在 JavaScript 的幾個資料型別中,Number 是非常常用的一個,而且有些小地方需要特別注意,不然很容易寫出有 bug 的程式碼。
這篇會帶大家看一些案例,有些是假想的情境,也有些是我自己碰過的問題,在每個案例繼續往下講解之前,大家也可以試著把自己帶入情境,想想看自己知不知道問題的成因,又該如何避免。
案例一:從重複的 ID 開始談起
在前公司工作的時候,同事負責的是一個類似論壇的系統,而每個留言都會有一個獨特的 ID,既然都說是 ID 了,就代表是不會重複的。可是有一天呢,同事卻發現 ID 重複了!打開 DevTools 看 response 的內容,ID 確實是重複了沒錯,於是就跑去跟後端確認,順便唸了一下怎麼後端有 bug,產生出了重複的 ID。
但是後端檢查過之後,卻說沒有這回事,ID 是不可能會重複的,況且他也檢查過了,是不是前端有問題?
於是我同事再跑回去看了前端,發現了一個奇怪的現象。
當你在開發者工具中用「Response」分頁看時,ID 確實沒有重複:
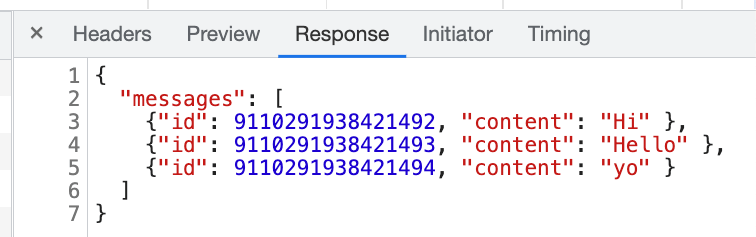
可是,一旦切到了「Preview」的分頁,卻發現 ID 居然重複了:
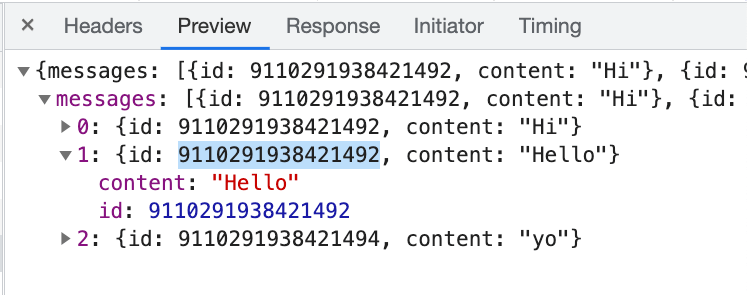
為什麼會有這麼神奇的現象呢?難道又是 JavaScript 的什麼奇妙 bug 嗎?
沒有,並不是。只是我同事對 JavaScript 的 Number 資料型別沒有這麼熟悉而已。
有範圍的數字
在上一篇來數數 JavaScript 的所有資料型別中我們有提過,JavaScript 的數字是用 64 bit 來存,而且遵循的規格是 IEEE 754-2019。
既然是用 64 bit 來存,就代表可以表示的資料量是有限的,可是數字是無限的,所以理所當然地,64 bit 不可能儲存所有的數字,因此一定就會有可儲存的上限跟安全範圍。
在 JavaScript 中,你可以用 Number.MAX_SAFE_INTEGER 拿到正整數的安全範圍,這個值會是 2^53 - 1,也就是 9007199254740991,那這個安全又是什麼意思呢?
MDN 這一段講得不錯:
Safe in this context refers to the ability to represent integers exactly and to correctly compare them. For example, Number.MAX_SAFE_INTEGER + 1 === Number.MAX_SAFE_INTEGER + 2 will evaluate to true, which is mathematically incorrect.
