簡介
近幾年前端框架大放異彩,許多新手才學沒多久的 JavaScript,就直接學習三大框架了(雖然 React 不是框架,但整個生態系其實就跟框架沒兩樣,因此我覺得歸類在框架也不是不行)。
而這三大框架通常都是拿來寫 SPA(Single Page Application)用的,我一直認為在學習這些框架前應該要具備一些基礎知識,尤其是對於前後端的理解,否則一定會遇到很多不知道從何解起的問題。
因此,本文舉出一個我自己曾經碰過,學生也常常跑來問我的問題當作範例,大家也可以先想一下自己能不能回答出這個問題:
假設今天我有個 SPA,搭配某些 router 的 library 來實作路由,所以
/list會連到列表頁,/about會到關於我的頁面。可是奇怪了,當我把 SPA 上傳到 GitHub Pages 之後,首頁是好的,我從首頁進去
/list也是好的,可是當我在/list重新整理的時候,卻顯示 404 not found,這是為什麼呢?
要回答這個問題,必須先來複習一下前後端相關的網路基礎知識。
動態網頁與靜態網頁
先想一下,你認知中的動態網頁與靜態網頁是什麼?它們的區別又在哪裡?
當我們在講到動態與靜態時,其實所談到的東西並不是「網頁上的內容」會不會變。而是指「我所請求的網頁是否有被 Server 『處理』過」。這樣定義可能不太精確,但我接下來舉幾個例子你就會懂了。
先舉個最簡單的例子,假設現在有個檔案叫做 a.php,程式碼長這樣:
<?php
echo "hello!";
?>今天如果我造訪 a.php,看到的內容就是:
<?php
echo "hello!";
?>就代表什麼?代表這是個「靜態網頁」,Server 並沒有透過 PHP 相關的程式去處理這隻檔案,而是把這個 a.php 當作「檔案」給傳回來,就是一般俗稱的 static file。
若是我們今天看到的內容是:
hello!就代表 Server 把這個 a.php 給執行了,並且把輸出的結果當作 Response 回傳,這樣的網頁就叫做「動態網頁」,雖然內容沒有變,但它確實是動態網頁。
這就是動態跟靜態的區別,事實上跟你看到的內容會不會改變一點關係都沒有。靜態的會把請求的資源直接當作檔案回傳,動態的則是會在 Server 處理過後才把結果當成 Response 回傳。
為了確保你有完全理解這個概念,我們來看底下這個範例,index.html:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
</head>
<body>
</body>
<script>
document.writeln(new Date())
</script>
</html>請問這是一個動態還是靜態網頁?
答案是靜態。因為這就是一個靜態的 HTML 檔案,沒有被 Server 特殊處理就直接傳到 Client 端,Client 端看到的就是存放在 Server 的檔案內容。雖然畫面上的資訊會改變沒錯,但我前面說過了,這並不是區分動態或靜態的標準。
談完了動態與靜態之後,我們來談談 Server 處理請求的方式。
Server 與路徑
最常看到的一種網址是什麼?是像檔案那樣子的,例如說 GitHub Pages:http://aszx87410.github.io/mars-lang-chrome-extension/index.html,後半段的 mars-lang-chrome-extension/index.html 就代表在 mars-lang-chrome-extension 這個資料夾底下有 index.html 這個檔案。
這邊的網址某種程度上就反映了真實的檔案路徑,所以存取任何一個頁面就跟存取檔案差不多。但這些其實都是可以透過 Server 更改設定的!
意思是說,如果我想要的話,我可以讓 https://huli.tw/123 輸出我 Server 上面位於 /data/test.html 的這個檔案,這些都是可以調整的。
所以網址跟真實的檔案路徑可以類似,也可以完全不同,這些都可以在 Server 調整。一般來說最常見的跟檔案相關的 Server 其實有兩種。
第一種就是「完全靜態」的 static file server,指的就是無論任何檔案都不會經過處理,然後會對應到檔案路徑,是什麼檔案就輸出什麼內容。
最經典的範例就是 GitHub Pages,無論你放 PHP、Ruby 還是 JavaScript,它都只會把「檔案內容」一五一十的輸出給你,而不會去執行那個腳本。所以你沒辦法在 GitHub Pages 上面跑任何跟 Server 有關的東西,你沒辦法跑 PHP,沒辦法跑 Rails 也沒辦法跑 Express,因為它不會幫你做任何處理,只會把檔案內容回傳。
第二種則是經典的 Apache Server,通常都是搭配 PHP 來做使用,它會幫你把 PHP 檔案執行過後才把結果回傳;PHP 以外的檔案則是當作靜態檔案,就跟 GitHub Pages 一樣。
回到我們開頭的例子,如果你有個檔案叫做 a.php,內容是:
<?php
echo "hello!";
?>若是你把這個檔案放上去 GitHub Pages,你只會看到上面那樣的內容,因為它就只是個檔案。
但如果你把這檔案放到設置好 Apache + PHP 的 Server,你會看到 hello!,因為 Server 先執行過這個 PHP 才把結果輸出。
好,有了這些基礎之後,我們自然可以來解決第一個問題。
假設今天我有個 SPA,搭配某些 router 的 library 來實作路由,所以
/list會連到列表頁,/about會到關於我的頁面。可是奇怪了,當我把 SPA 上傳到 GitHub Pages 之後,首頁是好的,我從首頁進去
/list也是好的,可是當我在/list重新整理的時候,卻顯示 404 not found,這是為什麼呢?
