Introduction
In recent years, front-end frameworks have been flourishing, and many beginners who have just learned JavaScript have directly learned the three major frameworks (although React is not a framework, the entire ecosystem is actually no different from the framework, so I think it can be classified as a framework).
These three major frameworks are usually used to write SPA (Single Page Application). I have always believed that some basic knowledge should be possessed before learning these frameworks, especially the understanding of front-end and back-end. Otherwise, you will definitely encounter many problems that you don’t know where to start.
Therefore, this article uses a problem that I have encountered myself and that students often come to ask me as an example. You can also think about whether you can answer this question:
Suppose I have an SPA, using a library of some routers to implement routing, so
/listwill go to the list page, and/aboutwill go to the about me page.But strange, when I uploaded the SPA to GitHub Pages, the homepage is good, and when I go to
/listfrom the homepage, it is also good, but when I refresh/list, it shows 404 not found. Why is this?
To answer this question, you must first review some basic knowledge related to front-end and back-end networks.
Dynamic and Static Web Pages
First of all, what do you think dynamic and static web pages are? What is the difference between them?
When we talk about dynamic and static, what we are actually talking about is not whether the content on the webpage will change. It refers to whether the webpage I requested has been “processed” by the server. This definition may not be accurate, but you will understand it when I give a few examples below.
Let’s start with the simplest example. Suppose there is a file called a.php, and the code is like this:
<?php
echo "hello!";
?>If I visit a.php today and see the content like this:
<?php
echo "hello!";
?>What does it mean? It means that this is a “static webpage”, and the server did not process this file with PHP-related programs, but returned this a.php as a “file”, which is commonly known as a static file.
If we see the content like this:
hello!It means that the server executed this a.php and returned the output as a response. This type of webpage is called a “dynamic webpage”. Although the content has not changed, it is indeed a dynamic webpage.
This is the difference between dynamic and static. In fact, it has nothing to do with whether the content you see will change. Static will directly return the requested resource as a file, and dynamic will return the result as a response after processing on the server.
To ensure that you fully understand this concept, let’s take a look at this example, index.html:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
</head>
<body>
</body>
<script>
document.writeln(new Date())
</script>
</html>Is this a dynamic or static webpage?
The answer is static. Because this is a static HTML file, it is not specially processed by the server and is directly transmitted to the client. The content seen by the client is the content of the file stored on the server. Although the information on the screen will change, as I said before, this is not the standard for distinguishing dynamic or static.
After talking about dynamic and static, let’s talk about the way the server handles requests.
Server and Path
What is the most common type of URL you see? It is like a file, such as GitHub Pages: http://aszx87410.github.io/mars-lang-chrome-extension/index.html, the latter part mars-lang-chrome-extension/index.html represents that there is an index.html file under the mars-lang-chrome-extension folder.
This URL somewhat reflects the real file path, so accessing any page is similar to accessing a file. But these can actually be adjusted through server settings!
This means that if I want to, I can make https://huli.tw/123 output the file located on my server at /data/test.html. All of these can be adjusted.
Therefore, the URL and the real file path can be similar or completely different, and these can be adjusted on the server. Generally, there are two types of servers related to files.
The first is a “completely static” static file server, which means that no matter what file it is, it will not be processed, and it will correspond to the file path. Whatever the file is, it will output the content.
The most classic example is GitHub Pages. No matter if you put PHP, Ruby, or JavaScript, it will only output the “file content” as it is, without executing the script. Therefore, you cannot run anything related to the server on GitHub Pages. You cannot run PHP, Rails, or Express because it will not process anything and will only return the file content.
The second type is the classic Apache Server, usually used with PHP. It will execute the PHP file before returning the result. Files other than PHP are treated as static files, just like GitHub Pages.
Going back to our example, if you have a file called a.php with the content:
<?php
echo "hello!";
?>If you upload this file to GitHub Pages, you will only see the above content because it is just a file.
But if you put this file on a Server with Apache + PHP, you will see hello! because the Server executes this PHP before outputting the result.
Now that we have these basics, we can naturally solve the first problem.
Suppose I have an SPA that uses a router library to implement routing, so
/listwill go to the list page, and/aboutwill go to the about me page.But strange enough, when I upload the SPA to GitHub Pages, the homepage is fine, and when I go to
/listfrom the homepage, it is also fine. But when I refresh/list, it shows 404 not found. Why is that?
As mentioned earlier, GitHub Pages is a completely static server, and the URL corresponds to the real file path. So when you access the root directory /, the default setting will look for /index.html, so you can access the file normally.
But when you visit /list, you don’t have /list/index.html on your GitHub, so of course, it will show 404 not found, which is not very reasonable, right?
At this point, you must ask:
Then why is it okay when I go from the homepage to the list page?
To answer this question, let’s take a look at how SPA routing is implemented.
SPA Router Implementation
Do you remember the definition of SPA? Single Page means it never changes pages and always stays on the same page.
But if you can’t change pages, isn’t the URL the same? Isn’t that very inconvenient? I just need to refresh, and I will return to the starting point, standing dumbly in front of the mirror, and return to the same page.
Is there a way that looks like changing pages but doesn’t really change pages?
Yes! That is to add a # after the URL and then change what is behind it!
For example, it was index.html, and switching to the list page becomes index.html#list, and the about me page is index.html#about. Isn’t that good!
