前言
前陣子看到了這個寫得很棒又很漂亮的教學:Regular Expressions for Regular Folk,再加上之前一直沒有在自己的課程裡面教到 Reglar Expresioon,可是這在開發上又滿常見,於是決定寫一篇文章簡單講一下這個主題。
因此呢,這篇是給完全不懂這是什麼的初學者看的,所以會講得滿淺的,會帶到的例子應該也都是相對簡單的東西,模式也比較固定,需要考慮的邊界條件少很多,學習起來我認為也會比較容易。
好,接下來就開始吧!
什麼是 Regular Expression?
要談這個主題的話,我覺得舉例是最棒的,因此底下我會直接舉幾個相關的例子,先帶你了解 Regular Expression 到底是用來做什麼的。
第一個例子:尋找資料
假設你今天想要在一個 Excel 試算表裡面尋找資料,那裡面全部都是人名,而你想要找姓「李」的出來,你可能會打開搜尋介面,然後輸入「李」。但這個方法並不是很好,因為不只姓李的會被找出來,只要名字裡面有「李」這個字的都會,所以找出來的資料還要再經過人工篩選一遍。
那該怎麼辦呢?有些搜尋介面可能會有一些選項讓你選,例如說「符合開頭」之類的,如果有的話那就沒問題了,你可以輕鬆的找到姓李的人,但如果是更複雜的例子呢?例如說你想要找「李X明」,符合這個規則的都找出來,這可能很多系統就做不到了,因為沒有提供這種功能。
就算有好了,但是規則可能不太一樣,例如說 A 公司的系統可能要輸入:李%明,B 公司要輸入:李*明。
有沒有一個「通用的規則」,讓我們可以很方便地把這些需求轉成符號跟文字呢?
第二個例子:驗證資料
台灣的手機號碼目前基本上都符合一定的格式,那就是總共十碼,前兩碼是 09,例如說 0912-345-678 或是 0900-111-222 之類的。如果今天有一個字串,我們要驗證他是不是符合台灣的手機號碼格式,可以利用以下三條規則:
- 一共有 10 位數
- 開頭要是 09
- 每一個字元都要是數字
只要符合這三條規則,就可以說它符合格式(但號碼不一定真實存在)。
那如果用程式碼來寫的話該怎麼寫呢?或許可以這樣寫:
function isTaiwanMobilePhone(phone) {
if (phone.length !== 10) return false
if (phone.indexOf('09') !== 0) return false
for(let digit of phone) {
if (!Number.isInteger(Number(digit))) {
return false
}
}
return true
}其實就只是把上面的文字轉換成程式碼的形式而已。
可是像這種格式相關的驗證其實有很多很多,例如說:
- 驗證家用電話
- 驗證電子郵件
- 驗證網址
而這些的本質其實都是一樣的,都是某一種格式而已,只是目前的我們只能用文字來表示這些格式以及規則。
有沒有可能有一種方法,讓我們能夠很方便地把這些需求轉成符號跟文字呢?如果可以的話,那就方便太多了。
第三個例子:抽取資料
假設我今天有一大堆的 email,每個 email 都是一行,像是以下的形式:
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]但我其實一點都不關心那些帳號是什麼,我關心的是這是哪一家的信箱,所以我想要把這些 email 的網域抽出來,而且更進一步把 .com 或是其他結尾去掉,想要讓我的資料變成這樣:
gmail
gmail
yahoo
msn
ptt如果用程式的話可以怎麼做呢?因為每一行要做的處理都是一模一樣的,所以我們示範處理一筆資料就好,要改成多筆就只是用迴圈去跑,然後把每一筆資料都餵進來而已:
let email = '[email protected]'
let temp = email.split('@') // 先用 @ 來分割
let domain = temp[1] // 去掉帳號,只拿後面的 domain
let temp2 = domain.split('.') // 把 domain 用點切割
console.log(temp2[0]) // 拿第一個,就會是 gmail(附註:真實的需求跟網域可能會更複雜,這邊只是簡單示範一下概念而已)
不含第一行的資料跟最後一行的輸出,我們一共用了三個步驟,搭配字串相關的方法來處理這個需求。如果把上面的需求用白話文說,其實就是:「我只要從 @ 一直到後面第一個 . 這一段的文字」。
那有沒有可能把這個規則寫成某一種形式,可以快速地表達出這個需求?
