Introduction
Recently, I came across a great tutorial on Regular Expressions for Regular Folk, which is well-written and beautifully designed. Since Regular Expressions are commonly used in development, but not covered in my course, I decided to write a simple article on this topic.
This article is intended for beginners who have no idea what Regular Expressions are. Therefore, the explanations will be relatively simple, and the examples will be relatively easy to understand. The patterns will also be relatively fixed, with fewer boundary conditions to consider, making it easier to learn.
Alright, let’s get started!
What are Regular Expressions?
To discuss this topic, I think examples are the best way to explain. Therefore, I will provide several related examples to help you understand what Regular Expressions are used for.
Example 1: Finding Data
Suppose you want to find data in an Excel spreadsheet that contains only names, and you want to find all the people with the surname “Li”. You might open the search interface and enter “Li”. However, this method is not very effective because it will find not only people with the surname Li, but also anyone with the character “Li” in their name. Therefore, the data found needs to be manually filtered again.
What should you do? Some search interfaces may have some options for you to choose from, such as “match at the beginning”. If so, then there is no problem, and you can easily find people with the surname Li. But what if it’s a more complex example? For example, you want to find “Li X Ming”, and all the names that match this rule. Many systems may not be able to do this because this feature is not provided.
Even if it is available, the rules may be different. For example, Company A’s system may require inputting: Li% Ming, while Company B’s system may require inputting: Li* Ming.
Is there a “universal rule” that allows us to easily convert these requirements into symbols and text?
Example 2: Data Validation
Currently, most mobile phone numbers in Taiwan follow a certain format, which is a total of ten digits, with the first two digits being 09, such as 0912-345-678 or 0900-111-222. If we have a string and want to verify that it meets the format of a Taiwanese mobile phone number, we can use the following three rules:
- There are a total of 10 digits.
- The beginning must be 09.
- Each character must be a number.
As long as these three rules are met, it can be said that it meets the format (but the number may not actually exist).
How should we write the code for this? Perhaps we can write it like this:
function isTaiwanMobilePhone(phone) {
if (phone.length !== 10) return false
if (phone.indexOf('09') !== 0) return false
for(let digit of phone) {
if (!Number.isInteger(Number(digit))) {
return false
}
}
return true
}Actually, it’s just converting the above text into code.
However, there are many, many format-related validations, such as:
- Validating home phone numbers
- Validating email addresses
- Validating URLs
The essence of these is actually the same, which is a certain format, but currently, we can only use text to represent these formats and rules.
Is there a way to convert these requirements into symbols and text easily? If so, it would be much more convenient.
Example 3: Extracting Data
Suppose I have a lot of emails, each email is one line, in the following format:
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]But I don’t care what the account is, I care which company’s mailbox it is, so I want to extract the domains of these emails, and further remove the “.com” or other endings, so that my data becomes like this:
gmail
gmail
yahoo
msn
pttHow can we do this with code? Because the processing to be done for each line is exactly the same, we only need to demonstrate the processing of one piece of data. If we want to change it to multiple pieces, we just use a loop to run it, and feed each piece of data into it:
let email = '[email protected]'
let temp = email.split('@') // 先用 @ 來分割
let domain = temp[1] // 去掉帳號,只拿後面的 domain
let temp2 = domain.split('.') // 把 domain 用點切割
console.log(temp2[0]) // 拿第一個,就會是 gmail(Note: The real requirements and domains may be more complex. Here, we just demonstrate the concept simply.)
Excluding the data without the first line and the output of the last line, we used three steps in total, combined with string-related methods to process this requirement. If we express the above requirement in plain language, it is actually: “I only need the text from @ to the first . after it.”
Is it possible to write this rule in a certain form, so that we can quickly express this requirement?
Well, there’s no need to keep you in suspense anymore. I believe you all know the answer.
Yes, all three problems have solutions, and the answer is the same: our topic, Regular Expressions, which is also known as “正規表達式” in Chinese, and sometimes abbreviated as regex or regexp, etc., all referring to the same thing.
Upon careful consideration, we will find that the essence of these problems is actually the same, which is to find “strings that meet certain specific rules”.
