前陣子去 JSDC 的線上前導活動分享了這個主題,想說既然都分享了,不如就寫篇文章好了。這篇文章的靈感來源以及內容其實都是來自於《JavaScript 重修就好》。當初寫書的時候就有參考 React 原始碼中的一些東西,這篇只是把原本分散在書中的各個 React 相關章節整理起來重寫一遍。
我覺得從這些開源專案的程式碼中學一些新的概念滿有趣的,畢竟這些很多人用的框架通常碰過的 bug 也越多,學到這些問題的解法以後,也可以再回去反思以前自己學過的東西。
這篇分成三個小章節:
- React 舊版的 XSS
- 從 React Fiber 學習 event loop
- 從 V8 bug 學習底層運作
開頭先聲明一下,雖然標題叫做「從 React 中學習 JavaScript 底層運作」,只有最後一個比較底層,第一個更是與底層沒什麼關係。只是我沒想到比這個更好的標題,因此就用這個了。
React 舊版的 XSS 漏洞
請問底下這段程式碼有什麼資安問題?
function Test() {
const name = qs.parse(location.search).name;
return (
<div className="text-red">
<h1>{name}</h1>
</div>
)
}看一看好像沒什麼問題?不就 render 一個 name 嗎,在 React 裡面會自動做 encode,所以就算插入一個 <img> 也不會被當作標籤解析,而是會被轉換成純文字,看起來沒問題。
若是我們繼續把這段程式碼展開,從 JSX 變成 JavaScript,大概會類似於這樣:
function Test() {
const name = qs.parse(location.search).name;
return createElement(
'div',
{ className: 'text-red' },
createElement(
'h1',
{},
name
)
)
}JSX 語法會在 compile 的時候變回 JavaScript,舊版會用 React.createElement,新版改成 _jsx 了,但不管 API 長怎樣,總之就是一段建立 element 的 JavaScript。
而這些 function 執行完以後就會產生所謂的 virtual DOM,再次展開成 object 的話會類似於:
function Test() {
const name = qs.parse(location.search).name;
return ({
type: 'div',
props: {
className: 'text-red',
children: {
type: 'h1',
props: {
children: name
}
}
}
})
}而 React 在 render 的時候,就會根據這個 object 去 render,並且展示出我們所傳入的 name。
但問題來了,像是 qs 這種 library,其實是支援物件的,例如說 ?name[test]=1,name 會變成 {"test": 1},因此這個 name 雖然你怎麼看都應該是字串,但實際上可以是個物件。
儘管通常傳物件會被 React 擋掉,但你有沒有想過這些 component 其實也是個物件?那 React 是怎麼決定一個 object 到底是不是 component 的呢?
在舊版的 React 中,這個檢查非常簡單:
ReactElement.isValidElement = function(object) {
return !!(
typeof object === 'object' &&
object !== null &&
'type' in object &&
'props' in object
)
}只要有 type 有 props,就把它看作是一個 React component。因此,如果我們的 name 是底下這樣,就會被當作是 React component 被渲染出來:
{
type: "div",
props: {
dangerouslySetInnerHTML: {
__html: "<img src=x onerror=alert()>"
}
}
}如此一來,就成功利用了這個特性,假裝是 React component 並且 render 出任意的 HTML,構造出了一個 XSS 漏洞。
這個漏洞最早在 2015 年時被 Daniel LeCheminan 發現,還寫了一篇文章:XSS via a spoofed React element,不過原文的情境稍微不同就是了。
總之呢,這個問題被 React 關注到,開了一個 issue 進行討論:How Much XSS Vulnerability Protection is React Responsible For? #3473,而最後的 fix 在這:Use a Symbol to tag every ReactElement #4832。
解法就是:Symbol。
在 React component 上加了一個 $$typeof: Symbol.for('react.element'),並且在 isValidElement 的檢查中也把這個判斷加上,就能確保其他物件沒辦法偽造出一個 React component。
背後的原理就是 symbol 的特性,與一般的物件不一樣,symbol 就只會跟同一個 symbol 相等,而 JSON 反序列化是不支援 symbol 的,所以你只能創造出普通的物件,沒辦法做出一個 symbol,自然就偽造不了 component 了。
以後有人問你 symbol 可以用在哪裡的時候,可以拿這個案例去回答。
另外,其實除了前端,後端也是一樣的,例如說 JavaScript 的 ORM:Sequelize 舊版本的 operator 也是用字串,例如說:
Post.findAll({
where: {
authorId: {
'$or': [12, 13]
}
}
});但從 v5 開始就全部換成 symbol 了,已經棄用了原本的字串:
const { Op } = require('sequelize');
Post.findAll({
where: {
authorId: {
[Op.or]: [12, 13]
}
}
});
// operators.ts
export const Op: OpTypes = {
eq: Symbol.for('eq'),
ne: Symbol.for('ne'),
gte: Symbol.for('gte'),
or: Symbol.for('or'),
// [...]