安全指的是這個數字可以正確地被表示而且拿來比較。換句話說,如果超出這個安全範圍,就不保證這件事情了,看個例子會更清楚一點:
console.log(9007199254740992 === 9007199254740993) // true
console.log(Number('9007199254740993')) // 9007199254740992看到這邊,你應該就知道我同事碰到的問題是為什麼了,這是因為後端傳來的 ID 太大的關係,在 Response 分頁中,只是呈現出最原始後端傳回來的資料,並沒有轉成 JavaScript 的物件;而在 Preview 的分頁中,JSON 格式的字串被轉成了 JavaScript 的物件,因此 ID 被轉成了 Number,超出了安全範圍,所以就有了誤差,就像是上面的範例一樣。
那這該怎麼解決呢?後端的 ID 應該要傳字串型別,前端在使用時也要記得不要轉成數字,都把 ID 當作字串來看待,就不會有這種轉成數字的誤差問題。
另外,上面提到的 Number.MAX_SAFE_INTEGER 指的是安全範圍,也就是說就算超出這個範圍,你還是可以儲存數字,只是不精準而已。那這些不精準的數字有沒有範圍呢?一樣也有,上限是 Number.MAX_VALUE:
console.log(Number.MAX_VALUE) // 1.7976931348623157e+308大概是 1.79 * 10^308,一個很大的數字,那超過這個範圍會怎樣呢?會變成正無限大:Infinity。
console.log(Number.MAX_VALUE + 1) // 1.7976931348623157e+308
console.log(Number.MAX_VALUE * 2) // Infinity咦,我上面不是說比 Number.MAX_VALUE 還大的話就是無限大嗎?為什麼 +1 之後沒有變成 Infinity?這原因就跟上面講的一樣,超出了安全範圍之後會變得不精準,所以其實 +1 之後還是同一個數字,如果你好奇那到底要加多少才會變成 Infinity,無聊的我把它找出來了,似乎是這個數字:
console.log(Number.MAX_VALUE + 9.9792015476735e+291) // 1.7976931348623157e+308
console.log(Number.MAX_VALUE + 9.9792015476736e+291) // Infinity總之呢,未來碰到這種大數相關的計算時,要記得 Number 的範圍上限,如果超出了這個範圍,可以改用最新的 BigInt 資料型別來處理,就不會碰到這些問題。
案例二:最近點對
前幾年為了讓學生練習程式的基本語法,我架了一個 LIOJ,上面有一些我自己出的題目。
其中有一題難度並不是特別高,甚至可以說是滿普通的,可是只有將近 25% 的答對率。
題目連結在這邊:LIOJ 1033 - 最近點對,有興趣的朋友們可以先去試試看,看是否能夠一次 AC(但要先熟悉一下 OJ 的輸出入模式)。
這題是這樣的,輸入因為是用讀檔案的方式,所以都會是字串,格式長這樣:
4
2 3
1 3
1 2
1 1第一行的 4 代表有 4 組資料,後面每一行為一組,都是一個代表 (x, y) 的座標,而這題就是要你求出距離最近的兩個點。如果有兩組以上都最近,請輸出最先出現在資料的那組。
而輸出的時候請先輸出 x 比較小的那個點,若是 x 相同,請先輸出 y 比較小的那個點
以上面的測試資料為例,答案就會是:
1 3
2 3這題看似沒什麼難度,到底大家是犯了什麼錯,才會解不開呢?
