此文章是我在 Modern Web 2021 的分享:《接觸資安才發現前端的水真深》的文字版,當時的演講影片尚未釋出,想看簡報的話在這邊:slides
我自己覺得影片加上簡報的效果應該會比文字好,但想說用文字留一份紀錄也不錯,因此還是寫了這篇文章,內容會有些許與影片不同,有點像是再重新寫了一遍。
原來我不懂前端
這個標題是我接觸到資安的世界以後,最真實的想法。
身為一個前端工程師,自認為對前端頗為熟悉,無論是原生的 JavaScript 還是一些框架或函式庫,多少都用過或者聽過,連看到許多奇形怪狀的 JavaScript 題目也不會感到太過驚訝,覺得已經沒什麼能讓我「哇!」這樣的驚嘆。
直到我接觸了資安相關的東西,才知道是我太天真。

前端工程師所接觸的前端,跟資安工程師所看到的前端是兩個不同的面向。資安的重點在於各式各樣的攻擊手法,要想辦法繞過既有的限制,找到一條新的道路。但是前端工程師根本不需要知道那些東西,因為他是在沒有限制的狀況下來寫 code 的。
這陣子有玩了一些 CTF,對於前端也從另一個角度看了一陣子,學到很多新的前端知識,換句話說,我在一個新的領域(資安)重新學習到了我原本熟悉的領域(前端)的知識,這種感覺十分特別,因此這篇文章想跟大家分享我學到的一些東西,希望能讓大家感受到我當初的驚訝。
此文章分成三個主題:
- 繞過各種限制
- XS leaks
- 其他你可能不知道的功能
繞過各種限制
談到前端安全,第一個想到的想必是 XSS,有關 XSS 的文章跟介紹之前寫過不少了,有興趣的話可以參考:XSS 從頭談起:歷史與由來,這邊就不再贅述。
一個最簡單直覺的 XSS payload 會長這樣:
<script>alert(1)</script>但這種形式的 XSS 不夠有趣,而且很容易被防禦住,所以我們先暫時不講這個,來看一些比較有趣的,例如說這個:
<img src=non_exist onerror=alert(1)>這一段 HTML 利用 event handler 的方式去執行 JavaScript,我們載入一張不存在的圖片,就會觸發 onerror 事件,執行到裡面的程式碼。還有一點值得注意的是,其實屬性不需要加 "" 也可以。
還可以再更進一步,變成這樣:
<svg onload=alert(1)>這次連 src 都不需要了,直接用 <svg> 搭配 onload 事件去執行程式碼。
假設小明是一位後端工程師,責任是去過濾這些輸入的字串,讓它不要產生 XSS 漏洞,除了過濾 <script> 以外,小明也過濾了空格。理由很簡單,像是這種用屬性來執行的 XSS,屬性跟標籤之間一定要有空格對吧?那一旦把空格濾掉,不就沒辦法利用屬性來做 XSS 了嗎?
天真的小明踢到了鐵板,因為其實可以這樣:
<svg/onload=alert(1)>
<svg onload=alert(1)>
<svg
onload=alert(1)>除了空格以外,/、tab 還有換行都是合法的分隔符號,所以如果只取代空格的話是沒有用的。
小明知道這個規則以後,察覺到根本問題其實不是空格,而是 onxxx 這種以 on 開頭的 event handler,於是他把 on 開頭的屬性全都過濾掉了,心想:「只要沒辦法用 event handler,就沒辦法 XSS 吧?」
聽起來十分合理,但他不知道的是,就算沒有 event handler 也可以:
<iframe/src="javascript:alert(1)">javascript: 開頭的字串稱為 JavaScript pseudo protocol,在一些地方可以用來執行程式碼,之前我們在《在做跳轉功能時應該注意的問題:Open Redirect》中就有提過這個特性。
小明的防禦再度破功,只好再次加強,把 javascript 這個看起來很危險的字串取代掉,這樣應該就沒事了吧?