}背後原因相同,都是資安上的考量,當初的 PR 在這裡:Secure operators #8240。
話說直播的時候有人問,那如果你可以創造出一個 symbol,是不是這些防禦就沒用了?答案是:沒錯。但通常你要能做出 symbol,要嘛你已經可以執行程式碼了,要嘛開發者要自己加一個可以建立 symbol 的 deserializer,這兩個的達成難度都滿高的。
從 React Fiber 學習 event loop
2018 年的時候我寫過一篇 React fiber 相關的文章:淺談 React Fiber 及其對 lifecycles 造成的影響,而這個機制一語道破其實就是:「把同步的大 task 切成多個非同步的小 task」,藉此來避開阻塞 main thread。
那在 JavaScript 裡面,該怎麼來實作這個機制呢?要怎麼安排這些非同步的 task 呢?
React 16.0.0 - requestIdleCallback
在最早的 React 16.0.0 版本中,是用瀏覽器內建的 API:requestIdleCallback 來做的,MDN 的描述是:
The window.requestIdleCallback() method queues a function to be called during a browser’s idle periods. This enables developers to perform background and low priority work on the main thread, without impacting latency-critical events such as animation and input response.
window.requestIdleCallback() 方法會插入一個函式,並在瀏覽器處於閒置時呼叫該函式。這讓開發者能在主事件迴圈中執行背景或低優先度的工作,而不會影響到像動畫或使用者輸入回應這類對延遲敏感的事件。
把原本大的 task 切成小的 task 以後,用 requestIdleCallback 來安排下一個 task,讓瀏覽器在空閒的時候執行,就能不阻礙到 main thread。
React 16.4.0 - requestAnimationFrame + postMessage
但是在 React 16.4.0 時,被換成了另一種結合 requestAnimationFrame(以下簡稱 rAF) 跟 postMessage 的方式(這個方式其實一開始是做為沒有 requestIdleCallback 時的替代方案,但在這個版本被扶正,直接取代掉了 requestIdleCallback)。
在這個機制中,會建立兩種類型的 callback,一個是利用 rAF 安排的 callback,由瀏覽器自動觸發,而另一個則是用 window.addEventListener('message', fn) 安排的 callback,透過 window.postMessage 來觸發。
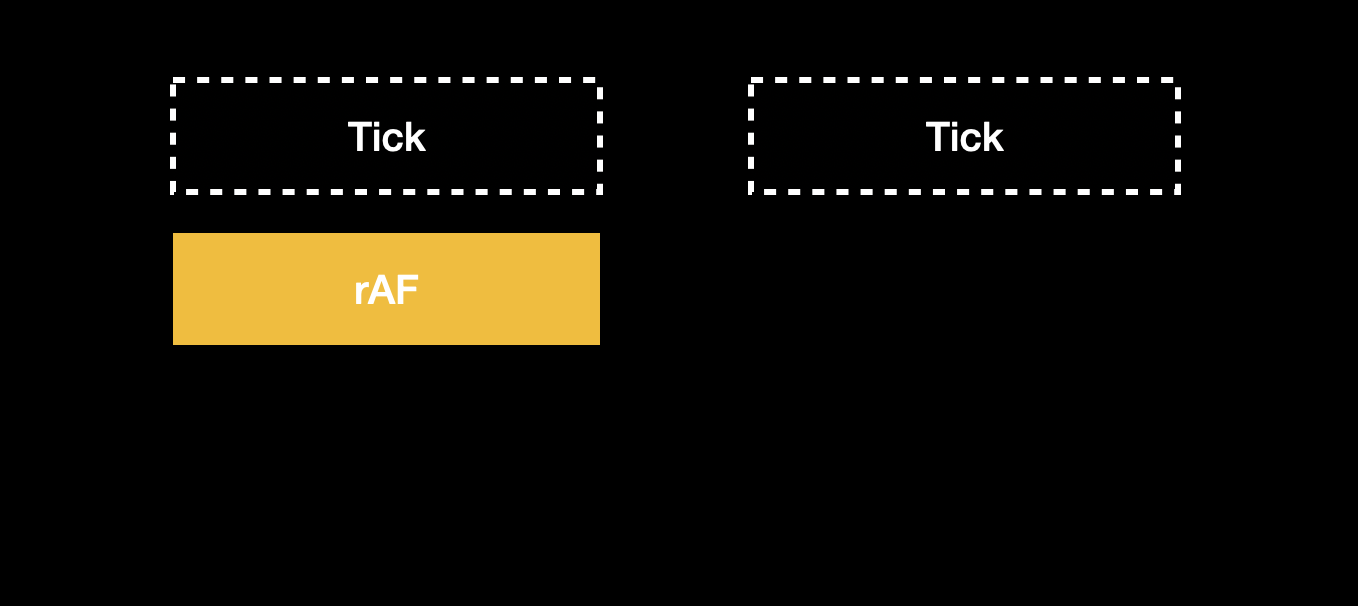