The result looks like this:
Example here, the complete code is as follows:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<style>
.page {
display: none;
}
</style>
</head>
<body>
<nav>
<a href="#home">home</a> |
<a href="#list">list</a> |
<a href="#about">about</a>
</nav>
<div class="page home-page">I am homepage</div>
<div class="page list-page">I am list</div>
<div class="page about-page">About me </div>
</body>
<script src="https://code.jquery.com/jquery-1.12.4.min.js"></script>
<script>
function changePage(hash) {
$('.page').hide()
if (hash === '#home') {
$('.home-page').show()
} else if (hash === '#list') {
$('.list-page').show()
} else if (hash === '#about') {
$('.about-page').show()
}
}
// 初始化
changePage(location.hash)
// 每當 hash 變動的時候
window.addEventListener("hashchange", function() {
changePage(location.hash)
});
</script>
</html>Use # after the URL to distinguish where you are, and this is the hashRouter mentioned in react-router.
But this way, the URL becomes ugly, and it is different from other people’s URLs, and there will be a hashtag. Is there a way to make the hashtag disappear?
Yes! That is to use the History API provided by HTML5, which allows you to manipulate the URL bar with JavaScript without really changing pages.
In the paragraph below the “pushState() method example” on MDN, it is written as follows:
Suppose http://mozilla.org/foo.html executes the following JavaScript:
var stateObj = { foo: “bar” };
history.pushState(stateObj, “page 2”, “bar.html”);
This will make the URL bar display http://mozilla.org/bar.html, but it will not cause the browser to load bar.html or even check if bar.html exists.
The key is this sentence: “but it will not cause the browser to load bar.html.” Even if the URL changes, as long as the browser does not load other pages, it is not called “changing pages.” Therefore, SPA never means “the URL cannot change,” but cannot load other pages. This point must be clear.
Example:
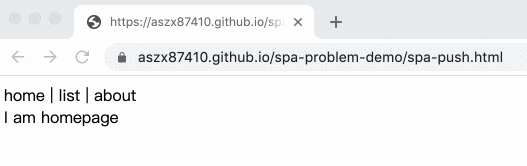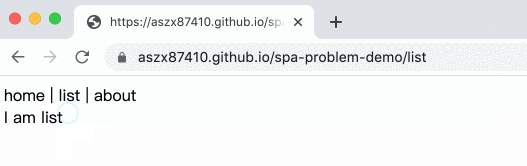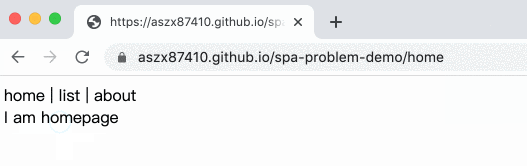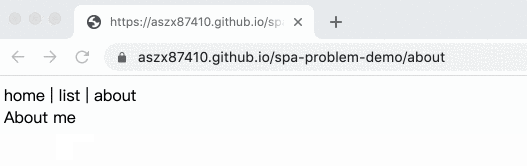
Here’s the complete code:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<style>
.page {
display: none;
}
.home-page {
display: block;
}
</style>
</head>
<body>
<nav>
<span onclick="changePage('home')">home</span> |
<span onclick="changePage('list')">list</span> |
<span onclick="changePage('about')">about</span>
</nav>
<div class="page home-page">I am homepage</div>
<div class="page list-page">I am list</div>
<div class="page about-page">About me </div>
</body>
<script src="https://code.jquery.com/jquery-1.12.4.min.js"></script>
<script>
function changePage(page) {
$('.page').hide()
if (page === 'home') {
$('.home-page').show()
} else if (page === 'list') {
$('.list-page').show()
} else if (page === 'about') {
$('.about-page').show()
}
// 精華所在
history.pushState(null, null, page)
}
</script>
</html>When switching pages, we use pushState to change the URL, so the URL changes, but the new page is not actually loaded. It’s perfect!
After filling in this knowledge, we can finally answer the first question. When we implement SPA, we use pushState to change the URL in the front-end, allowing us to update the address bar using JavaScript without actually loading the resource.
But what if we refresh the page? That means we need to load that resource directly! And the server doesn’t have that file, so of course it will return a 404 not found error. The reason why it works when we enter from the homepage is that from the homepage to the list page, we only use pushState to change the URL from / to /list.
But if we refresh /list directly, it means that the browser will send a request to /list for data, and naturally it will return a 404 not found error.
So how do we solve this problem? On GitHub Pages, you can set a custom 404 page, and you can set this 404 page to be your index.html, so no matter what the URL is, it will return index.html.
I uploaded a small demo here, and the code is here: https://github.com/aszx87410/spa-problem-demo, which is just copying the content of index.html to 404.html.
Alternatively, you can refer to this: rafrex/spa-github-pages, which uses a different method.
If you’re using nginx, just try index.html for all paths:
location / {
try_files $uri /index.html;
}Apache can refer to the configuration found on the internet: SPA - Apache, Nginx Configuration for Single Page Application like React.js on a custom path, which also redirects all paths to index.html.
Conclusion
When I first encountered this part, I was also confused and spent a lot of time understanding the difference between front-end and back-end routers. I found that I needed some basic knowledge to solve this problem. If you don’t know that the front-end router is implemented using the History API, you will naturally find it confusing.
And for beginners, all the problems are intertwined and it’s hard to break them down one by one, so it’s hard to find the answer to the problem.
I hope this article can help beginners understand what “no page switching” means in front-end SPA and how it is implemented.
Comments