殊不知,原來在 javascript 這幾個字中間塞入 tab 以後,居然還是有效:
<iframe/src="javas cript:alert(1)">小明修正了程式碼,把那些有的沒的像是空白、空行或是 tab 全都取代成空字串,然後再檢查一次有沒有 javascript,有的話就過濾掉,如此一來,上面的 payload 就無法運作了。
但小明忘記網頁上的資訊是可以編碼的,例如說你想在畫面上呈現 <h1>,你要編碼成 <h1>,這樣畫面呈現的是你要的東西,而不是被當作 h1 標籤來解析。除了那些特殊符號,一般的文字也可以用 &#{ascii_code}; 來編碼,例如說 j 的 ascii code 是 106,就可以編碼成 j:
<iframe/src="javascript:alert(1)">如果你想要的話,可以把整串字全部都編碼,就只會剩下一些符號跟數字而已。
惱怒的小明這次不演了,直接禁用 src 屬性,想說「那我把 src 都禁用就沒事了吧?不要再來煩我了!」
但他忘記的事情是,<a> 也可以用這個屬性:
<a/href="javascript:alert(1)">點我</a>只是這次就不會自動觸發了,需要使用者主動點擊才能觸發。
最後小明真的受不了了,於是覆蓋了一張 DOMPurify,結束這個回合。
除了上面的這些標籤跟屬性的繞過以外,JavaScript 本身的繞過也滿好玩的,例如說:「有沒有辦法在不使用 () 的狀況下執行函式?」
如果你有用過 React 的 styled-components 或類似的東西,應該寫過像這樣的程式碼:
const Box = styled.div`
background: red;
`為什麼這樣就可以產生出一個 component 呢?這是因為反引號除了可以用來當作 template string 以外,也可以拿來當作函式呼叫,這我在 Intigriti’s 0521 XSS 挑戰解法:限定字元組合程式碼裡面有提到過。
所以可以這樣寫:
alert`1`那如果現在連反引號都不能用呢?有沒有其他方法?
有一個我第一次看到的時候讚嘆了許久的方法:
onerror=alert;throw 1它把 window.onerror 改寫成 alert,再拋出一個錯誤,而這個錯誤因為沒有被 catch 到,就會被 window.onerror 接住,最後被丟到 alert 裡面執行。
除了 alert 以外,改寫一下就可以執行任意程式碼:
onerror=eval;
throw "=alert\x281\x29"第一行跟剛剛一樣,只是這次把 onerror 變成了 eval,但第二行是在做什麼呢?先講一下那個 \x28 跟 \x29,分別是 () 的編碼。
但為什麼前面多一個 =?
這是因為把錯誤拋出去的時候,如果是 Chrome,它最後會產生的字串是:Uncaught {err_message},像是 throw 1,就會產生出 Uncaught 1,但這樣並不是一段 JavaScript 程式碼,丟到 eval 會直接噴出錯誤。
所以我們把 "=alert\x281\x29" 丟出去,就會變成 Uncaught=alert\x281\x29,整句變成了一個 expression,Uncaught 被當作是沒有宣告的全域變數,它的值是 alert(1) 的回傳值,如此一來,整段 error message 就變成合法的 JavaScript 程式碼了!利用這樣的方式丟給 eval,就可以正常執行。
其實還有一些更驚人的手法,但篇幅有限而且有些我也還在努力看懂,所以就先在此打住,以下圖做個總結:

字數限制
除了上面那些屬性以及字元的限制以外,還有另一種限制叫做字數限制。
舉例來說,如果有個網站的暱稱有 XSS 漏洞,可是只能輸入最多 25 個字,這種情況下只跳出一個 alert 是沒有殺傷力的,你有辦法執行任意程式碼嗎?
最短的 XSS payload <svg/onload=> 的這個骨架就有 13 個字了,因此我們只剩下 12 個字可以來執行程式碼,這時候就需要用到一個技巧,那就是「利用現有資訊」,像是這樣:
// 13 + 18 = 31 字
<svg/onload=eval(`'`+location)>這短短的程式碼隱藏了不少細節,首先呢,如果你想拿到網址,你會怎麼做?location.href 嗎?更短的做法是把 location 轉成字串,你一樣能拿到網址。但網址本身不是合法的程式碼,所以我們要在前面加上一個單引號,接著再利用網址列上的 #,例如說這樣:https://example.com#';alert(1),跟單引號拼起來就會變成:
'https://example.com#';alert(1)這就是一段合法的 JavaScript 程式碼了,因為它變成一個字串後面接指令!
