HTML spec we see today, but in another URL spec, so the discussion was moved there: Consider introducing a “same-site” concept that includes scheme. #448, and then in September 2019, this PR was created: Tighten ‘same site’ checks to include ‘scheme’. #449, which officially included the scheme in the consideration in the specification, defining same site as “considering the scheme”, while a new term was introduced for not considering the scheme: schemelessly same site.
Then, two months later, the relevant spec was moved from URL to HTML. Please refer to these two PRs: Let HTML handle the “same site” definition #457, Define (schemelessly) same site for origins #5076.
Spec is spec, and sometimes specification revisions do not mean that browsers will immediately follow suit. So what is the current implementation of browsers?
In November 2020, Chrome wrote an article: Schemeful Same-Site, which seems to still consider different schemes as same site at that time, but from Chrome platform status: Feature: Schemeful same-site, we can see that Chrome has included the scheme in the consideration since version 89.
As for Firefox, from the status of this issue: [meta] Enable cookie sameSite schemeful, it seems that it has not yet considered this behavior as the default value, and if there is no special setting adjustment, different schemes will also be considered as same site.
After reviewing the history, let’s take a look at how the most important schemelessly same site is determined:

We won’t discuss the opaque part for now. The key point above is obviously a new term: “registrable domain,” which is used to compare two hosts when determining if they are the same site.
The definition of this registrable domain is in another URL spec:
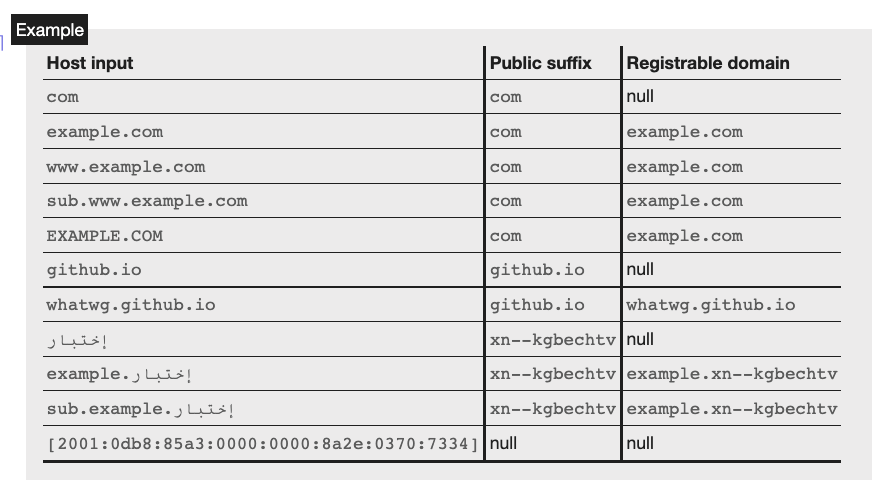
A host’s registrable domain is a domain formed by the most specific public suffix, along with the domain label immediately preceding it, if any.
Here, another new term is mentioned: “public suffix,” which we discussed in the DoS attack using Cookie features: Cookie Bomb post.
An example will make it easier to understand. The registrable domain of blog.huli.tw is huli.tw, and the registrable domain of huli.tw is also huli.tw.
However, the registrable domain of bob.github.io is not github.io, but bob.github.io.
Why is that? I’ll explain briefly below.
If there were no concepts of “registrable domain” and “public suffix,” then the definition of same site would be what we mentioned earlier: huli.tw and blog.huli.tw are the same site, which is not a problem.
But if that were the case, bob.github.io and alice.github.io would also be the same site.
Wait, isn’t that bad?
Yes, because github.io is a service of GitHub pages, and every GitHub user has their own subdomain to use. But GitHub doesn’t want bob.github.io to interfere with alice.github.io because they are actually two completely independent websites, unlike huli.tw and blog.huli.tw, which are both owned by me.
Therefore, the concept of public suffix was introduced, which is a manually maintained list of “lists that do not want to be treated as the same website.” I’ll give a few examples:
- github.io
- com.tw
- s3.amazonaws.com
- azurestaticapps.net
- herokuapp.com
So after the browser refers to this list, it will recognize that bob.github.io and alice.github.io are not related and are not the same site. This also has a proprietary term called eTLD, which can be found in detail in How to determine if two domains have the same owner?
As mentioned above, because github.io is in the public suffix list, the registrable domain of bob.github.io is bob.github.io, while the registrable domain of alice.github.io is alice.github.io.
So, the definition of same site we mentioned at the beginning is not correct. Two hosts that appear to belong to the same parent domain do not necessarily mean they are the same site. It also depends on whether they are in the public suffix list.
blog.huli.tw, huli.tw, and test.huli.tw are all the same site because their registrable domains are all huli.tw.
The spec also includes a clearer table, which you can take a closer look at:
Finally, let’s summarize same site:
- There are same site and schemelessly same site, and the former is more commonly used.
- To determine if two hosts are same site, you need to look at the registrable domain.
- To decide what the registrable domain is, you need to look at the public suffix list.
- Even if two hosts appear to belong to the same parent domain, they may not be same site due to the existence of public suffix.