我們先來看一個常見的解法:
const input = `4
2 3
1 3
1 2
1 1`
const lines = input.split('\n')
const dots = lines.slice(1).map(item => item.split(' '))
let min = Infinity
let ans1, ans2
for(let i=0; i<dots.length; i++) {
for(let j=i+1; j<dots.length; j++) {
let dis = distance(dots[i][0], dots[i][1], dots[j][0], dots[j][1])
if (dis < min) {
ans1 = dots[i]
ans2 = dots[j]
min = dis
}
}
}
// 先輸出 x 比較小的點
if (ans1[0] > ans2[0]) {
console.log(ans2[0] + ' ' + ans2[1])
console.log(ans1[0] + ' ' + ans1[1])
} else if (ans1[0] < ans2[0]){
console.log(ans1[0] + ' ' + ans1[1])
console.log(ans2[0] + ' ' + ans2[1])
} else {
// 兩個相等,輸出 y 較小的點
if (ans1[1] > ans2[1]) {
console.log(ans2[0] + ' ' + ans2[1])
console.log(ans1[0] + ' ' + ans1[1])
} else {
console.log(ans1[0] + ' ' + ans1[1])
console.log(ans2[0] + ' ' + ans2[1])
}
}
function distance(x1, y1, x2, y2) {
return Math.sqrt(
(x1 - x2) * (x1 - x2) +
(y1 - y2) * (y1 - y2)
)
}看起來其實沒有什麼問題,把每一組都拿去算距離,距離算完之後找最小值,並且按照題目的要求輸出結果,而題目給的測試資料也有通過了。
但你如果實際丟到 OJ 上,會發現拿了 WA,代表上面這段程式碼是錯的。錯在哪裡呢?並不是錯在算距離,而是錯在輸出:
if (ans1[0] > ans2[0]) {
console.log(ans2[0] + ' ' + ans2[1])
console.log(ans1[0] + ' ' + ans1[1])
} else if (ans1[0] < ans2[0]){
console.log(ans1[0] + ' ' + ans1[1])
console.log(ans2[0] + ' ' + ans2[1])
} else {
// 兩個相等,輸出 y 較小的點
if (ans1[1] > ans2[1]) {
console.log(ans2[0] + ' ' + ans2[1])
console.log(ans1[0] + ' ' + ans1[1])
} else {
console.log(ans1[0] + ' ' + ans1[1])
console.log(ans2[0] + ' ' + ans2[1])
}
}假設最後找到的兩個點是 (11,12) 跟 (2,3),根據題目的敘述,應該要先輸出 x 比較小的點,也就是 (2,3),可是上面的程式碼卻會先輸出 (11,12),這是為什麼呢?
這是因為我們在讀取資料的過程中,並沒有把資料特別轉成數字,所以其實從頭到尾我們所認為的數字,都是字串型別。在計算距離時因為用的是減法(x1 - x2),所以 JavaScript 會自動轉型成數字之後相減。
可是比較的時候,依然會按照原始的資料型別,也就是字串來進行比較。而 JavaScript 對於字串的比較基本上是按照字典序的。簡單來說呢,你在查字典的時候,例如說你要查 cool,一定是先翻去 c 的頁面,然後開始找 co,再找 coo,這樣一個字一個字找,最後才會找到 cool。
而字典序的比較也是類似,是一個字一個字比的,所以當 JavaScript 在比較 "11" 跟 2 時,比對第一個字發現 "2" 比 "1" 大,於是結果就是 "2" > "11",跟數字的比較邏輯完全不一樣。
所以在做比較之前,請記得確認一下變數的資料型別,不同的型別會有不同的比較方式。以上面的程式碼為例,其實只要在讀取輸入時把字串都轉成數字就沒事了。
雖然我上面這樣寫,但有少數狀況下儘管你有注意到資料型別也沒有用,因為背後的運作跟你想的不一樣。
在 JavaScript 中,最有名的案例莫過於陣列的排序。
let arr = [2, 11, 3, 7, 42]
arr.sort()
console.log(arr) // ???上面的程式碼,我相信任誰看了都會覺得結果要嘛是 2,3,7,11,42,要嘛是反過來的 42,11,7,3,2,但結果出乎你的意料,很抱歉兩者都不是,答案是 11,2,3,42,7:
let arr = [2, 11, 3, 7, 42]
arr.sort()
console.log(arr) // [11, 2, 3, 42, 7]這是因為 Array.prototype.sort 預設的排序方式,會把陣列裡的元素都先轉成字串來排,我們來看一下規格(23.1.3.27.1 SortCompare, p658):

所以如果你要排序數字,那一定要傳入參數 comparefn,自定義比較的方式,例如說這樣:
let arr = [2, 11, 3, 7, 42]
arr.sort((a, b) => a - b)
console.log(arr) // [2, 3, 7, 11, 42]comparefn 的邏輯是這樣的,會傳入兩個陣列裡的元素 a 跟 b,如果 function 回傳負數,表示 a 排在 b 前面,如果回傳 0,表示 a、b 的順序都不會變,回傳正數則表示 b 排在 a 前面。
我自己則是用另外一種方式去記:「先假設傳入的 ab 原本在陣列的順序就是 ab,回傳正數代表兩個要交換,負數不換,0 代表兩個相等」
因此如果我現在有 2 跟 11 兩個數,我回傳 a - b 就是負數,就不會換,所以會由小排到大;回傳 b - a 就會是正數,兩個就會換,就變成由大排到小。
那為什麼當初 JavaScript 要如此設計呢?已經有人在推特上問過 Brendan Eich 了,連結在這:https://twitter.com/BrendanEich/status/930665293034283008
他的回覆是:
You mean the default sort function? It’s modeled on Perl 4 sort.