除了 location 以外,document.URL 也可以拿到網址,但這字數明顯比 locaton 多,可是你知道嗎,document 可以省略,變成這樣:
// 13 + 13 = 26 字
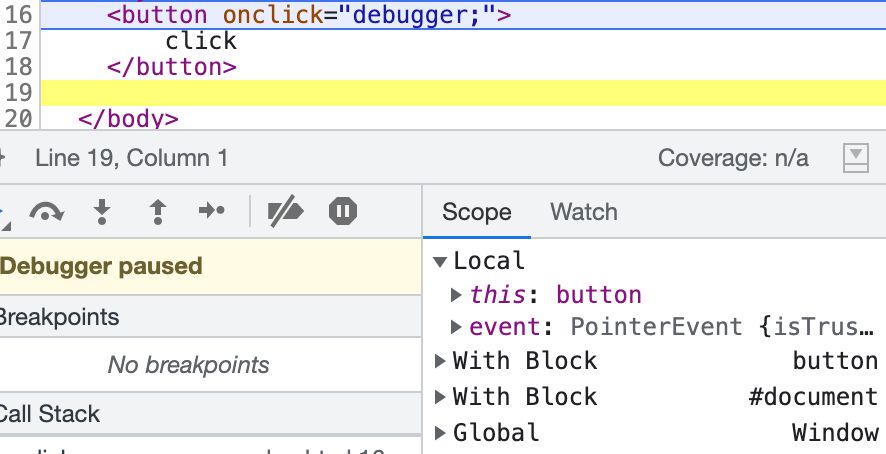
<svg/onload=eval(`'`+URL)>為什麼不需要寫 document?這是因為有個隱藏的規格,在 event handler 裡面的 inline 程式碼,預設就會有 document 這個 scope:

用 debugger 看也很明顯,所以儘管我們只輸入 URL,也會因為 scope 跟 with 的關係找到 document.URL
只差一個字就可以壓在 25 個字以內了,還有其他招式嗎?有,請先看一下底下的程式碼,你預期的輸出是什麼?
name = 123
console.log(typeof name === 'number')應該是 true 對吧?123 是數字,十分合理啊!但如果你真的在瀏覽器上面執行,會發現輸出居然是 false,因為 typeof name 是 string!
這是因為 name 是一個特別的屬性,它代表了這個視窗的名稱,或簡單一點也可以想成是這個分頁的名稱,換句話說,同一個分頁儘管內容不同,依然會共享同一個名稱!
假設我要攻擊的網站是 example.com,我的網站是 huli.tw,我可以在我的網站底下這樣寫:
<script>
name = 'alert(1)'
window.location = 'http://example.com'
</script>設置完 name 以後跳轉過去目標網站,接著在目標網站輸入這組 payload:
// 13 + 10 = 23 字
<svg/onload=eval(name)>因為 name 會共享的關係,就可以成功執行我想要的程式碼,這次只要 23 個字,成功壓在 25 個字以內。
有一個網站叫做 Tiny XSS Payloades,專門收集這些很短的 payload,裡面有更多千奇百怪的 payload,有需要的話可以參考看看,我所知道的 payload 也都是從這個網站來的。
XS leaks
上面講完了一些限制的繞過以後,我們來看看另一個主題,叫做 Cross-Site Leaks(簡寫為 XS Leaks),這個攻擊其實就是網頁上的一種 side-channel attack,有關於 side-channel attack,我之前在 CORS 完全手冊(五):跨來源的安全性問題裡面有提到過,用很知名的 Spectre 來舉例。
什麼是 side-channel attack 呢?就是你透過一些方法「間接」得知了資訊,例如說假設你面前有一個燈泡,但你的眼睛完全看不見,連光源都感受不到,你要怎麼知道這個燈泡現在是亮的還是不亮的?
有一種方式是透過「溫度」,因為燈泡如果亮著會發光,可能會產生熱能(先假設這前提為真然後忽略一些 edge case,舉例用途而已),因此你摸燈泡的時候就感覺得到熱度,這就是透過溫度間接得知了燈泡亮不亮這個資訊。
把這個概念用在網頁上的話也是類似的,透過一些方法間接得知網頁上的資訊,我們來看兩個例子。
搜尋與下載
假設現在有一個具有搜尋與下載功能的網站,可以在 query string 直接帶入想要搜尋的字串,例如說 https://example.com/download?q=example,如果資料庫裡面沒有符合的資料,就會出現一個「查無使用者」的畫面:

反之,如果有資料的話,就會直接跳出原生的檔案下載視窗,讓你直接下載相對應的檔案:
身為一個攻擊者,我們知道這個資訊以後可以做些什麼呢?