- Same site does not consider port, so
http://blog.huli.tw:8888andhttp://huli.tware same site.
Same origin and same site
Same origin looks at:
- Scheme
- Port
- Host
While same site looks at:
- Scheme
- Host (registrable domain)
If two websites are same origin, then they must be same site because the criteria for judging same origin is stricter.
The biggest difference between the two is:
- Same origin looks at port, while same site does not.
- Same origin looks at host, while same site looks at registrable domain.
Here are some examples:
| A | B | Same origin | Same site | Description |
|---|---|---|---|---|
| http://huli.tw:8080 | http://huli.tw | X | O | Same site does not consider port |
| https://blog.huli.tw | https://huli.tw | X | O | Same registrable domain |
| https://alice.github.io | https://github.io | X | X | github.io is in the public suffix |
| https://a.alice.github.io | https://b.alice.github.io | X | O | Same registrable domain |
| https://bob.github.io/page1 | https://bob.github.io/about | O | O | Regardless of path |
The magical document.domain
After discussing same origin and same site, we finally come to the topic we wanted to talk about at the beginning, which is the “domain” attribute mentioned in the origin spec. There is even a “same origin-domain” thing in the origin spec. In fact, there is a green note in the origin spec that directly breaks the topic:

It says that except for the domain attribute, everything else in the origin is immutable, and this attribute can be changed through document.domain. There is a section in the spec called 7.5.2 Relaxing the same-origin restriction, which talks about this. Here is an excerpt:
(document.domain) can be set to a value that removes subdomains, to change the origin’s domain to allow pages on other subdomains of the same domain (if they do the same thing) to access each other. This enables pages on different hosts of a domain to synchronously access each other’s DOMs.
For the convenience of understanding, let’s start with a demo.
I modified the contents of /etc/hosts on my local machine as follows:
127.0.0.1 alice.example.com
127.0.0.1 bob.example.comIn this way, both of these URLs will connect to the local server. Then I started a simple HTTP server and wrote a simple HTML to run on localhost:5555.
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8" />
<meta name="viewport" content ="width=device-width, initial-scale=1" />
</head>
<body>
<h1></h1>
<h2></h2>
<button onclick="load('alice')">load alice iframe</button>
<button onclick="load('bob')">load bob iframe</button>
<button onclick="access()">access iframe content</button>
<button onclick="update()">update domain</button>
<br>
<br>
</body>
<script>
const name = document.domain.replace('.example.com', '')
document.querySelector('h1').innerText = name
document.querySelector('h2').innerText = Math.random()
function load(name) {
const iframe = document.createElement('iframe')
iframe.src = 'http://' + name + '.example.com:5555'
document.body.appendChild(iframe)
}
function access() {
const win = document.querySelector('iframe').contentWindow
alert('secret:' + win.document.querySelector('h2').innerText)
}
function update() {
document.domain = 'example.com'
}
</script>
</html>There are three functions on the page:
- Load iframe
- Read data from the iframe’s DOM
- Change document.domain
First, we open http://alice.example.com:5555, then load the iframe from http://bob.example.com:5555, and then click “access iframe content” on the alice page:
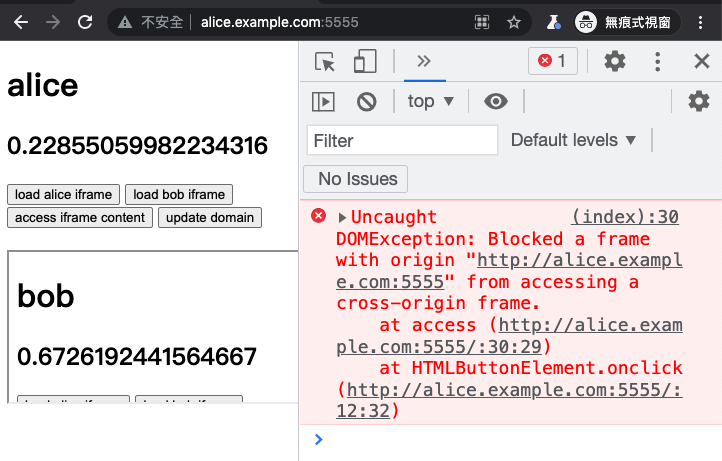
You will see an error message in the console that says:
Uncaught DOMException: Blocked a frame with origin “http://alice.example.com:5555“ from accessing a cross-origin frame.
Because although alice and bob are same site, they are not same origin. If an iframe wants to access the content of the DOM, it must be same origin.