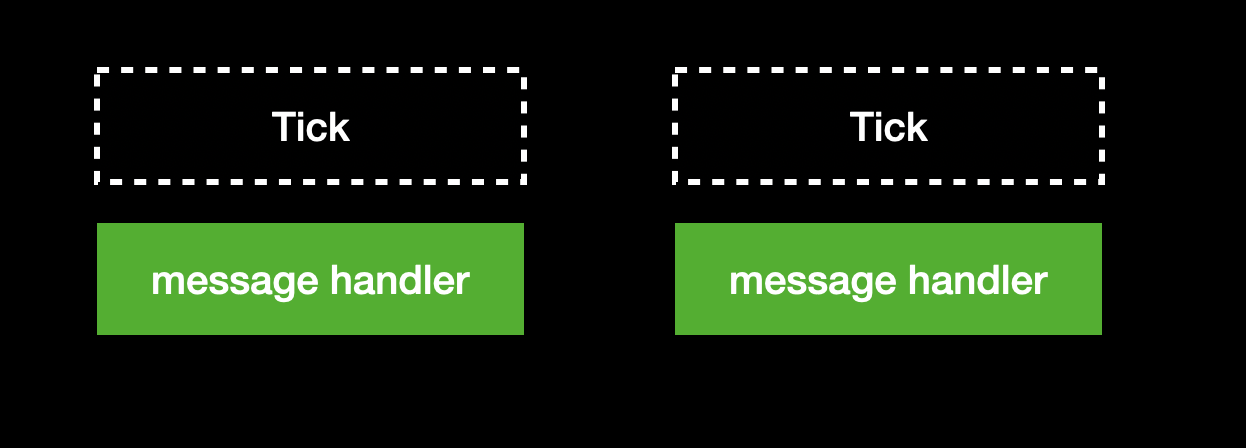
這個機制實際運作的方式是這樣的,底下每一個 tick 代表一次的 event loop,我們先安排一個 rAF,在裡面計算下次 rAF 應該觸發的時間(就是當前時間 + frame 長度(如 16ms)):
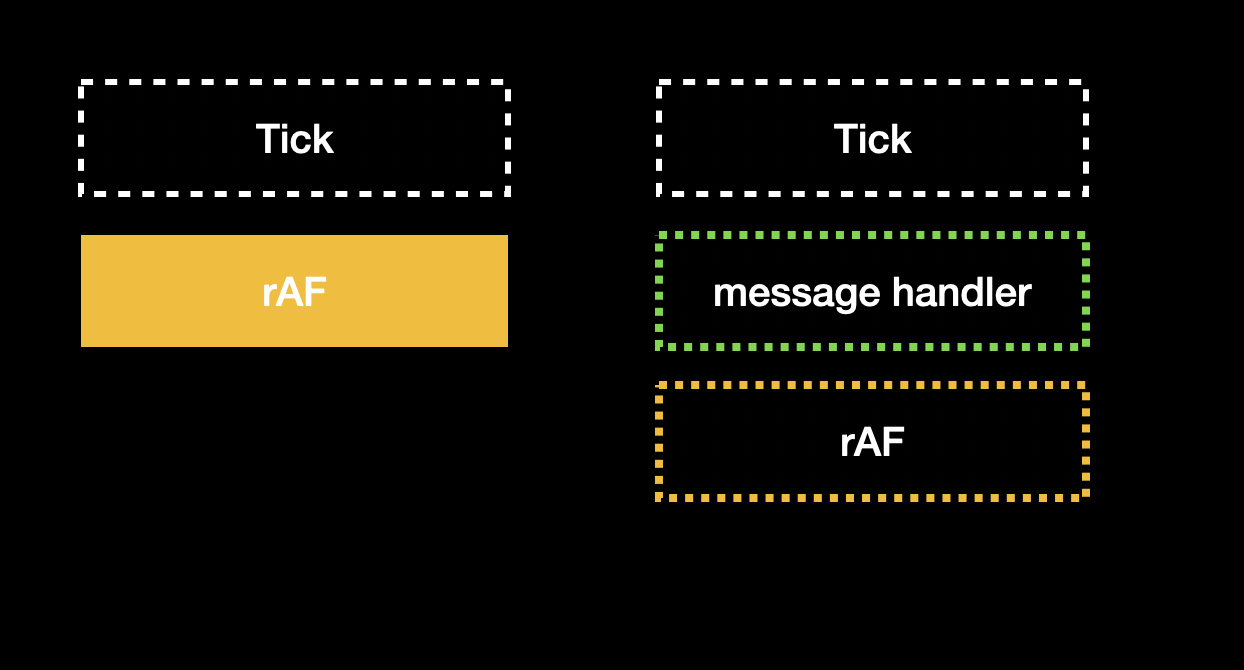
接著在裡面再次呼叫 rAF 還有 postMessage,安排下一次 tick 的 callback:
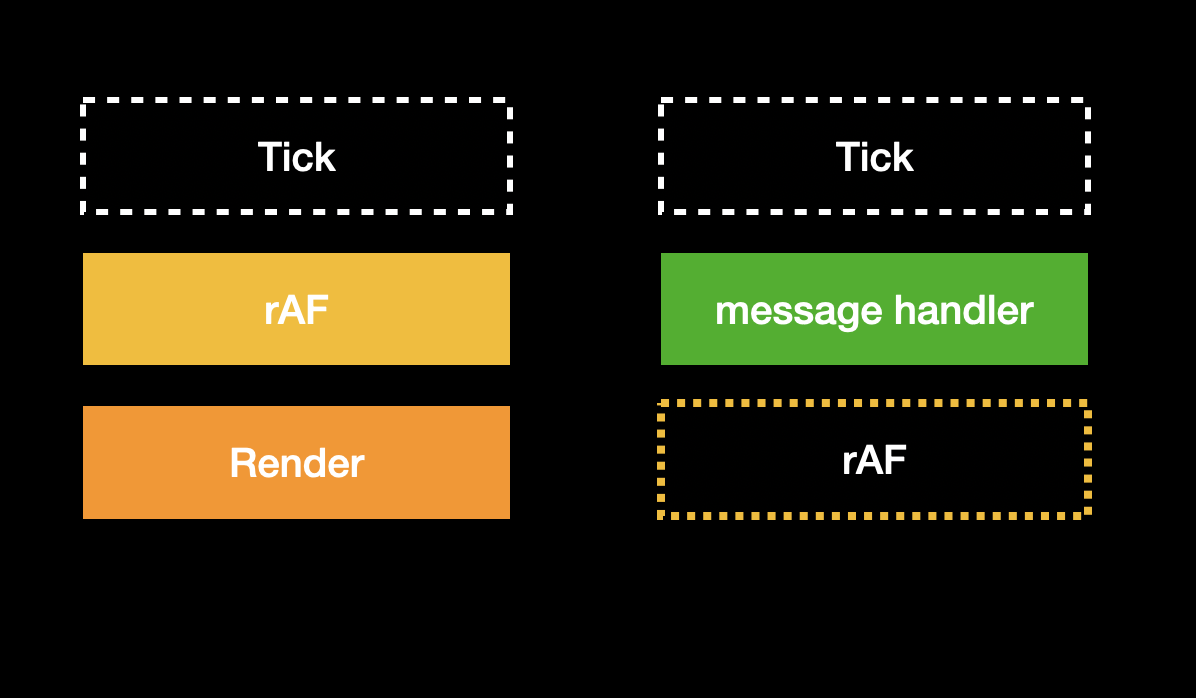
下一步是 browser render,結束之後進入下一個 tick,然後 message handler 被觸發:
由於剛剛已經計算過下次 rAF 應該被觸發的時間,所以 message handler 可以趁著這段時間(可能有個 5ms 或更長) 做事,在時間到之前不斷執行小的 task。
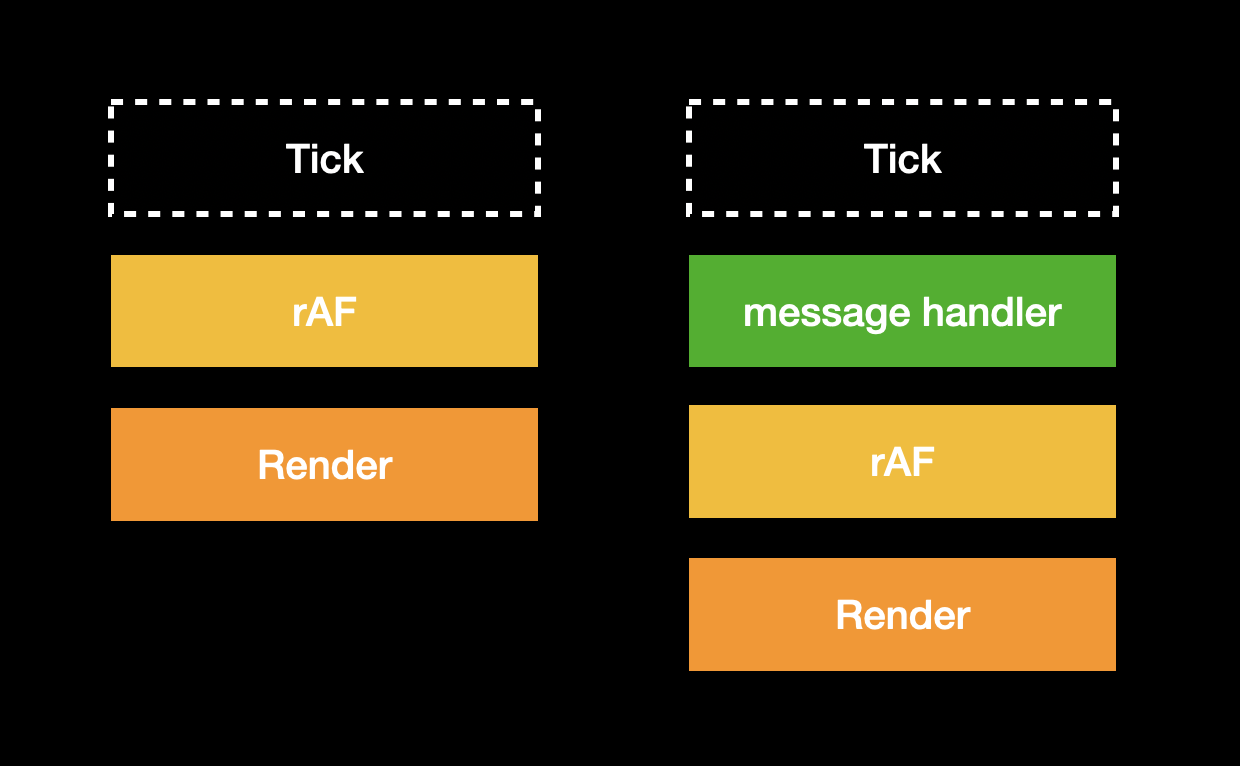
執行完以後 rAF 會再次觸發,做跟剛剛一樣的事情,安排下一個 tick 的 callback,然後 browser render,結束這個 tick:
這樣的流程不斷執行下去,就是整個非同步 task 的任務安排機制了,簡單來講就是:
- 在 rAF 裡面算出有多少時間可以執行 task 而不干擾 render
- 在 message handler 中盡量執行任務
在 React 原始碼中,rAF 會被叫做 Animation Tick,而 message handler 叫做 Idle Tick。
那為什麼要用 postMessage 跟 message handler 呢?原因是如果用 setTimeout(fn, 0) 的話,有個經典的 4ms 限制,如果你不斷利用 setTimeout 來安排 task,在重複遞迴安排幾次之後,最短的執行間隔就會變成 4ms,不論你 interval 設多少都一樣。
而 postMessage 跟 message handler 則沒有這個限制,因此就選了這個。
但是用 message handler 有個缺點,那就是目前的使用方式是 window.addEventListener('message', fn),因此每次安排 task 時都必須使用 window.postMessage,若是頁面上有別的 listener,就會一直一直被觸發。
像是有些擴充套件可能會印出所有收到的 message 來幫助 debug,可能每 30ms 左右就會收到一個,log 直接被打爆。像這樣有 side-effect 的行為顯然不是什麼好事,會干擾到其他的實作。
React 16.7.0 - requestAnimationFrame + MessageChannel
所以從 React 16.7.0 開始,就把這段改用 MessageChannel 來做了,這是另一個可以實作訊息交換的 Web API,用法跟原本的其實很像,只是多了個 port 的概念:
// DOM and Worker environments.