假設我有一個自己的網站,網址是 https://huli.tw,接著我在我的網站上面把剛剛的範例網站用 iframe 嵌入:
const iframe = document.createElement('iframe')
iframe.src = "https://example.com/download?q=user01"
document.body.appendChild(iframe)這時候關鍵的來了,如果 user01 這筆資料不存在於資料庫裡面,當我試著存取 iframe.contentWindow.origin 的時候就會出錯,這是因為 huli.tw 跟 example.com 不是同源的網站,所以被瀏覽器的 Same-Origin Policy 擋了下來。
但是呢!如果 user01 這筆資料存在於資料庫裡面,不是就會直接跳出下載畫面嗎?這時候如果我去存取 iframe.contentWindow.origin,就不會出錯,因為我會拿到 null 這個結果。
所以我們可以根據存取 iframe.contentWindow.origin 的結果,得知某個關鍵字是否存在於資料庫裡面:
const iframe = document.createElement('iframe')
iframe.src = "https://example.com/download?q=user01"
document.body.appendChild(iframe)
// 先假設一秒後會載入完畢,可以做到更精確但先跳過
setTimeout(() => {
try {
iframe.contentWindow.origin
console.log('使用者存在')
} catch(err) {
console.log('使用者不存在')
}
}, 1000)這就是 XS leaks,我們明明在 A 網站,卻可以利用一些技巧去得知 B 網站的資訊。
完整的攻擊實作會把上面的攻擊腳本延伸,例如說先測 a 再測 b 之類的,假設測到 b 是存在的,那就重複剛剛的流程去測 ba, bb…,如此一來就可以洩漏出至少一組的使用者帳號。接著只要把這個網頁的連結傳給有權限存取到 https://example.com/download 頁面而且處於登入狀態下的人,點開以後攻擊就會啟動。
雖然說聽起來前置步驟有點多,但它確實是個可行的攻擊手法。
id 的奧妙
假設現在有個標榜隱私度極高的社群網站,你沒有辦法看到你好友的好友有誰,看不到共同好友,所以你也不知道誰跟誰是朋友,只知道自己有哪些朋友。
你跟 user id 是 123 的 David 是好朋友,所以當你點進他的個人頁面:http://example.com/users/123 時,會看到一個按鈕「傳送訊息」,按鈕的 id 是 message:

而你跟 user id 是 210 的 Peter 並不是好友,所以點進他的頁面以後,會看到另一個按鈕叫做「加入好友」,id 是 add:

這聽起來都沒什麼問題,十分合理的實作,網頁上的元素有 id 再合理不過了。不過,其實這樣也會有 XS leaks 的風險。
瀏覽器有一個貼心的功能不知道大家有沒有注意過,當網址後面加上 #id 的時候,瀏覽器會自動跳到有這個 id 的段落然後把元素 focus(如果可以被 focus 的話),文章的錨點(anchor)功能就是靠這個,才能跳到特定的段落去。
因此當我連到 http://example.com/users/123#message 時,如果我跟 id 為 123 的人是好友,那頁面上就會出現傳送訊息的按鈕,瀏覽器就會跳到按鈕那邊並且把按鈕 focus。那如果我跟 123 不是好友呢?那就不會有任何事情發生。所以我們可以透過這個差異,來知道 id 123 的人是不是當前使用者的好友。
做法跟剛剛的搜尋下載很像,都是要先把目標網頁嵌入 iframe 之中,如果有這個 id 存在,那 iframe 就會 focus,而原本的 body 就會 blur:
window.onblur = () => {
console.log('是好友')
}
const iframe = document.createElement('iframe')
iframe.src = 'https://example.com/users/123#message'
document.body.appendChild(iframe)接著把這個網頁傳給你想知道他好友狀況的人,他一打開網頁之後,你就能知道他跟 123 是不是好朋友。如果這個網站的 id 是流水號,你就可以遍歷每一個 id,得知他的好友清單裡面有誰。
以上就是兩個 XS leaks 的範例,都是透過一些瀏覽器或是 JS 的特性來達成的攻擊,如果你對這些有興趣,可以參考:XS-Leaks Wiki,裡面有更多更有趣的案例(我所知道的這些也是從這個網站來的)
如果想看 XS leaks 的實際案例,這邊有很多:Mass XS-Search using Cache Attack,而最近的這一個也很有趣:Abusing Slack’s file-sharing functionality to de-anonymise fellow workspace members
其他你可能不知道的功能
最後一個段落裡面想跟大家分享一些「你可能不知道」的功能,或更精確一點來說,是「我知道以後很驚訝」的功能,我原本沒有想到原來可以這樣做。
在設定 Cookie 的時候有許多參數可以設置,其中一個叫做 path,例如說我設定 cookie 的 path 是 /siteA,那當我在 /siteB 的時候,就沒辦法讀取到 /siteA 的 cookie,因為 path 不一樣,所以沒辦法拿到。
但其實不一定,如果你的網站沒有阻擋 iframe 嵌入,而且 cookie 又沒有設置 HttpOnly,就可以利用 iframe 來讀取不同 path 的 cookie:
// 假設我們在 https://example.com/siteA
const iframe = document.createElement('iframe')
iframe.src = 'https://example.com/siteB'
iframe.onload = () =>
alert(iframe.contentWindow.document.cookie)
}
document.body.appendChild(iframe)這是因為 https://example.com/siteA 跟 https://example.com/siteB 雖然 path 不同,但是是同源的,因此可以直接透過 iframe 來存取同源的其他網頁的 document,就可以利用這個特性拿到 document.cookie
如果沒有支援 iframe,那其實 window.open 也可以達到一樣的效果:
const win = window.open('//example.com/siteB')
setTimeout(() => {
alert(win.document.cookie)
}, 1000)不過要注意的是 window.open 預設會被擋住,要使用者主動允許才能開啟,或者是要使用者做操作以後執行(例如說把上面那段放在 button onclick 裡面)。
而我後來發現其實 RFC 6265 的 section 8.5: Weak Confidentiality 就有提到了(奇怪,以前讀的時候怎麼沒注意到):
Cookies do not always provide isolation by path. Although the network-level protocol does not send cookies stored for one path to another, some user agents expose cookies via non-HTTP APIs, such as HTML’s document.cookie API. Because some of these user agents (e.g., web browsers) do not isolate resources received from different paths, a resource retrieved from one path might be able to access cookies stored for another path.