好,不用再賣關子了,相信大家都知道答案是什麼。
有,以上三個問題都有解答,而且答案是同樣的,就是我們的主題:Regular Expression,中文又翻作:「正規表達式」,有時候又會簡寫成 regex 或是 regexp 之類的,都是在講同一個東西。
仔細想想就會發現,這幾個問題的本質其實都是一樣的,就是想要尋找「符合某個特定規則」的字串出來。
第一個範例想要找的是「李X明」
第二個範例想要找的是「09xxxxxxxx」
第三個範例想要找的是「xxx@ooo.xxx」,並且只想要 ooo 的部分
而 Regular Expression(以下簡稱 RE) 其實就只是把這些規則用特定的格式轉換成符號而已。之所以需要學這一套,是因為它應用最廣泛,幾乎每個程式語言都有支援,有些編輯器或是網頁甚至也有!
初探 Regular Expression
前面已經提過了,RE 其實就是用一連串的符號來表示想比對的規則,一般來說在寫 RE 的時候,會用 // 把你想表達的規則包住,最簡單的規則就是直接把你想比對的字放進去,例如說:/xyz/,就是在判斷一個字串有沒有包含「xyz」這連續的三個字:
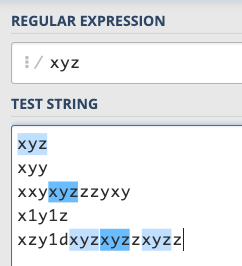
截圖的這個網站叫做 RegEx101,可以在上面提供你的 RE 以及要比對的字串,會自動幫你比對並顯示相關資訊,上圖藍色的就是比對到的部分。
所以你可以用 /xyz/ 來找出一個字串有沒有包含 xyz,還可以知道 xyz 出現在哪一個位置。
不過這樣子的功能當然沒辦法滿足我們的需求,所以接著要來看一個很強大的符號:[],中括號裡面可以放一大堆東西,只要有一個字符合就是符合,例如說:/[aeiou]/就是在比對一個字串是否包含任意一個母音:
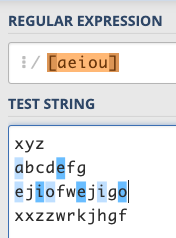
既然可以放一大堆字,那當然也能這樣放:/[0123456789]/,就可以比對數字了!那字母呢?難道說要 /[abcdefghijklmnopqrstuvwxyz]/ 嗎?這樣未免也太長了。
針對這種「連續」的東西,可以用-來表示,例如說:/[0-9]/ 跟 /[a-z]/ 就分別是數字跟小寫字母了:
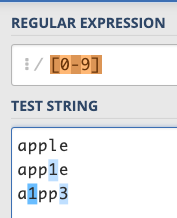
如果是大寫字母的話可以用 /[A-Z]/,而且這些規則可以合併使用,例如說:/[0-9a-z]/,就可以比對到「數字或小寫字母」,而/0-9a-zA-Z/ 就是一般常見的「數字或英文字母」。
不過這邊要再強調一次,[]這個東西只會比對到「一個字」,所以只要有一個字符合,就是符合這個規則。
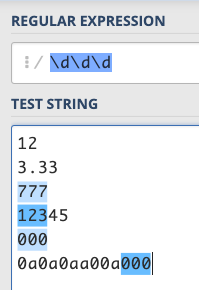
再來呢,如果每次比對數字或字母都要輸入這麼多字的話顯然很浪費時間,所以針對這些常出現的規則,有提供更方便的方法。這些規則通常都會以\ 開頭,例如說 /\d/,其實就是 /[0-9]/ 的意思(d 就是 digit),\d 就表示一個數字,所以如果我打:/\d\d\d/ 就是要比對三個數字:
還有另外一個常用的是 \w(w 應該是 word 的意思),會比對數字、英文大小寫字母還有底線,換句話說,其實/\w/ 就等於 /[a-zA-Z0-9_]/。
最後還有一個神奇的符號,就是一個點:/./,點就是「任意字元」的意思,可以比對到任何一個字。
綜合以上所述,大家可以想想看以下哪些字串可以配對到這個 RE:/\w\w\w.\d\d\d/。
- 000000
- 9999999
- aaaaaaa
- 0a0a000
- 0a0a0a0
- cc3c777
- cccc777
答案:
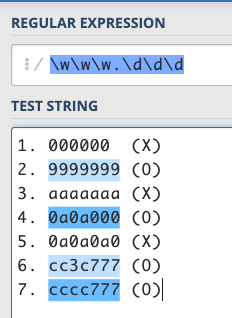
看到這邊,如果你想比對一個「固定長度」而且模式較為簡單的東西的話,應該已經難不倒你了,因為你已經可以利用[]、.、\d、\w這幾個符號去湊出想要的模式。
例如說前面提過的手機號碼:
- 一共有 10 位數
- 開頭要是 09
- 每一個字元都要是數字
不就是 /09\d\d\d\d\d\d\d\d/ 嗎?