The first example is looking for “Li X Ming”.
The second example is looking for “09xxxxxxxx”.
The third example is looking for “xxx@ooo.xxx“, and only wants the ooo part.
Regular Expression (RE) is just a set of rules expressed in a specific format using symbols. The reason for learning this is that it is the most widely used and supported by almost every programming language, and some editors or web pages even have it!
Exploring Regular Expression
As mentioned earlier, RE is actually a set of symbols used to represent the rules you want to match. Generally, when writing RE, you will use // to wrap the rules you want to express. The simplest rule is to directly put the word you want to match in it, for example: /xyz/, which is to determine whether a string contains the continuous three words “xyz”:
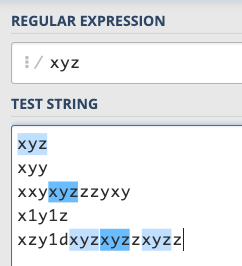
The screenshot of this website is called RegEx101, where you can provide your RE and the string you want to match, and it will automatically help you match and display relevant information. The blue part in the above picture is the part that matches.
So you can use /xyz/ to find out if a string contains xyz, and you can also know where xyz appears.
However, this function cannot meet our needs, so let’s take a look at a powerful symbol: []. You can put a lot of things in the brackets, as long as one character matches, it is a match. For example: /[aeiou]/ is to match whether a string contains any vowels:
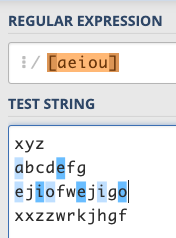
Since you can put a lot of words, you can also put them like this: /[0123456789]/, and you can match numbers! What about letters? Do you have to use /[abcdefghijklmnopqrstuvwxyz]/? This is too long.
For this kind of “continuous” thing, you can use - to represent it. For example: /[0-9]/ and /[a-z]/ are numbers and lowercase letters respectively:
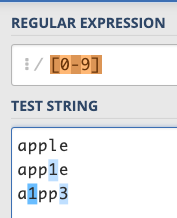
If it is uppercase letters, you can use /[A-Z]/, and these rules can be used in combination. For example: /[0-9a-z]/ can match “numbers or lowercase letters”, and /0-9a-zA-Z/ is the commonly used “numbers or English letters”.
However, it should be emphasized here again that [] only matches “one word”, so as long as one character matches, it meets this rule.
Next, if you have to enter so many words every time you match numbers or letters, it is obviously a waste of time. Therefore, for these commonly used rules, there are more convenient methods. These rules usually start with \, for example, \d actually means /[0-9]/ (d is digit), and \d represents a number, so if I type: /\d\d\d/, it is to match three numbers:
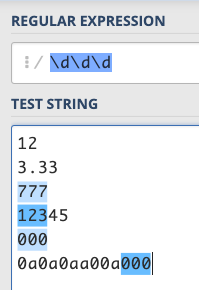
There is also another commonly used one, which is \w (w should mean word), which matches numbers, English uppercase and lowercase letters, and underscores. In other words, / \w / is equivalent to /[a-zA-Z0-9_]/.
Finally, there is a magical symbol, which is a dot: /. /, which means “any character” and can match any word.
Based on the above, you can think about which strings can match this RE: / \w\w\w. \d\d\d /.
- 000000
- 9999999
- aaaaaaa
- 0a0a000
- 0a0a0a0
- cc3c777
- cccc777
Answer:
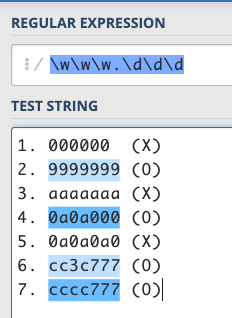
By this point, if you want to match something with a “fixed length” and a simpler pattern, you should not be difficult, because you can use [], ., \d, and \w to match the desired pattern.
For example, the mobile phone number mentioned earlier:
- There are a total of 10 digits
- The beginning must be 09
- Each character must be a number
Isn’t it /09\d\d\d\d\d\d\d\d/?