// We prefer MessageChannel because of the 4ms setTimeout clamping.
const channel = new MessageChannel();
const port = channel.port2;
channel.port1.onmessage = performWorkUntilDeadline;
schedulePerformWorkUntilDeadline = () => {
port.postMessage(null);
};在程式碼的註解中也可以看到為什麼 React 不用 setTimeout,跟我剛剛講的理由是一樣的,加上這個改動的 PR 在這:[scheduler] Post to MessageChannel instead of window #14234。
看起來好像就是這樣了?這個機制滿合理的,透過兩種不同類型的非同步 task 做不同的事情,並且在不干擾到 render 的前提下盡量做事。
React 16.12.0 - MessageChannel
但是,在 React 16.12.0 時,機制又變了一次,把 rAF 也拿掉了,只留下 MessageChannel 而已,每次執行最多 5ms:
那為什麼要換成這個機制呢?有兩個地方有說明,第一個是 16.12.0 裡的程式碼:
// Scheduler periodically yields in case there is other work on the main
// thread, like user events. By default, it yields multiple times per frame.
// It does not attempt to align with frame boundaries, since most tasks don't
// need to be frame aligned; for those that do, use requestAnimationFrame.
let yieldInterval = 5;翻中文是:
調度器會定期讓出執行權,以便主執行緒上若有其他工作(例如使用者事件)能夠被處理。預設情況下,它在每一幀中會讓出多次。它不會嘗試與畫面更新(frame)邊界對齊,因為大多數任務不需要與畫面對齊;若是需要對齊畫面更新,請使用 requestAnimationFrame。
大意就是因為任務不需要跟畫面 render 對齊,所以就不管 render 了,反正就是一直讓出去。
第二個説明則是在 Concurrency / time-slicing by default #21662 這個 issue 中,有人問說 scheduler 是不是還在用 requestIdleCallback 時,dan 哥的留言:
No, it fired too late and we’d waste CPU time. It’s really important for our use case that we utilize CPU to full extent rather than only after some idle period. So instead we rewrote to have our own loop that yields every 5ms.
不行,那個(機制)觸發得太晚,會浪費 CPU 時間。對我們的使用情境來說,盡可能充分利用 CPU 非常重要,而不是等到某個閒置時間才開始做事。所以我們改成自己寫一個每 5ms 就讓出一次的循環。
解惑了為什麼一開始把 requestIdleCallback 淘汰掉,因為觸發的太晚了。
那現在最新的 v19.2.0 版本的實作又是如何呢?