讀取 PDF 內容
假設你的網站上嵌入了一個 same origin 的 pdf 檔案,像這樣:
<embed src="/test.pdf">這時候你該怎麼用 JS 去讀取這個 pdf 裡面的內容?想必答案一定就是 fetch 或是 xhr 了:
fetch("/test.pdf")
.then(res => res.blob())
.then(res => {
console.log('pdf', res)
})那如果 fetch 沒辦法用呢?舉例來說,server 在後端擋住來自 fetch 的請求(利用 Fetch Metadata),這時候該怎麼辦呢?有沒有什麼方法可以讀到 PDF 的內容?
我以前一直覺得不可能有,直到我學到了一個隱藏的 Chrome API:
/** @override */
handleScriptingMessage(message) {
if (super.handleScriptingMessage(message)) {
return true;
}
if (this.delayScriptingMessage(message)) {
return true;
}
switch (message.data.type.toString()) {
case 'getSelectedText':
this.pluginController_.getSelectedText().then(
this.handleSelectedTextReply.bind(this));
break;
case 'getThumbnail':
const getThumbnailData =
/** @type {GetThumbnailMessageData} */ (message.data);
const page = getThumbnailData.page;
this.pluginController_.requestThumbnail(page).then(
this.sendScriptingMessage.bind(this));
break;
case 'print':
this.pluginController_.print();
break;
case 'selectAll':
this.pluginController_.selectAll();
break;
default:
return false;
}
return true;
}從這段程式碼裡面可以看出有兩個指令 selectAll 跟 getSelectedText,前者可以全選 PDF 的內容,後者可以拿到選取的文字,因此只要結合這兩個,就能拿到 PDF 裡面的文字內容:
// HTML: <embed id="f" onload="loaded()" src="...">
window.addEventListener('message', e => {
if (e.data.type === 'getSelectedTextReply') {
alert(e.data.selectedText)
}
})
function loaded() {
f.postMessage({type:'selectAll'}, '*')
f.postMessage({type:'getSelectedText'}, '*')
}一個簡單的 demo 網頁:https://aszx87410.github.io/demo/mw2021/05-pdf/index.html
雖然說這個技巧只能用在文字上面,但這種隱藏的功能真是令人興奮。
結語
先補充一下,上述的有些攻擊並不是所有環境都適用,例如說有些攻擊需要網站沒有擋 iframe,而拿來身份驗證的 cookie 可能也不能設定 SameSite,否則就會失效,利用 name 來傳 payload 的方法在某些瀏覽器可能也不適用,但我覺得這都不影響這些攻擊的有趣程度。
文章中有些繞過的部分並沒有寫得很完整,因為我把重點放在「找到至少一種繞過方式」,而不是「寫出所有繞過方式」,想看更完整的繞過技巧可以參考:Cheatsheet: XSS that works in 2021。
這篇文章提到的許多技巧,都是我透過打 CTF 學習而來,例如說下載檔案的 XS leaks 從 LINE CTF 2021 - Your Note,讀取不同 path 的 cookie 是從 DiceCTF 2021 - Web IDE 學到的,Chrome 的隱藏 API 則是在 zer0pts CTF 2021 - PDF Generator 學習到的技巧,透過 CTF 讓我看見了不一樣的 Web。
以上就是我近期學習到的一些與前端相關的知識,每一個都超出了我的想像,希望這篇文章有讓大家感受到我當初的驚訝,覺得:「哇,原來前端還有這些東西,我怎麼都不知道」。
評論