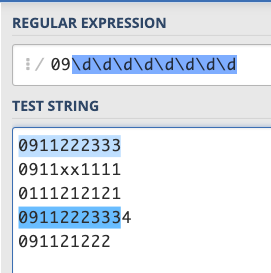
Huh…no, why is 09112223334, which has 11 digits, also matched?
This is because the regular expression matches only “part” of the string. As long as a part of the entire string matches, it will be matched. So if you want to use the above regular expression to check if a string is a mobile phone number, it won’t work, you still need two things.
The first is called: ^, which means the beginning of the string; the second is called: $, which means the end of the string. Simply put, /xyz/ will match any string that “contains the three words xyz”, such as AxyzB or xyzAB. Then /^xyz/ is any string that “starts with xyz”, such as xyzAB or xyz.
So if you want to match a mobile phone number, you can add these two symbols, /^09\d\d\d\d\d\d\d\d$/, and you’re done.
Practical Use of Regular Expression
Although we have indeed written the RE for phone numbers correctly, don’t you find it strange?
Usually, when we write programs, anything that is repeated can be simplified by loops or functions. Regular expressions should also have “repeating” symbols, right?
Yes, you can add {} after what you want to repeat, for example, /^09\d{8}$/ means that \d will be repeated eight times, so you don’t have to write so much.
There are several different ways to repeat times. For example, the {8} used just now means that there must be 8, while {8,10} means that 8 to 10 are all possible, and {8,} means “8 or more”.
After talking so much, it’s just talk on paper. Let’s experiment immediately. Here we use JS for demonstration:
var re = /^09\d{8}$/
console.log(re.test("0911222333")) // true
console.log(re.test("1911222333")) // false
console.log(re.test("09112223332")) // false
console.log(re.test("091222333")) // falseIn JS, as long as you wrap the RE with // according to the format we mentioned earlier, it will automatically become a RegExp object, and you can use its test method to compare with the string.
If you don’t like to use //, using new RegExp is also possible, but you need to pay special attention to changing \d to \\d in the string, otherwise it will be treated as an escape character:
var re = new RegExp('^09\d{8}$') // => /^09d{8}$/
var re = new RegExp('^09\\d{8}$') // => /^09\d{8}$/So, if you want to verify whether a string conforms to RE, use the test method. What if you want to find a match?
For example, the example we mentioned earlier: 李X明, written as RE will become: /李.明/.
If you want to find the matched words, the method is different. When testing just now, we used RE.test(string). To match, you need to reverse it and become: string.match(RE), which means using RE to compare with the string, and the subject is different.
var re = /李.明/
var str = '李曉明王阿明王小明李大明太大明阿明無名小站'
console.log(str.match(re))
/*
輸出:
0: "李曉明"
groups: undefined
index: 0
input: "李曉明王阿明王小明李大明太大明阿明無名小站"
*/If there is a match, the return value will be an array, otherwise it will be null. But with this method, I can only match one. What if I want to match all of them? You can use matchAll:
var re = /李.明/
var str = '李曉明王阿明王小明李大明太大明阿明無名小站'
console.log(str.matchAll(re))
/*
輸出:Uncaught TypeError: String.prototype.matchAll called with a non-global RegExp argument
*/An error message non-global RegExp argument appeared. What does this mean?
In addition to the matching symbols, regular expressions also have some flags (or you can simply think of them as parameters) that can be set. For example, /xyz/ will only match lowercase xyz, but if you add an i (I guess it means ignore case), it becomes /xyz/i, which will ignore case.
The one added after / is the flag. If you want to add multiple flags, just continue to add them. The g flag means global, which means “I want them all” and will match multiple strings. Therefore, the above example needs to add g, becoming:
var re = /李.明/g
var str = '李曉明王阿明王小明李大明太大明阿明無名小站'
var result = str.matchAll(re)
console.log(result) // RegExpStringIterator
console.log(...result)
After using matchAll, it will return an Iterator, and you can use for...of to extract the values, or use [...result] to convert it to an array, and you can see all the results.