從程式碼中可以看出來,基本上就是上面那一套機制了,沒有太多改變,一樣是用 MessageChannel 安排 task,然後每隔一段時間讓出去。
不遠的未來:原生 Scheduler API
其實 Scheduler 這東西不止 React,只要需要非同步安排任務的都會用到。因此,瀏覽器其實有提供原生的 Scheduler API,只是很新所以支援度不太好,但可以預見在未來可能不需要自己寫一套了,用瀏覽器原生給的會是最好的。
事實上,React 現在就有用這個實作一套了,但還是 unstable 的狀態:SchedulerPostTask.js,原生直接支援安排不同優先順序的任務,比自己寫方便多了。
總之,從 React 對於安排非同步任務的程式碼中,可以學到幾個不同函式觸發的時機以及頻率的差別,也可以從這幾次的機制變動中,去了解為什麼 React 做出了這樣的選擇,讓我們更了解這些非同步的細節差異。
從 V8 bug 學習底層運作
延續剛剛講的 React fiber,在程式碼中有一段 profiler 相關的部分:
if (enableProfilerTimer) {
this.actualDuration = -0;
this.actualStartTime = -1.1;
this.selfBaseDuration = -0;
this.treeBaseDuration = -0;
}問題來了,為什麼這邊的初始值是 -0 而不是 0?這兩個有什麼差異呢?
甚至在舊一點的版本中,還先賦值成 NaN 才變成 0,這又是什麼魔法?
if (enableProfilerTimer) {
this.actualDuration = Number.NaN;
this.actualStartTime = Number.NaN;
this.selfBaseDuration = Number.NaN;
this.treeBaseDuration = Number.NaN;
this.actualDuration = 0;
this.actualStartTime = -1;
this.selfBaseDuration = 0;
this.treeBaseDuration = 0;
}這一切都跟 V8 底層的運作以及一個 bug 有關。
針對這件事情,其實 V8 自己有一篇部落格文章:The story of a V8 performance cliff in React,裡面講的已經很好了,麻煩自己去讀這篇文章,或是跟 AI 一起看,我就不再重複一次,底下只講結論跟重點。
首先,儘管我們都知道在 JavaScript 的規格中,所有的數字都是 double,但是 JavaScript 引擎在實作時可不一定,畢竟如果真的每個數字都存成 64bit 的 double,既會有空間問題也有效能問題,整數做加減也會是浮點數運算,誰受得了。
因此,在 V8 引擎中,其實數字還是有分兩種,一種是 32bit 的 int 叫做 small integer,簡稱 Smi,而另外一種就真的是浮點數了,叫做 HeapNumber,兩種存的位置是不同的,浮點數要存到 heap 去。
而為了幫 object 做一些優化,因此 object 在儲存時,會關聯到一個叫 shape 的東西,類似於 object 的 metadata,來存每個值的 type 以及 offset,同樣 interface 的 object 會共享同一個 shape。
在 object value 的型別改變時,這個 shape 也會一起跟著變,例如說從 Smi 變成 double,就會產生一個新的 shape。
而 V8 的這個 bug 簡單來講就是在 React profiler 中一開始會把某些值初始化成 0,型別是 Smi,接著用 Object.preventExtensions 來阻止新增新的屬性,然後把這個值改成浮點數(performance.now() 的回傳值)。
這樣的行為讓 V8 壞掉,不知道該怎麼處理 shape 的改變,於是就新增了一個全新的 shape。而且不只針對這一個 object,是所有類似的 object 都會,都無法共享 shape,而是每人有一個自己的。
儘管大多數人都不會察覺這種底層的差別,但因為 React 在測試時 node 數量很多,當基數放大後就能察覺到差異,演變成了一個性能問題。
雖然 V8 把 bug 修掉,所以現在不會有這問題了,但是 React 那邊也修了一版,例如說剛提到的 NaN,會設置成 NaN 是因為它底層是浮點數而不是 Smi,而現今的版本之所以是 -0 也是一樣的原因,-0 是浮點數,0 是 Smi。
當初始值跟後來的值都是浮點數時,就不會有這個 shape 改變的問題,也就不會碰到這個 V8 bug。
但是,你有沒有想過要怎麼知道 NaN 跟 -0 是浮點數呢?