Presumption was JS would be used for perlish tasks & strings were likelier in arrays than numbers. (I think that’s the Perl rationale, but not sure.)
Picking a numeric sort function if the array contained only numbers required checking every element type. I had to pick a type!
我沒有看得很懂,但大意應該就是他在設計時參考了 Perl 4 的 sort,而且預設了 JS 會拿來做一些 Perl 相關的任務,以及陣列中字串應該會比數字更常出現。除此之外,如果要實作數字的排序,那還要先檢查陣列裡面的每個元素的資料型別才行。
總之呢,在使用 sort 時要注意這個狀況,在進行數字的比較時也要記得先確認資料型別,否則可能會寫出有 bug 的程式碼。
最後再提醒一個小地方,就是把數字轉字串的時候,結果可能會跟你想的有點不一樣。
console.log((12345678912345678).toString()) // 12345678912345678
console.log((1234567891234567812345).toString()) // 1.2345678912345677e+22
console.log((0.000001).toString()) // 0.000001
console.log((0.0000001).toString()) // 1e-7當你在轉一些比較大或比較小的數字的時候,會轉成科學記號的表示方式,在規格裡面有落落長的轉換規則(6.1.6.1.20 Number::toString, p.83):

案例三:浮點數精準度問題
這個應該就不少人都知道了,就是經典的 0.1 + 0.2 !== 0.3:
console.log(0.1 + 0.2 === 0.3) // false
console.log(0.1 + 0.2) // 0.30000000000000004如果你認為這是 JavaScript 獨有的問題,那你就錯了,這其實是許多程式語言共同的問題。而問題的根源其實跟我們開頭講的數字範圍問題差不多,儲存數字的空間是有限的,數字卻是無限的,因此沒有辦法精確地表達所有的數字。
而浮點數的問題還有一個,那就是會有無窮小數這種東西出現,例如說 1/3 = 0.3333....,在存成浮點數的時候,就會失去一些精度:
console.log((1/3).toFixed(30)) // 0.333333333333333314829616256247那實際上我們在寫程式的時候,到底該怎麼辦呢?
如果你沒有要做真的很精確的那種運算,只是想避免這種 0.1 + 0.2 !== 0.3 這種誤差的話,通常我們會抓一個合理的誤差值,意思就是我們不管是否相等了,而是把誤差考慮進去,只要誤差值在一定範圍內,就算它們相等,以 JavaScript 為例,就有提供一個 Number.EPSILON:
console.log(Math.abs(0.3 - (0.1 + 0.2))) // 5.551115123125783e-17
console.log(Math.abs(0.3 - (0.1 + 0.2)) < Number.EPSILON) // true不過 Number.EPSILON 的值是 2^-52,說實在的有點太小,如果你多做幾次浮點數的運算,其實很容易就會超過這個範圍:
console.log(Math.abs(3.3 - (1.1 + 1.1 + 1.1))) // 4.440892098500626e-16
console.log(Math.abs(3.3 - (1.1 + 1.1 + 1.1)) < Number.EPSILON) // false因此比較實際的做法是根據你的使用情境來決定這個誤差值是多少,例如說你拿來運算的輸入基本上都頂多到小數點後面第三位,例如說 1.283 或是 27.583 之類的,這時候你的誤差值挑個 1e-9 應該就滿夠的了。
但若是你需要精度更高的運算,就別用浮點數了,直接用其它套件會是更好的選擇,例如說 decimal.js 就是這樣的套件,而未來我們或許也有機會看到 JavaScript 原生支援這樣的功能。
關於浮點數的各種問題,如果你想知道各個程式語言是否有這個問題,可以參考這個網址就說明一切的網站:https://0.30000000000000004.com/
如果你想更進一步了解背後的原理以及更多案例,可以參考我從小看到大的這篇文章:使用浮點數最最基本的觀念,以及你所不知道的 C 語言: 浮點數運算。
案例四:不是數字的數字
不知道你有沒有在一些網站上面看過 NaN 這個字眼?