In this way, two of the three problems mentioned earlier have been solved, and only the last one is left: matching “xxx@ooo.xxx“ and only wanting the ooo part.
There are two difficulties in this pattern:
- ooo is an indefinite number of words
- You want to take a part, not the entire pattern
We have already mentioned that {8} can be used to specify the number of times. What if the number of times is not fixed? There is also a symbol to help us do this, which is +, which means “one or more”, so /^A\d+Z$/ will match any string that starts with A, ends with Z, and has one or more numbers in between:
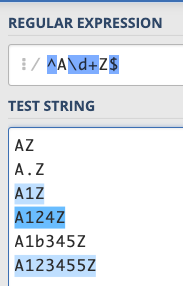
Then there is a group of magical symbols called (), which is the most common parentheses, and the technical term is Capturing Groups. What is it used for? It means to extract the pattern that matches inside here.
For example, we can change the /^A\d+Z$/ just now, add parentheses in the middle of the number, and become: /^A(\d+)Z$/. At first glance, there is not much difference, but we can use match to test it:
var re = /^A(\d+)Z$/
console.log('A12345Z'.match(re))
/*
0: "A12345Z"
1: "12345"
groups: undefined
index: 0
input: "A12345Z"
length: 2
*/Originally, when matching, there would only be one set of data in the array, but now there is one more set, and that set is the part we framed with (), which means: “I want to know what is matched inside here.”
With the two great tools + and (), we can try to solve the problem mentioned earlier:
We can first match the beginning of the string: /^/
Then add the account and @ in front: /^.+@/
Then match the domain behind and remember it: /^.+@(.+)/
Finally, end with a period, remember to escape the front with \: /^.+@(.+)\./
The green part in the following figure is what we have marked with ():
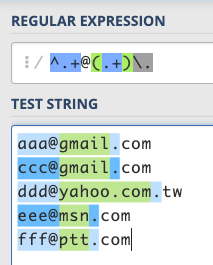
Except for yahoo.com.tw, all the others have succeeded!
Why did yahoo.com.tw fail? Because you will find that according to our rules, the following two states actually meet:
- The part memorized before
(.+)matchesyahoo.com, and the.after it matches the dot at the beginning of.tw. - The part memorized before
(.+)matchesyahoo, and the.after it matches the dot at the beginning of.com.
The first case is that the (.+) part should match as much as possible, while the second case is the opposite, and the less matching, the better.
And for the RE we wrote, it actually belongs to the first case, that is, the more matching, the better, so it becomes yahoo.com instead of the yahoo we expected.
So, if you want to become the second case: the less matching, the better, what should you do? It’s simple, just add a ? after the +:
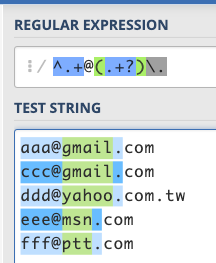
If written in code, it will look like this:
var emails = [
'[email protected]',
'[email protected]',
'[email protected]',
'[email protected]',
'[email protected]'
]
var re = /^.+@(.+?)\./
for(let email of emails) {
var result = email.match(re)
console.log(result[1])
}
/*
gmail
gmail
yahoo
msn
ptt
*/By this point, we have perfectly solved the three situations mentioned at the beginning using Regular Expression!
Summary
The main purpose of this article is to simply talk about Regular Expression, so the examples brought are relatively simple, and not much is mentioned.
Here, I will briefly mention some basic things that I did not mention, such as originally \d matches numbers. If you change d to uppercase, it becomes the opposite, so \D means: not a number, and \W is the same, meaning: not “English uppercase and lowercase letters, numbers, and underscores”.
Next is the + mentioned earlier, which means one or more. If you want zero or more, you can use *, and then there is a special word \s that can match any whitespace (whitespace, tab, and line break).
If you want to write regular expressions to be super complex, it can become very complicated, and there are many rules, but generally, the basics should be enough.
Finally, I recommend the tutorial at the beginning again: Regular Expressions for Regular Folk, the webpage is beautiful, and the examples provided are very practical. I highly recommend everyone to refer to it.
Comments