前面有提到過 GitHub Pages 是完全靜態的 Server,而且網址對應到了真實的檔案路徑,所以當你存取根目錄 / 時,預設的設定本來就會去找 /index.html,因此可以正常存取檔案。
但是當你造訪 /list 時,你的 GitHub 上又沒有 /list/index.html,所以當然顯示 404 not found 了,不是很合理嗎?
這時候你一定會問:
那為什麼我從首頁進去再進到列表頁就沒問題?
要回答這個問題,就要來看 SPA 的路由到底是怎麼實現的了。
SPA 的 router 實現
還記得 SPA 的定義嗎?Single Page,就代表它永不換頁,永遠都在同一頁上面。
可是如果不能換頁,那網址不就是同一個了嗎?這樣不是很不方便嗎?我只要重新整理,就會回到最初的起點,呆呆地站在鏡子前,又回到了同一個頁面。
那有沒有看起來很像換頁,但又不會真的換頁的方法?
有!那就是在網址後面加個 #,然後去改變後面的東西!
舉例來說,原本是 index.html,切換到列表頁就變成 index.html#list,關於我頁面就是 index.html#about,這樣不就好了嗎!
結果長這樣:
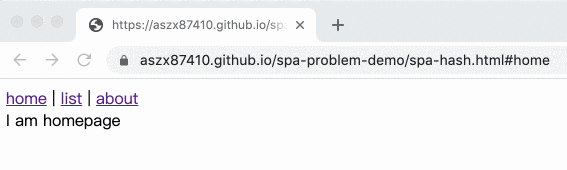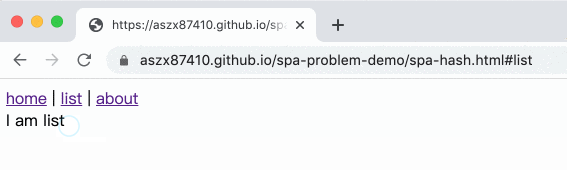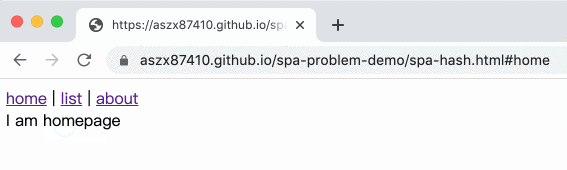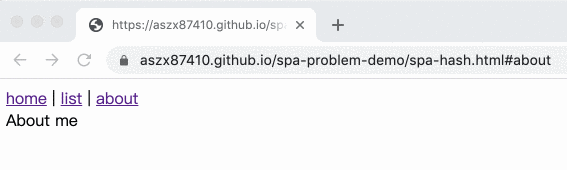
範例在這邊,底下是完整程式碼:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<style>
.page {
display: none;
}
</style>
</head>
<body>
<nav>
<a href="#home">home</a> |
<a href="#list">list</a> |
<a href="#about">about</a>
</nav>
<div class="page home-page">I am homepage</div>
<div class="page list-page">I am list</div>
<div class="page about-page">About me </div>
</body>
<script src="https://code.jquery.com/jquery-1.12.4.min.js"></script>
<script>
function changePage(hash) {
$('.page').hide()
if (hash === '#home') {
$('.home-page').show()
} else if (hash === '#list') {
$('.list-page').show()
} else if (hash === '#about') {
$('.about-page').show()
}
}
// 初始化
changePage(location.hash)
// 每當 hash 變動的時候
window.addEventListener("hashchange", function() {
changePage(location.hash)
});
</script>
</html>利用網址後面加上 # 不會跳頁的方式來辨別現在在哪裡,這就是 react-router 裡面提到的 hashRouter。
可是這樣子網址會變得很醜,而且跟其他人的網址都不一樣,會有 hashtag 出現。有沒有什麼辦法讓 hashtag 不見呢?