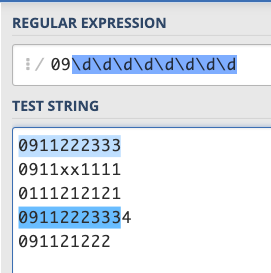
咦…不對啊,為什麼 09112223334 這個有 11 位數的也被比對到了?
這是因為正規表達式所配對的是「部分」的字串,只要你整個字串裡面有一部分符合,就會被配對到。所以如果你想要用上面那個正規表達式來檢測一個字串是不是手機號碼的話,是行不通的,你還需要兩個東西。
第一個叫做:^,這是字串開頭的意思;第二個叫做:$,這是字串結尾的意思。簡單來說呢,/xyz/會配對到任何「有包含 xyz 三個字」的字串,像是 AxyzB 或是 xyzAB 都可以,然後 /^xyz/ 則是任何「開頭是 xyz」的字串,例如說 xyzAB 或是 xyz。
所以如果你要比對手機號碼,就可以把這兩個符號加上去,變成 /^09\d\d\d\d\d\d\d\d$/,就大功告成了。
實際使用 Regular Expression
雖然我們的確把手機號碼的 RE 寫出來了沒錯,但你沒有覺得很奇怪嗎?
平常我們寫程式的時候,只要是重複的東西都可以透過迴圈或是函式來做簡化,那正規表達式應該也有「重複」的符號吧?
有,在你想要重複的後面加上 {} 就好,例如說 /^09\d{8}$/ 就代表 \d 會重複八次,就不用自己再寫那麼多了。
重複次數的話還有幾種不同的用法,例如說剛剛用的 {8} 代表一定要 8 個,而 {8,10} 則是 8~10 個都可以,{8,} 的話則是「8 以上」的意思。
講了這麼多,都只是紙上談兵,我們立刻來實驗看看,這邊用 JS 來做示範:
var re = /^09\d{8}$/
console.log(re.test("0911222333")) // true
console.log(re.test("1911222333")) // false
console.log(re.test("09112223332")) // false
console.log(re.test("091222333")) // false在 JS 裡面,只要你依照我們前面講的格式,把 RE 用 // 包起來,就自動會變成一個 RegExp 的物件,而你可以用它的 test 這個方法來跟字串做比對。
如果你不喜歡用 // 的話,用 new RegExp 也是可以的,只是要特別注意在字串中要把 \d 改成 \\d,不然的話會被當作跳脫字元來看待:
var re = new RegExp('^09\d{8}$') // => /^09d{8}$/
var re = new RegExp('^09\\d{8}$') // => /^09\d{8}$/所以呢,若是你想要驗證某個字串是不是符合 RE,用 test 方法就對了。那如果是想要找配對的呢?
例如說我們前面講的例子:李X明,寫成 RE 就會變成:/李.明/。
如果要找配對到的字的話,方法不太一樣。剛剛在測試的時候我們是:RE.test(字串),要配對的話要反過來,變成:字串.match(RE),意思就是拿 RE 去跟字串做比對,主體不太一樣。
var re = /李.明/
var str = '李曉明王阿明王小明李大明太大明阿明無名小站'
console.log(str.match(re))
/*
輸出:
0: "李曉明"
groups: undefined
index: 0
input: "李曉明王阿明王小明李大明太大明阿明無名小站"
*/如果有配對到的話,返回值會是一個陣列,否則的話會是 null。可是以上這個方法我只能配對到一個,如果我想配對到全部的呢?可以使用 matchAll:
var re = /李.明/
var str = '李曉明王阿明王小明李大明太大明阿明無名小站'
console.log(str.matchAll(re))
/*
輸出:Uncaught TypeError: String.prototype.matchAll called with a non-global RegExp argument
*/出現了一個 non-global RegExp argument 的錯誤訊息,這是什麼意思呢?