在 JavaScript 中,當你對數字做一些「不是數字」的操作時,就會產生一個叫做 NaN 的東西:
console.log(Number('abc')) // NaN
console.log(500/undefined) // NaNNaN 的全名為 Not a Number,中文直翻的話就會變成:「不是數字」,不過我建議大家不要這樣去記它,因為它其實比較像是「一個特殊的數字,用來表示不合法的數字」,因為 NaN 的型別也是 Number:
console.log(typeof NaN) // number而且它還有一個神奇的特性,那就是它是整個 JavaScript 的世界中,唯一自己不等於自己的值(題外話,你要自己用 Proxy 或是 Object.defineProperty 做出一個類似的也是可以啦):
console.log(NaN === NaN) // false但這個行為同樣也不是 JavaScript 自己發明的,而是前面提過的 IEEE 754 裡面所規定的,想知道原因的話可以去看:Why is NaN not equal to NaN? 底下的回答,最佳回答還有額外引用了一些 IEEE 754 成員的回答。
如果你要在 JavaScript 裡面偵測某個值是否是 NaN 的話,因為歷史包袱的關係,你有兩種方式:
console.log(isNaN(NaN)) // true
console.log(isNaN('abc')) // true
console.log(Number.isNaN(NaN)) // true
console.log(Number.isNaN('abc')) // false第一個 isNaN 是存在於 global 上面的函式,它的規格是這樣(19.2.3 isNaN. p.468):

簡單來說呢,如果傳進去的值不是數字,它會先轉換成數字型態,再來看是不是 NaN,所以傳入 "abc" 會先被轉成數字,就變成 NaN 了。
第二個則是 ES6 導入的 Number.isNaN,規格如下(21.1.2.4 Number.isNaN, p.508):

這邊先檢查型態是不是數字,不是的話直接回傳 false,是的話再來檢查是不是 NaN。
那如果版本太舊,沒有 Number.isNaN 的話,該怎麼實作它的 polyfill 呢?我們可以參考corejs 的實作,運用了「自己不等於自己」這個特性:
// `Number.isNaN` method
// https://tc39.es/ecma262/#sec-number.isnan
$({ target: 'Number', stat: true }, {
isNaN: function isNaN(number) {
// eslint-disable-next-line no-self-compare -- NaN check
return number != number;
}
});結語
在使用數字的時候,最常見的兩種錯誤大概就是沒注意到範圍跟型別,只要記住數字的儲存是有範圍的,未來就能避免自己寫出類似的 bug,在碰到浮點數跟大數的時候也要多加留意,小心提醒自己不要超出了範圍。
型別的話則是字串跟數字搞不清楚,導致相加或是比較的時候產生意料之外的結果,這些也都是自己應該注意到的部分,如果真的被型別搞得很亂,也可以考慮導入 TypeScript 之類的,在編譯時就會提醒你型別有問題。至於 Array.prototype.sort 的問題,大概每個新手都會踩到過一次,畢竟是真的滿違反直覺的。
最後,這篇其實只提到一些比較粗淺的部分,並沒有涉及更多 Number 相關的知識,例如說 0 其實有 +0 跟 -0,無限大也有分正無限大跟負無限大,也沒有講到背後的原理,例如說:
Number.MAX_SAFE_INTEGER怎麼計算出來的?Number.MAX_VALUE怎麼來的?- 浮點數誤差的詳細原理是什麼?在系統內是怎麼被儲存的?
上面這些就要去看 IEEE 754 才能講得清楚,有些我自己也沒有弄得太懂,未來有機會的話再跟大家介紹。
評論