有!那就是利用 HTML5 提供的 History API,就可以用 JavaScript 來操作網址列,但又不會真的換頁了。
在 MDN 下方「pushState() 方法範例」的段落是這樣寫的:
假設 http://mozilla.org/foo.html 執行了下面的 JavaScript:
var stateObj = { foo: “bar” };
history.pushState(stateObj, “page 2”, “bar.html”);
這會讓網址列顯示 http://mozilla.org/bar.html,但不會讓瀏覽器去載入 bar.html,甚或去檢查 bar.html 存在與否。
重點來了,就是這一句:「但不會讓瀏覽器去載入 bar.html」,就算網址列有變,只要瀏覽器沒有去載入其他頁面,其實就不叫「換頁」。所以 SPA 從來都不是指說「網址列不能變」,而是不能去載入其他頁面,這點一定要搞清楚。
範例如下:
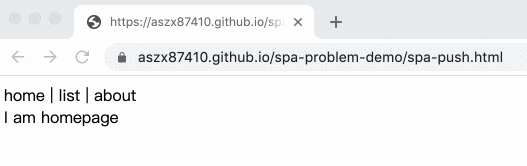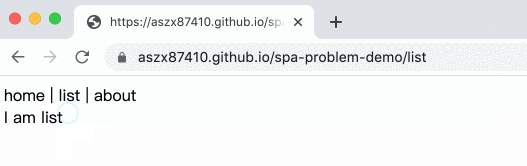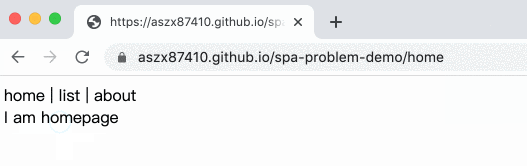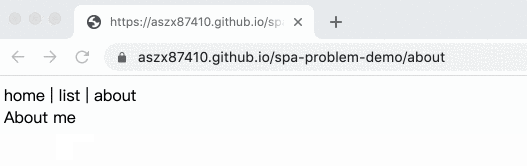
完整程式碼在這邊:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<style>
.page {
display: none;
}
.home-page {
display: block;
}
</style>
</head>
<body>
<nav>
<span onclick="changePage('home')">home</span> |
<span onclick="changePage('list')">list</span> |
<span onclick="changePage('about')">about</span>
</nav>
<div class="page home-page">I am homepage</div>
<div class="page list-page">I am list</div>
<div class="page about-page">About me </div>
</body>
<script src="https://code.jquery.com/jquery-1.12.4.min.js"></script>
<script>
function changePage(page) {
$('.page').hide()
if (page === 'home') {
$('.home-page').show()
} else if (page === 'list') {
$('.list-page').show()
} else if (page === 'about') {
$('.about-page').show()
}
// 精華所在
history.pushState(null, null, page)
}
</script>
</html>在換頁的時候利用 pushState 去改變網址,於是網址就變了,但卻不會真的去載入那個新的頁面,根本就是完美!
補齊了這些知識之後,我們終於可以來回答第一個問題了。當我們在實作 SPA 時,在前端的換頁使用了 pushState,讓我們利用 JavaScript 來更新網址列卻不會真的載入那個資源。
可是如果我們重新整理呢?那意思就變成是要直接去載入那個資源啊!然後伺服器又沒有那個檔案,所以當然會回傳 404 not found。之所以從首頁進去會可以,是因為從首頁到列表頁,我們只是用 pushState 去改變網址,從 / 改成 /list。
但如果我們直接在 /list 重新整理,就代表瀏覽器會發送 Request 去 /list 要資料,自然就會回傳 404 not found。
那要怎麼解決這個問題呢?在 GitHub Pages 上面可以設定一個自訂的 404 page,你可以把這個 404 page 就設置成是你的 index.html,這樣無論網址是什麼,都會回傳 index.html。
我這邊上傳了一個小小的 demo,程式碼在這邊:https://github.com/aszx87410/spa-problem-demo,其實就是直接把 index.html 的內容複製到 404.html 去而已。
或是也可以參考這個:rafrex/spa-github-pages,採用了不同的方法。
如果是用 nginx 的話,只要讓所有路徑都試試看 index.html 就好:
location / {
try_files $uri /index.html;
}Apache 可以參考網路上找到的設定:SPA - Apache, Nginx Configuration for Single Page Application like React.js on a custom path,原理也是把所有路徑都導到 index.html 去。
總結
我自己一開始在接觸這個部分時也是一頭霧水,花了滿多時間去理解到底前後端的 Router 差別在哪裡,發現需要具備一些基礎知識才有辦法解決這個問題。如果你不知道前端 Router 背後是用 History API 實現,自然就會覺得莫名其妙。
而且初學者來說,所有的問題都打結糾纏在一起,很難一條一條去拆開,自然就找不到問題的解答。
希望這一篇能對初學者有些幫助,能確切理解前端 SPA 指的「不換頁」到底是什麼意思,以及背後是透過什麼原理而實現的。
評論