Then we both click “update domain” on the alice and bob pages, and then click “access iframe content” again:
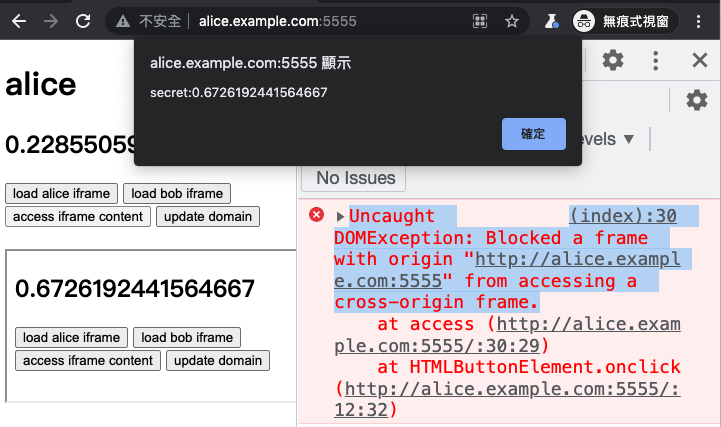
This time, you will see that we also obtained the data from the bob page, and successfully changed http://alice.example.com:5555 and http://bob.example.com:5555 from cross origin to same origin. This is the art of patience, turning same site into same origin!
This trick is not available for any two web pages. Basically, only same site websites can use it, and there are many checks when setting it up:

Taking github.io as an example, if alice.github.io executes document.domain = 'github.io', an error will be thrown in the console:
Uncaught DOMException: Failed to set the ‘domain’ property on ‘Document’: ‘github.io’ is a top-level domain.
Why do the two pages become same origin after changing document.domain? Strictly speaking, it is not same origin, but same origin-domain. In the docuemnt related spec, it is written that some checks are based on same origin-domain, not same origin.
So how do we determine if two origins are same origin-domain? Let’s take a look at how the spec says:
- If A and B are the same opaque origin, then return true.
- If A and B are both tuple origins, run these substeps:
- If A and B’s schemes are identical, and their domains are identical and non-null, then return true.
- Otherwise, if A and B are same origin and their domains are identical and null, then return true.
- Return false.
If the schemes of A and B are the same, and their domain properties are the same and not null, return true. Otherwise, if A and B are same origin and their domains are identical and null, return true.
Here are some interesting points:
- Both web pages must either not have a domain set or have the same domain set in order to return true (this is important).
- If a domain is set, the same origin-domain no longer checks the port.
document.domain is used to change the domain attribute in the origin tuple.
In the example above, both web pages http://alice.example.com:5555 and http://bob.example.com:5555 changed their domain to example.com, so they have the same origin-domain.
Let’s take a look at three interesting cases below.
Case 1: One-sided change
If https://alice.example.com executes document.domain = 'example.com' and then embeds https://example.com in an iframe, they are still not the same origin-domain because the alice page has a domain attribute, but the example.com page does not.
example.com must also execute document.domain = 'example.com' for both to be the same origin-domain.
Case 2: Disappearing port
http://alice.example.com:1234 and http://alice.example.com:4567 are cross-origin because the ports are different, but if both pages execute document.domain = 'alice.example.com', they become the same origin-domain and can access each other’s DOM because it does not look at the port.
Case 3: I am not who I used to be
Suppose http://alice.example.com embeds itself in an iframe. The iframe and the original page are obviously the same origin and can access each other’s DOM.
However, if I execute document.domain = 'alice.example.com' on the page, the page will be set with a domain attribute, and the page in the iframe will not have a domain attribute, so they will no longer be the same origin-domain.
The fade-out and exit of document.domain
Using this trick to relax the same-origin restriction should have been available for a long time, and it has not been removed until now to be compatible with early behavior. I guess many web pages used this trick in the early days to access same-site but cross-origin pages.
But this approach is obviously risky. For example, if a subdomain has an XSS vulnerability, there is a chance to use this method to expand the scope of influence. In an article written by @fin1te in 2016, An XSS on Facebook via PNGs & Wonky Content Types, this technique was used to successfully perform XSS from a subdomain to www.facebook.com, increasing the impact of the vulnerability.
Also, due to security issues, Chrome published an article on January 11, 2022, in which it announced that it will disable modifying document.domain to relax the same-origin policy: Chrome will disable modifying document.domain to relax the same-origin policy. The article explains that starting from Chrome 101, the support for changing document.domain will be stopped.
The original behavior can be replaced by postMessage or Channel Messaging API, but it requires writing more code, as it is not as convenient as directly manipulating the DOM.
If a web page wants to continue using the document.domain modification feature, it needs to include Origin-Agent-Cluster: ?0 in the response header to continue using it.
The article also includes a related discussion thread about this change: Deprecating document.domain setter. #564.
Conclusion
I seem to have learned this trick two or three years ago, knowing that by changing document.domain, two websites can be changed from cross origin to same origin. However, I have never seen anyone use it in practice.
The reason why I wanted to write this article is because I saw the article attached at the end a few days ago and learned that this trick will be disabled by default in Chrome in the near future. Although the starting point was just to write about this behavior, I also paid attention to some blind spots that I had not noticed before in the process of looking at the origin and site definitions and reading the spec, such as same site checking public suffix.
There are actually more details to talk about regarding origin, such as what is an opaque origin? But on the one hand, if I keep talking, it will be too long, and on the other hand, I haven’t studied it carefully yet. I will leave some reference materials and fill this gap in the future if I have the opportunity:
Finally, I hope this article has helped everyone understand what same origin and same site are, as well as more detailed same origin-domain and schemelessly same site.
Reference:
Comments