從 V8 bytecode 看底層型別
除了翻規格以外,把程式碼編譯成 V8 bytecode 其實是個很好的方法,例如說底下的函式:
function test(x) {
return x === 0;
}
function AAAAA () {
test(0);
test(-0);
test(3);
test(0/0); // NaN
}
AAAAA()
我用指令 node --print-bytecode test.js > out 編譯後,得出的結果為:
[generated bytecode for function: AAAAA (0x31bb2f7de971 <SharedFunctionInfo AAAAA>)]
Bytecode length: 41
Parameter count 1
Register count 2
Frame size 16
Bytecode age: 0
62 S> 0x31bb2f7df776 @ 0 : 17 02 LdaImmutableCurrentContextSlot [2]
0x31bb2f7df778 @ 2 : c4 Star0
0x31bb2f7df779 @ 3 : 0c LdaZero
0x31bb2f7df77a @ 4 : c3 Star1
62 E> 0x31bb2f7df77b @ 5 : 62 fa f9 00 CallUndefinedReceiver1 r0, r1, [0]
73 S> 0x31bb2f7df77f @ 9 : 17 02 LdaImmutableCurrentContextSlot [2]
0x31bb2f7df781 @ 11 : c4 Star0
0x31bb2f7df782 @ 12 : 13 00 LdaConstant [0]
0x31bb2f7df784 @ 14 : c3 Star1
73 E> 0x31bb2f7df785 @ 15 : 62 fa f9 02 CallUndefinedReceiver1 r0, r1, [2]
85 S> 0x31bb2f7df789 @ 19 : 17 02 LdaImmutableCurrentContextSlot [2]
0x31bb2f7df78b @ 21 : c4 Star0
0x31bb2f7df78c @ 22 : 0d 03 LdaSmi [3]
0x31bb2f7df78e @ 24 : c3 Star1
85 E> 0x31bb2f7df78f @ 25 : 62 fa f9 04 CallUndefinedReceiver1 r0, r1, [4]
96 S> 0x31bb2f7df793 @ 29 : 17 02 LdaImmutableCurrentContextSlot [2]
0x31bb2f7df795 @ 31 : c4 Star0
0x31bb2f7df796 @ 32 : 13 01 LdaConstant [1]
0x31bb2f7df798 @ 34 : c3 Star1
96 E> 0x31bb2f7df799 @ 35 : 62 fa f9 06 CallUndefinedReceiver1 r0, r1, [6]
0x31bb2f7df79d @ 39 : 0e LdaUndefined
114 S> 0x31bb2f7df79e @ 40 : a9 Return
Constant pool (size = 2)
0x31bb2f7df711: [FixedArray] in OldSpace
- map: 0x3bc7231c0211 <Map(FIXED_ARRAY_TYPE)>
- length: 2
0: 0x31bb2f7df731 <HeapNumber -0.0>
1: 0x3bc7231c0561 <HeapNumber nan>
Handler Table (size = 0)
Source Position Table (size = 21)
0x31bb2f7df7a1 <ByteArray[21]>可以看到 3 就是直接 LdaSmi,代表是 Smi,而 -0 跟 NaN 是 LdaConstant,從 constant pool 載入進來,而這個 constant pool 裡面則寫著:
Constant pool (size = 2)
0x31bb2f7df711: [FixedArray] in OldSpace
- map: 0x3bc7231c0211 <Map(FIXED_ARRAY_TYPE)>
- length: 2
0: 0x31bb2f7df731 <HeapNumber -0.0>
1: 0x3bc7231c0561 <HeapNumber nan>很明顯可以看到這兩個都是 heap number,不屬於 Smi。
如果從理論上的角度來看也行啦,NaN 不能是 Smi,是因為 NaN 本來就是 IEEE 754 裡面定義的東西,而 -0 需要那個負號,這個在 int 中也沒有,所以也只能是個 double。
但總之呢,未來若是碰到這個底層型別的疑惑,可以編譯成 bytecode 之後確認,一目瞭然。
總結
這篇文章中我們從 React 原始碼中學到不少東西,分別是:
- Symbol 的用途,可以利用沒辦法反序列化的特性,來保證外界沒辦法構造出來
- 各種非同步函式如
requestIdleCallback、requestAnimationFrame、MessageChannel與setTimeout的觸發時機以及特性,還有 React 底層是怎麼安排 task 的。 - 在規格上看來所有 JavaScript 的數字都是 64bit double,但在 V8 底層其實還是有分 Smi 跟 double,可以用 bytecode 來確認型別。
以上內容都來自於我自己寫的《JavaScript 重修就好》這本書,書中還有提到更多有趣的案例,像是 Vue 又是怎麼實作非同步的,它的 nextTick 背後用的又是哪個函式?或是 IEEE 754 還定義了哪些東西,數字在使用時需要注意什麼地方等等。
如果有興趣的話可以找來看看,有什麼問題或建議都可以透過臉書粉專聯絡我。
評論