正規表達式除了那些配對用的符號以外,還有一些標誌(flag,或你也可以簡單想成是參數)可以設置,例如說 /xyz/ 只會配對到小寫 xyz,但如果你加上一個 i(我猜是 ignore case 的意思),變成 /xyz/i,就會忽略大小寫。
加在 / 後面的那個就是 flag,要加多個的話就繼續加上去就好了,而 g 這個 flag 代表 global,就是「我全都要」的意思,會配對到多個字串,所以上面的範例要加上 g,變成:
var re = /李.明/g
var str = '李曉明王阿明王小明李大明太大明阿明無名小站'
var result = str.matchAll(re)
console.log(result) // RegExpStringIterator
console.log(...result)
使用 matchAll 以後會返回一個 Iterator,你可以用 for...of 去把值取出來,或者是用 [...result] 把它轉為一個陣列,就可以看到所有的結果。
如此一來呢,我們前面提到的三個問題,有兩個問題都被解掉了,現在只剩下最後一個了,那就是:比對「xxx@ooo.xxx」,並且只想要 ooo 的部分。
這個模式的難點有兩個:
- ooo 是不固定的字數
- 要取的是某個部份,而不是整個 pattern
前面我們已經講過 {8} 可以用來指定次數了,那如果是不固定的次數怎麼辦呢?一樣有一個符號幫我們做這件事,就是+,他的意思是:「一個以上」,所以/^A\d+Z$/ 就會配對到任何開頭是 A,結尾是 Z,中間有一個以上的數字的字串:
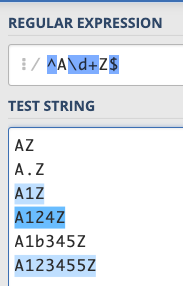
再來有一組神奇的符號,叫做 (),就是大家最常見的小括號,專有名詞叫做 Capturing Groups。這是做什麼用的呢?就是把這裡面符合的模式抓出來的意思。
像是我們可以把剛剛的/^A\d+Z$/改掉,在中間數字的部分加上括號,就變成: /^A(\d+)Z$/,乍看之下沒什麼差,但我們可以用 match 跑跑看:
var re = /^A(\d+)Z$/
console.log('A12345Z'.match(re))
/*
0: "A12345Z"
1: "12345"
groups: undefined
index: 0
input: "A12345Z"
length: 2
*/原本 match 的時候陣列只會有一筆資料,但現在又多一組了,而那一組就是我們用 () 框起來的部分,代表:「我想要知道這裡面配對到的東西」。
有了兩大神器 + 跟 () 以後,就可以來試著解決前面提到的問題了:
我們可以先配對字串開頭:/^/
接著加上前面帳號跟 @:/^.+@/
然後配對後面的 domain 並且記起來:/^.+@(.+)/
最後再以 . 做結尾,記得做跳脫,前面要加個 \:/^.+@(.+)\./
下圖中綠色就是我們 () 記起來的部分:
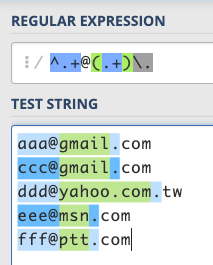
除了 yahoo.com.tw 那個以外,其他的都成功了!
那 yahoo.com.tw 為什麼會失敗呢?因為你會發現以我們的規則來說,其實以下兩個狀態都符合:
(.+)\.前面記憶的部分配對到yahoo.com,後面.配對到.tw開頭的點(.+)\.前面記憶的部分配對到yahoo,後面.配對到.com開頭的點
第一種狀況是(.+)的部分盡量配對越多越好,第二種則是相反,配對越少越好。
而以我們寫出來的 RE 來說,其實會屬於第一種,也就是配對越多越好,所以才會變成 yahoo.com 而不是我們所期待的 yahoo。
那如果想要變成第二種:配對越少越好,這應該怎麼辦呢?很簡單,+ 後面加一個 ? 就好:
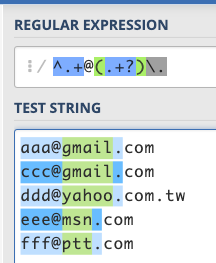
寫成程式碼的話就會變這樣:
var emails = [
'[email protected]',
'[email protected]',
'[email protected]',
'[email protected]',
'[email protected]'
]
var re = /^.+@(.+?)\./
for(let email of emails) {
var result = email.match(re)
console.log(result[1])
}
/*
gmail
gmail
yahoo
msn
ptt
*/做到這邊,我們開頭談的三個情境都已經用 Regular Expression 完美地解決了!
總結
這篇主要的目的就只想簡單講一下 Regular Expression 這東西,所以帶到的範例相對簡單,然後講到的東西也不多。
這邊稍微提一下一些基本的但我沒講到的,例如說原本 \d 是配對數字,如果把 d 變成大寫,就會變成反義,所以 \D 代表:不是數字,而 \W 也一樣,代表:不是「英文大小寫字母與數字與底線」。
再來就是 + 前面有提過是一個以上,如果你想要零個以上,可以用 *,然後還有一個特殊的字 \s 可以配對到任何空白(空白字元、tab 以及換行)。
正規表達式如果要寫到超級複雜的話可以變很複雜,規則也超級多,但一般來說基本的應該就滿夠用了。
最後再次推薦開頭的教學:Regular Expressions for Regular Folk,網頁很漂亮,提供的範例也都很實際,很推薦大家參考看看。
評論